
Friends,
In this post I am gonna add stuff related to Interview questions from SQL SERVER with answers. Hope this one will help you in cracking the Interviews on SQL SERVER.
- What are Constraints or Define Constraints ?
Generally we use Data Types to limit the kind of Data in a Column. For example, if we declare any column with data type INT then ONLY Integer data can be inserted into the column. Constraint will help us to limit the Values we are passing into a column or a table. In simple Constraints are nothing but Rules or Conditions applied on columns or tables to restrict the data.
- Different types of Constraints ?
There are THREE Types of Constraints.
- Domain
- Entity
- Referential
Domain has the following constraints types –
- Not Null
- Check
Entity has the following constraint types –
- Primary Key
- Unique Key
Referential has the following constraint types –
- Foreign Key
- What is the difference between Primary Key and Unique Key ?
- By default PK defines Clustered Index in the column where as UK defines Non Clustered Index.
- PK doesn’t allow NULL Value where as UK allow ONLY ONE NULL.
- You can have only one PK per table where as UK can be more than one per table.
- PK can be used in Foreign Key relationships where as UK cannot be used.
- What is the difference between Delete and Truncate ?
- Truncate is Faster where as Delete is Slow process.
- Truncate doesn’t log where as Delete logs an entry for every record deleted in Transaction Log.
- We can rollback the Deleted data where as Truncated data cannot be rolled back.
- Truncate resets the Identity column where as Delete doesn’t.
- We can have WHERE Clause for delete where as for Truncate we cannot have WHERE Clause.
- Delete Activates TRIGGER where as TRUNCATE Cannot.
- Truncate is a DDL statement where as Delete is DML statement.
- What are Indexes or Indices ?
- Types of Indices in SQL ?
- Clustered
- Non Clustered
- How many Clustered and Non Clustered Indexes can be defined for a table ?
Clustered – 1
Non Clustered – 999
- What is Transaction in SQL Server ?
- Types of Transactions ?
- Implicit – Specifies any Single Insert,Update or Delete statement as Transaction Unit. No need to specify Explicitly.
- Explicit – A group of T-Sql statements with the beginning and ending marked with Begin Transaction,Commit and RollBack. PFB an Example for Explicit transactions.
BEGIN TRANSACTION
Update Employee Set Emp_ID = 54321 where Emp_ID = 12345
If(@@Error <>0)
ROLLBACK
Update LEave_Details Set Emp_ID = 54321 where Emp_ID = 12345
If(@@Error <>0)
ROLLBACK
COMMIT
In the above example we are trying to update an EMPLOYEE ID from 12345 to 54321 in both the master table “Employee” and Transaction table “Leave_Details”. In this case either BOTH the tables will be updated with new EMPID or NONE.
- What is the Max size and Max number of columns for a row in a table ?
- What is Normalization and Explain different normal forms.
Database normalization is a process of data design and organization which applies to data structures based on rules that help building relational databases.
1. Organizing data to minimize redundancy.
2. Isolate data so that additions, deletions, and modifications of a field can be made in just one table and then propagated through the rest of the database via the defined relationships.
1NF: Eliminate Repeating Groups
Each set of related attributes should be in separate table, and give each table a primary key. Each field contains at most one value from its attribute domain.
2NF: Eliminate Redundant Data
1. Table must be in 1NF.
2. All fields are dependent on the whole of the primary key, or a relation is in 2NF if it is in 1NF and every non-key attribute is fully dependent on each candidate key of the relation. If an attribute depends on only part of a multi‐valued key, remove it to a separate table.
3NF: Eliminate Columns Not Dependent On Key
1. The table must be in 2NF.
2. Transitive dependencies must be eliminated. All attributes must rely only on the primary key. If attributes do not contribute to a description of the key, remove them to a separate table. All attributes must be directly dependent on the primary key.
BCNF: Boyce‐Codd Normal Form
for every one of its non-trivial functional dependencies X → Y, X is a superkey—that is, X is either a candidate key or a superset thereof. If there are non‐trivial dependencies between candidate key attributes, separate them out into distinct tables.
4NF: Isolate Independent Multiple Relationships
No table may contain two or more 1:n or n:m relationships that are not directly related.
For example, if you can have two phone numbers values and two email address values, then you should not have them in the same table.
5NF: Isolate Semantically Related Multiple Relationships
A 4NF table is said to be in the 5NF if and only if every join dependency in it is implied by the candidate keys. There may be practical constrains on information that justify separating logically related many‐to‐many relationships.
- What is Denormalization ?
For optimizing the performance of a database by adding redundant data or by grouping data is called de-normalization.
It is sometimes necessary because current DBMSs implement the relational model poorly.
In some cases, de-normalization helps cover up the inefficiencies inherent in relational database software. A relational normalized database imposes a heavy access load over physical storage of data even if it is well tuned for high performance.
A true relational DBMS would allow for a fully normalized database at the logical level, while providing physical storage of data that is tuned for high performance. De‐normalization is a technique to move from higher to lower normal forms of database modeling in order to speed up database access.
- Query to Pull ONLY duplicate records from table ?
There are many ways of doing the same and let me explain one here. We can acheive this by using the keywords GROUP and HAVING. The following query will extract duplicate records from a specific column of a particular table.
Select specificColumn
FROM particluarTable
GROUP BY specificColumn
HAVING COUNT(*) > 1
This will list all the records that are repeated in the column specified by “specificColumn” of a “particlarTable”.
- Types of Joins in SQL SERVER ?
- Inner Join
- Outer Join
- Cross Join
- Right Outer Join
- Left Outer Join
- Full Outer Join.
- What is Table Expressions in Sql Server ?
- Derived tables
- Common Table Expressions.
- What is Derived Table ?
- What is CTE or Common Table Expression ?
- Recursive
- Non Recursive
- Difference between SmallDateTime and DateTime datatypes in Sql server ?
- DateTime occupies 4 Bytes of data where as SmallDateTime occupies only 2 Bytes.
- DateTime ranges from 01/01/1753 to 12/31/9999 where as SmallDateTime ranges from 01/01/1900 to 06/06/2079.
- What is SQL_VARIANT Datatype ?
The SQL_VARIANT data type can be used to store values of various data types at the same time, such as numeric values, strings, and date values. (The only types of values that cannot be stored are TIMESTAMP values.) Each value of an SQL_VARIANT column has two parts: the data value and the information that describes the value. (This information contains all properties of the actual data type of the value, such as length, scale, and precision.)
- What is Temporary table ?
A temporary table is a database object that is temporarily stored and managed by the database system. There are two types of Temp tables.
- Local
- Global
- What are the differences between Local Temp table and Global Temp table ?
- Both are stored in tempdb database.
- Both will be cleared once the connection,which is used to create the table, is closed.
- Both are meant to store data temporarily.
- Local temp table is prefixed with # where as Global temp table with ##.
- Local temp table is valid for the current connection i.e the connection where it is created where as Global temp table is valid for all the connection.
- Local temp table cannot be shared between multiple users where as Global temp table can be shared.
- Whar are the differences between Temp table and Table variable ?
- Table variables are Transaction neutral where as Temp tables are Transaction bound. For example if we declare and load data into a temp table and table variable in a transaction and if the transaction is ROLLEDBACK, still the table variable will have the data loaded where as Temp table will not be available as the transaction is rolled back.
- Temporary Tables are real tables so you can do things like CREATE INDEXes, etc. If you have large amounts of data for which accessing by index will be faster then temporary tables are a good option.
- Table variables don’t participate in transactions, logging or locking. This means they’re faster as they don’t require the overhead.
- You can create a temp table using SELECT INTO, which can be quicker to write (good for ad-hoc querying) and may allow you to deal with changing datatypes over time, since you don’t need to define your temp table structure upfront.
- What is the difference between Char,Varchar and nVarchar datatypes ?
char[(n)] – Fixed-length non-Unicode character data with length of n bytes. n must be a value from 1 through 8,000. Storage size is n bytes. The SQL-92 synonym for char is character.
varchar[(n)] – Variable-length non-Unicode character data with length of n bytes. n must be a value from 1 through 8,000. Storage size is the actual length in bytes of the data entered, not n bytes. The data entered can be 0 characters in length. The SQL-92 synonyms for varchar are char varying or character varying.
nvarchar(n) – Variable-length Unicode character data of n characters. n must be a value from 1 through 4,000. Storage size, in bytes, is two times the number of characters entered. The data entered can be 0 characters in length. The SQL-92 synonyms for nvarchar are national char varying and national character varying.
- What is the difference between STUFF and REPLACE functions in Sql server ?
- What are Magic Tables ?
The deleted table contains all records that have been deleted from deleted from the trigger table.
Whenever any updation takes place, the trigger uses both the inserted and deleted tables.
- Explain about RANK,ROW_NUMBER and DENSE_RANK in Sql server ?
Found a very interesting explanation for the same in the url Click Here . PFB the content of the same here.
Lets take 1 simple example to understand the difference between 3.
First lets create some sample data :
— create table
CREATE TABLE Salaries
(
Names VARCHAR(1),
SalarY INT
)
GO
— insert data
INSERT INTO Salaries SELECT
‘A’,5000 UNION ALL SELECT
‘B’,5000 UNION ALL SELECT
‘C’,3000 UNION ALL SELECT
‘D’,4000 UNION ALL SELECT
‘E’,6000 UNION ALL SELECT
‘F’,10000
GO
— Test the data
SELECT Names, Salary
FROM Salaries
Now lets query the table to get the salaries of all employees with their salary in descending order.
For that I’ll write a query like this :
SELECT names
, salary
,row_number () OVER (ORDER BY salary DESC) as ROW_NUMBER
,rank () OVER (ORDER BY salary DESC) as RANK
,dense_rank () OVER (ORDER BY salary DESC) as DENSE_RANK
FROM salaries
>>Output
| NAMES | SALARY | ROW_NUMBER | RANK | DENSE_RANK |
| F | 10000 | 1 | 1 | 1 |
| E | 6000 | 2 | 2 | 2 |
| A | 5000 | 3 | 3 | 3 |
| B | 5000 | 4 | 3 | 3 |
| D | 4000 | 5 | 5 | 4 |
| C | 3000 | 6 | 6 | 5 |
Interesting Names in the result are employee A, B and D. Row_number assign different number to them. Rank and Dense_rank both assign same rank to A and B. But interesting thing is what RANK and DENSE_RANK assign to next row? Rank assign 5 to the next row, while dense_rank assign 4.
The numbers returned by the DENSE_RANK function do not have gaps and always have consecutive ranks. The RANK function does not always return consecutive integers. The ORDER BY clause determines the sequence in which the rows are assigned their unique ROW_NUMBER within a specified partition.
So question is which one to use?
Its all depends on your requirement and business rule you are following.
1. Row_number to be used only when you just want to have serial number on result set. It is not as intelligent as RANK and DENSE_RANK.
2. Choice between RANK and DENSE_RANK depends on business rule you are following. Rank leaves the gaps between number when it sees common values in 2 or more rows. DENSE_RANK don’t leave any gaps between ranks.
So while assigning the next rank to the row RANK will consider the total count of rows before that row and DESNE_RANK will just give next rank according to the value.
So If you are selecting employee’s rank according to their salaries you should be using DENSE_RANK and if you are ranking students according to there marks you should be using RANK(Though it is not mandatory, depends on your requirement.)
- What are the differences between WHERE and HAVING clauses in SQl Server ?
2.Where applies to each and single row and Having applies to summarized rows (summarized with GROUP BY).
3.In Where clause the data that fetched from memory according to condition and In having the completed data firstly fetched and then separated according to condition.
4.Where is used before GROUP BY clause and HAVING clause is used to impose condition on GROUP Function and is used after GROUP BY clause in the query.
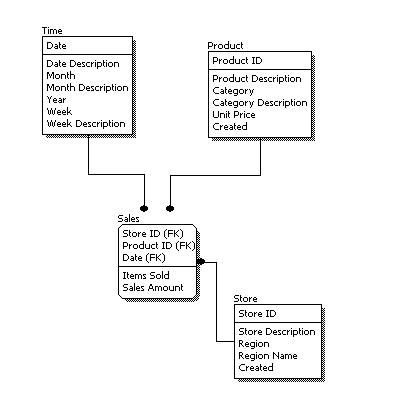
- Explain Physical Data Model or PDM ?
Physical data model represents how the model will be built in the database. A physical database model shows all table structures, including column name, column data type, column constraints, primary key, foreign key, and relationships between tables. Features of a physical data model include:
- Specification all tables and columns.
- Foreign keys are used to identify relationships between tables.
- Specying Data types.
EG –

Reference from Here
- Explain Logical Data Model ?
A logical data model describes the data in as much detail as possible, without regard to how they will be physical implemented in the database. Features of a logical data model include:
- Includes all entities and relationships among them.
- All attributes for each entity are specified.
- The primary key for each entity is specified.
- Foreign keys (keys identifying the relationship between different entities) are specified.
- Normalization occurs at this level.
Reference from Here
- Explain Conceptual Data Model ?
A conceptual data model identifies the highest-level relationships between the different entities. Features of conceptual data model include:
- Includes the important entities and the relationships among them.
- No attribute is specified.
- No primary key is specified.
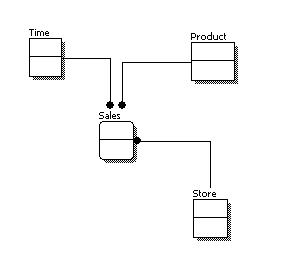
Reference from Here
- What is Log Shipping ?
Log Shipping is a basic level SQL Server high-availability technology that is part of SQL Server. It is an automated backup/restore process that allows you to create another copy of your database for failover.
Log shipping involves copying a database backup and subsequent transaction log backups from the primary (source) server and restoring the database and transaction log backups on one or more secondary (Stand By / Destination) servers. The Target Database is in a standby or no-recovery mode on the secondary server(s) which allows subsequent transaction logs to be backed up on the primary and shipped (or copied) to the secondary servers and then applied (restored) there.
- What are the advantages of database normalization ?
Benefits of normalizing the database are
- No need to restructure existing tables for new data.
- Reducing repetitive entries.
- Reducing required storage space
- Increased speed and flexibility of queries.
- What are Linked Servers ?
Linked servers are configured to enable the Database Engine to execute a Transact-SQL statement that includes tables in another instance of SQL Server, or another database product such as Oracle. Many types OLE DB data sources can be configured as linked servers, including Microsoft Access and Excel. Linked servers offer the following advantages:
- The ability to access data from outside of SQL Server.
- The ability to issue distributed queries, updates, commands, and transactions on heterogeneous data sources across the enterprise.
- The ability to address diverse data sources similarly.
- Can connect to MOLAP databases too.
- What is the Difference between the functions COUNT and COUNT_BIG ?
- Count returns INT datatype value where as Count_Big returns BIGINT datatype value.
- Count is used if the rows in a table are less where as Count_Big will be used when the numbenr of records are in millions or above.
Syntax –
- Count – Select count(*) from tablename
- Count_Big – Select Count_Big(*) from tablename
- How to insert values EXPLICITLY to an Identity Column ?
Msg 544, Level 16, State 1, Line 3 Cannot insert explicit value for identity column in table 'tablename' when IDENTITY_INSERT is set to OFF.
- How to RENAME a table and column in SQL ?
- How to rename a database ?
USE master; GO ALTER DATABASE databasename Modify Name = newname ; GO
- What is the use the UPDATE_STATISTICS command ?
- How to read the last record from a table with Identity Column ?
FROM TABLE
WHERE ID = IDENT_CURRENT(‘TABLE’)
FROM TABLE
WHERE ID = (SELECT MAX(ID) FROM TABLE)
- What is Worktable ?
A worktable is a temporary table used internally by SQL Server to process the intermediate results of a query. Worktables are created in the tempdb database and are dropped automatically after query execution. Thease table cannot be seen as these are created while a query executing and dropped immediately after the execution of the query.
- What is HEAP table ?
A table with NO CLUSTERED INDEXES is called as HEAP table. The data rows of a heap table are not stored in any particular order or linked to the adjacent pages in the table. This unorganized structure of the heap table usually increases the overhead of accessing a large heap table, when compared to accessing a large nonheap table (a table with clustered index). So, prefer not to go with HEAP tables .. 🙂
- What is ROW LOCATOR ?
If you define a NON CLUSTERED index on a table then the index row of a nonclustered index contains a pointer to the corresponding data row of the table. This pointer is called a row locator. The value of the row locator depends on whether the data pages are stored in a heap or are clustered. For a nonclustered index, the row locator is a pointer to the data row. For a table with a clustered index, the row locator is the clustered index key value.
- What is Covering Index ?
A covering index is a nonclustered index built upon all the columns required to satisfy a SQL query without going to the base table. If a query encounters an index and does not need to refer to the underlying data table at all, then the index can be considered a covering index. For Example
Select col1,col2 from table
where col3 = Value
group by col4
order by col5
Now if you create a clustered index for all the columns used in Select statement then the SQL doesn’t need to go to base tables as everything required are available in index pages.
- What is Indexed View ?
- What is Bookmark Lookup ?
When a SQL query requests a small number of rows, the optimizer can use the nonclustered index, if available, on the column(s) in the WHERE clause to retrieve the data. If the query refers to columns that are not part of the nonclustered index used to retrieve the data, then navigation is required from the index row to the corresponding data row in the table to access these columns.This operation is called a bookmark lookup.
Как выбрать черный плинтус для вашего интерьера, Плюсы и минусы черного плинтуса, С чем сочетать черный плинтус: стильные комбинации, Секреты ухода за черным плинтусом, Черный плинтус: детали, на которые стоит обратить внимание, Зачем выбирать черный плинтус для интерьера, Интересные варианты применения черного плинтуса в интерьере, Материалы для черного плинтуса: варианты выбора, Стильные комбинации черного плинтуса с другими элементами декора, Как использовать черный плинтус для создания атмосферы, Почему черный плинтус становится все популярнее, Черный плинтус как элемент роскоши в интерьере, Как черный плинтус меняет общий вид помещения, Черный плинтус на стенах: стройность и элегантность, Черный плинтус в кухонном дизайне: советы по выбору, Чем привлекательны черные оттенки в спальном интерьере, Идеи использования черного плинтуса в гостиной, Черный плинтус: шикарный акцент в ванной комнате, Идеи декорирования с помощью черного плинтуса
черный плинтус https://plintus-aljuminievyj-chernyj.ru/ .
Роман Василенко: в 2020 году выйдем на покупку 100 квартир в месяц
ЖК Бествей
В конце декабря в Москве по инициативе депутатов Государственной думы Сергея Крючка и Олега Нилова прошел круглый стол о перспективах жилищной кооперации для решения жилищной проблемы в России. Большой интерес вызвала модель жилищных кооперативов, обходящегося без государственной поддержки и подразумевающая покупку только готового, а не строящегося жилья.
Депутат Государственной думы Олег Нилов подчеркнул, что кооперативы существовали еще в советские времена, это позитивный опыт, который нуждается в государственной поддержке — ведь это способ беспроцентной покупки объектов недвижимости вскладчину. — Опыт Германии свидетельствует о том, что он очень эффективен, — заявил депутат Государственной думы Сергей Крючек, — Там очень большой объем жилья приобретается за счет кооперативного финансирования, а не ипотеки. Это альтернативный источник финансирования решения жилищного вопроса.
Присутствовавший на круглом столе практик жилищной кооперации — председатель правления жилищного кооператива “Бест Вей” Роман Василенко подчеркнул, что возглавляемый им кооператив как раз является примером решения квартирного вопроса без государственного финансирования и при этом с минимальной переплатой.
— Квартира, приобретенная кооперативом, обойдется существенно дешевле ипотечной. Переплата, связана с внесением вступительного и членских взносов, по наиболее типичным квартирам — стоимостью 3,5-4 млн рублей, составит примерно 10-15%.
По его словам, жилищная кооперация в России имеет давнюю историю. Дореволюционная Россия была первой в мире по числу кооперативов в мире. Жилищные кооперативы были распространены и в советское время. В пореформенный период был избран американской путь — акцент на ипотеку. Но он себя не оправдал — так как ипотеку получить довольно тяжело и число нуждающихся в качественном жилье сокращается медленно.
Кооперативное же финансирование получить, наоборот, легко. Нет таких требований, как хорошая кредитная история, не требуется подтвержденный доход.
Что касается возрастных ограничений, то пайщику должно исполниться 16 лет, верхних ограничений для вступления в кооператив нет. Залоговой частью выступает сама квартира: пока пайщик полностью не рассчитается с кооперативом, она находится в собственности кооператива, то есть в собственности всех пайщиков. Как только пайщик рассчитался с кооперативом, он получает право регистрации перехода права собственности на квартиру.
— В развитии жилищных кооперативов нужно правильно расставить акценты: выбрать форму, нуждающуюся в приоритетной поддержке. Есть жилищно-строительные кооперативы — это как раз случай Су-155. И есть жилищные кооперативы. Нет рисков, характерных, например, для ЖСК — рисков того, что ликвидный объект недвижимости, гарантирующий выплату пая пайщику, который примет решение выйти из кооператива, не будет создан — потому что дом по тем или иным причинам не будет достроен.
ЖК, сказал Василенко, покупают только готовые квартиры — на первичном или вторичном рынке, с зарегистрированным правом собственности, причем, квартиры, прошедшие тщательную юридическую проверку и независимую оценку рыночной стоимости. Это наиболее безопасное вложение. Достоинство ЖК, по словам Василенко, в том, что они не привлекают кредиты и не нуждаются в госфинансировании. Они способны решить проблему доступного жилья. У них одна-единственная задача — приобретение квартир для пайщиков, — заметил Василенко, — Они не имеют права привлекать заемные средства.
sollers atlant фургон https://sollers-avto.ru
Как поднять настроение с помошью мемов. ржачные анекдоты
http://azclan.ru/forums/users/vychislavyakov
Как поднять настроение с помошью смешных картинок. ржачные мемы
https://pipeclub.net/index.php?/user/114591-vychislavyakov/
prednisone 40 mg 50mg prednisone tablet 10 mg prednisone
info s mostbet com [url=https://mostbetlogin-kz.kz/]mostbet com[/url] слот клуб mostbet com .
Уникальные варианты аренды жилья на сутки|Забронируйте квартиру на сутки мечты|Квартиры на сутки в центре города|Удобная система бронирования квартир на сутки|Выбор апартаментов на сутки по лучшим ценам|Лучшие варианты аренды жилья на короткий срок|Привлекательные варианты аренды квартир на сутки|Выберите идеальное жилье на короткий срок|Уникальные апартаменты на сутки для вашего отдыха|Эксклюзивные предложения аренды апартаментов на сутки|Бронируйте квартиры на сутки по выгодным ценам|Находите лучшие варианты жилья и бронируйте сейчас|Эксклюзивные варианты аренды квартир на сутки|Лучшие апартаменты на сутки по доступной цене|Выбирайте комфортные апартаменты на короткий срок|Простой способ аренды жилья на сутки|Идеальные варианты жилья на сутки для вашего отдыха|Удобный поиск и бронирование апартаментов на сутки|Выбор идеальных квартир для короткого проживания|Выбор квартир на короткий срок для вашего отдыха
квартиры по суткам в гомеле квартиры по суткам в гомеле .
Кракен сайт – это онлайн-площадка, работающая в скрытых сетях интернета, где пользователи могут покупать и продавать различные виды наркотиков. Для доступа к Kraken onion необходимо использовать специальное программное обеспечение, позволяющее обходить блокировки и обеспечивающее анонимность пользователей.
wall clocks quiet loud alarm clocks
Купить бетон от производителя в Нижнем Новгороде, Широкий выбор бетонных смесей в Нижнем Новгороде, с высоким качеством, с гарантией качества, Бетонные заводы в Нижнем Новгороде: широкий выбор, Заказать крупным оптом бетон в Нижнем Новгороде, Индивидуальные бетонные решения в Нижнем Новгороде, Наилучший выбор готового бетона в Нижнем Новгороде, с доставкой
бетон м300 цена нижний новгород https://1beton-52.ru/ .
Сайт о биодобавках https://биодобавки.рф подробная информация о видах добавок, их действии и пользе. Рекомендации по выбору для поддержки здоровья на основе актуальных исследований.
Идеальные образы в тактичной одежде, тактичные куртки.
Топ-10 брендов тактичной одежды, чтобы быть в тренде.
Тактичные наряды для повседневной носки, для города и природы.
Когда лучше всего носить тактичную одежду, чтобы выглядеть стильно и уверенно.
Секреты удачного выбора тактичной одежды, для создания тенденций.
одяг тактичний одяг тактичний .
order omnicef sale – cleocin medication
сделать дубликат гос номера https://gos-nomerov.ru/
Свежие приколы http://shutki-anekdoty.ru/.
Веселые приколы, шутки и картинки http://shutki-anekdoty.ru/.
Прикольные анекдоты http://shutki-anekdoty.ru/anekdoty.
Качественные мотозапчасти для вашего мотоцикла | Найдите все необходимое для тюнинга | Лучшие решения для обслуживания вашего байка | Выбирайте только лучшие детали для своего мотоцикла | Индивидуальный подход к каждому клиенту | Доставка запчастей по всей стране | Лучшие предложения на запчасти для тюнинга | Улучшайте характеристики своего мотоцикла с новыми запчастями | Эксклюзивные предложения на мотозапчасти для мотоциклов | Доставка запчастей по всей стране | Оптимальные решения для тюнинга мотоцикла | Консультации по выбору запчастей для мотоциклов | Быстрая доставка деталей по всей стране | Найдите все необходимое для обслуживания мотоцикла | Получите скидку на следующую покупку мотозапчастей
запчасти для мотоциклов ссср https://motorcyclepartsgdra.kiev.ua/ .
Свежие и смешные мемы http://shutki-anekdoty.ru/kartinki-prikolnye.
new retro casino зеркало https://retromobil-club.ru/ .
Bạn đang tìm kiếm những trò chơi hot nhất và thú vị nhất tại sòng bạc trực tuyến? RGBET tự hào giới thiệu đến bạn nhiều trò chơi cá cược đặc sắc, bao gồm Baccarat trực tiếp, máy xèng, cá cược thể thao, xổ số và bắn cá, mang đến cho bạn cảm giác hồi hộp đỉnh cao của sòng bạc! Dù bạn yêu thích các trò chơi bài kinh điển hay những máy xèng đầy kịch tính, RGBET đều có thể đáp ứng mọi nhu cầu giải trí của bạn.
RGBET Trò Chơi của Chúng Tôi
Bạn đang tìm kiếm những trò chơi hot nhất và thú vị nhất tại sòng bạc trực tuyến? RGBET tự hào giới thiệu đến bạn nhiều trò chơi cá cược đặc sắc, bao gồm Baccarat trực tiếp, máy xèng, cá cược thể thao, xổ số và bắn cá, mang đến cảm giác hồi hộp đỉnh cao của sòng bạc! Dù bạn yêu thích các trò chơi bài kinh điển hay những máy xèng đầy kịch tính, RGBET đều có thể đáp ứng mọi nhu cầu giải trí của bạn.
RGBET Trò Chơi Đa Dạng
Thể thao: Cá cược thể thao đa dạng với nhiều môn từ bóng đá, tennis đến thể thao điện tử.
Live Casino: Trải nghiệm Baccarat, Roulette, và các trò chơi sòng bài trực tiếp với người chia bài thật.
Nổ hũ: Tham gia các trò chơi nổ hũ với tỷ lệ trúng cao và cơ hội thắng lớn.
Lô đề: Đặt cược lô đề với tỉ lệ cược hấp dẫn.
Bắn cá: Bắn cá RGBET mang đến cảm giác chân thực và hấp dẫn với đồ họa tuyệt đẹp.
RGBET – Máy Xèng Hấp Dẫn Nhất
Khám phá các máy xèng độc đáo tại RGBET với nhiều chủ đề khác nhau và tỷ lệ trả thưởng cao. Những trò chơi nổi bật bao gồm:
RGBET Super Ace
RGBET Đế Quốc Hoàng Kim
RGBET Pharaoh Treasure
RGBET Quyền Vương
RGBET Chuyên Gia Săn Rồng
RGBET Jackpot Fishing
Vì sao nên chọn RGBET?
RGBET không chỉ cung cấp hàng loạt trò chơi đa dạng mà còn mang đến một hệ thống cá cược an toàn và chuyên nghiệp, đảm bảo mọi quyền lợi của người chơi:
Tốc độ nạp tiền nhanh chóng: Chuyển khoản tại RGBET chỉ mất vài phút và tiền sẽ vào tài khoản ngay lập tức, giúp bạn không bỏ lỡ bất kỳ cơ hội nào.
Game đổi thưởng phong phú: Từ cá cược thể thao đến slot game, RGBET cung cấp đầy đủ trò chơi giúp bạn tận hưởng mọi phút giây thư giãn.
Bảo mật tuyệt đối: Với công nghệ mã hóa tiên tiến, tài khoản và tiền vốn của bạn sẽ luôn được bảo vệ một cách an toàn.
Hỗ trợ đa nền tảng: Bạn có thể chơi trên mọi thiết bị, từ máy tính, điện thoại di động (iOS/Android), đến nền tảng H5.
Tải Ứng Dụng RGBET và Nhận Khuyến Mãi Lớn
Hãy tham gia RGBET ngay hôm nay để tận hưởng thế giới giải trí không giới hạn với các trò chơi thể thao, thể thao điện tử, casino trực tuyến, xổ số, và slot game. Quét mã QR và tải ứng dụng RGBET trên điện thoại để trải nghiệm game tốt hơn và nhận nhiều khuyến mãi hấp dẫn!
Tham gia RGBET để bắt đầu cuộc hành trình cá cược đầy thú vị ngay hôm nay!
вывод из запоя круглосуточно ростов вывод из запоя круглосуточно ростов .
Наша команда специалистов готова оказать вам всю необходимую поддержку и помощь в выборе микрозайма. Мы всегда на связи и готовы ответить на любые вопросы, связанные с процессом кредитования.
микрозайм займы онлайн Казахстан .
บาคาร่า
เล่นบาคาร่าแบบรวดเร็วทันใจกับสปีดบาคาร่า
ถ้าคุณเป็นแฟนตัวยงของเกมไพ่บาคาร่า คุณอาจจะเคยชินกับการรอคอยในแต่ละรอบการเดิมพัน และรอจนดีลเลอร์แจกไพ่ในแต่ละตา แต่คุณรู้หรือไม่ว่า ตอนนี้คุณไม่ต้องรออีกต่อไปแล้ว เพราะ SA Gaming ได้พัฒนาเกมบาคาร่าโหมดใหม่ขึ้นมา เพื่อให้ประสบการณ์การเล่นของคุณน่าตื่นเต้นยิ่งขึ้น!
ที่ SA Gaming คุณสามารถเลือกเล่นไพ่บาคาร่าในโหมดที่เรียกว่า สปีดบาคาร่า (Speed Baccarat) โหมดนี้มีคุณสมบัติพิเศษและข้อดีที่น่าสนใจมากมาย:
ระยะเวลาการเดิมพันสั้นลง — คุณไม่จำเป็นต้องรอนานอีกต่อไป ในโหมดสปีดบาคาร่า คุณจะมีเวลาเพียง 12 วินาทีในการวางเดิมพัน ทำให้เกมแต่ละรอบจบได้รวดเร็ว โดยเกมในแต่ละรอบจะใช้เวลาเพียง 20 วินาทีเท่านั้น
ผลตอบแทนต่อผู้เล่นสูง (RTP) — เกมสปีดบาคาร่าให้ผลตอบแทนต่อผู้เล่นสูงถึง 4% ซึ่งเป็นมาตรฐานความเป็นธรรมที่ผู้เล่นสามารถไว้วางใจได้
การเล่นเกมที่รวดเร็วและน่าตื่นเต้น — ระยะเวลาที่สั้นลงทำให้เกมแต่ละรอบดำเนินไปอย่างรวดเร็ว ทันใจ เพิ่มความสนุกและความตื่นเต้นในการเล่น ทำให้ประสบการณ์การเล่นของคุณยิ่งสนุกมากขึ้น
กลไกและรูปแบบการเล่นยังคงเหมือนเดิม — แม้ว่าระยะเวลาจะสั้นลง แต่กลไกและกฎของการเล่น ยังคงเหมือนกับบาคาร่าสดปกติทุกประการ เพียงแค่ปรับเวลาให้เล่นได้รวดเร็วและสะดวกขึ้นเท่านั้น
นอกจากสปีดบาคาร่าแล้ว ที่ SA Gaming ยังมีโหมด No Commission Baccarat หรือบาคาร่าแบบไม่เสียค่าคอมมิชชั่น ซึ่งจะช่วยให้คุณสามารถเพลิดเพลินไปกับการเล่นได้โดยไม่ต้องกังวลเรื่องค่าคอมมิชชั่นเพิ่มเติม
เล่นบาคาร่ากับ SA Gaming คุณจะได้รับประสบการณ์การเล่นที่สนุก ทันสมัย และตรงใจมากที่สุด!
Thai farmer forced to kill more than 100 endangered crocodiles after a typhoon damaged their enclosure
kraken сайт
A Thai crocodile farmer who goes by the nickname “Crocodile X” said he killed more than 100 critically endangered reptiles to prevent them from escaping after a typhoon damaged their enclosure.
Natthapak Khumkad, 37, who runs a crocodile farm in Lamphun, northern Thailand, said he scrambled to find his Siamese crocodiles a new home when he noticed a wall securing their enclosure was at risk of collapsing. But nowhere was large or secure enough to hold the crocodiles, some of which were up to 4 meters (13 feet) long.
To stop the crocodiles from getting loose into the local community, Natthapak said, he put 125 of them down on September 22.
“I had to make the most difficult decision of my life to kill them all,” he told CNN. “My family and I discussed if the wall collapsed the damage to people’s lives would be far bigger than we can control. It would involve people’s lives and public safety.”
Typhoon Yagi, Asia’s most powerful storm this year, swept across southern China and Southeast Asia this month, leaving a trail of destruction with its intense rainfall and powerful winds. Downpours inundated Thailand’s north, submerging homes and riverside villages, killing at least nine people.
Storms like Yagi are “getting stronger due to climate change, primarily because warmer ocean waters provide more energy to fuel the storms, leading to increased wind speeds and heavier rainfall,” said Benjamin Horton, director of the Earth Observatory of Singapore.
Natural disasters, including typhoons, pose a range of threats to wildlife, according to the International Fund for Animal Welfare. Flooding can leave animals stranded, in danger of drowning, or separated from their owners or families.
Rain and strong winds can also severely damage habitats and animal shelters. In 2022, Hurricane Ian hit Florida and destroyed the Little Bear Sanctuary in Punta Gorda, leaving 200 animals, including cows, horses, donkeys, pigs and birds without shelter.
The risk of natural disasters to animals is only increasing as human-caused climate change makes extreme weather events more frequent and volatile.
Riobet
Купить диплом магистра оказалось возможно, быстрое обучение и диплом на руки
infiniterealities.listbb.ru/viewtopic.php?f=7&t=741
Как безопасно купить диплом колледжа или ПТУ в России, что важно знать
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ремонт телефонов ближайший ко мне
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ремонт кнопочных телефонов
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Выбирайте проверенное временем – Peg Perego
peg perego aria цена https://kolyaska-peg-perego.ru/ .
เอสเอ เกมมิ่ง เป็น บริษัท เกม ไพ่บาคาร่า ออนไลน์ ที่ได้รับการยอมรับอย่างกว้างขวาง ใน ระดับสากล ว่าเป็น ผู้นำ ในการให้บริการ เกม คาสิโนออนไลน์ โดยเฉพาะในด้าน เกมไพ่ บาคาร่า ซึ่งเป็น เกม ที่ นักเล่น สนใจเล่นกัน ทั่วไป ใน บ่อนคาสิโน และ ออนไลน์ ด้วย ลักษณะการเล่น ที่ ง่าย การเลือกเดิมพัน เพียง ฝ่าย ผู้เล่น หรือ ฝั่งเจ้ามือ และ เปอร์เซ็นต์การชนะ ที่ ค่อนข้างสูง ทำให้ เกมพนันบาคาร่า ได้รับ ความนิยม อย่างมากใน ช่วงหลายปีที่ผ่านมา โดยเฉพาะใน บ้านเรา
หนึ่งในสไตล์การเล่น ยอดนิยมที่ เอสเอ เกมมิ่ง แนะนำ คือ สปีดบาคาร่า ซึ่ง ให้โอกาสผู้เล่นที่ ต้องการ การเล่นเร็ว และ การคิดไว สามารถ แทงได้รวดเร็ว นอกจากนี้ยังมีโหมด ไม่มีค่าคอมมิชชั่น ซึ่งเป็น โหมด ที่ ไม่ต้องเสียค่าคอมมิชชั่นเพิ่มเติม เมื่อชนะ การเดิมพัน ฝั่งแบงค์เกอร์ ทำให้ ฟีเจอร์นี้ ได้รับ ความคุ้มค่า จาก ผู้เล่น ที่มองหา ผลประโยชน์ ในการ เดิมพัน
เกมไพ่บาคาร่า ของ เอสเอ เกมมิ่ง ยัง ได้รับการพัฒนา ให้มี ภาพ พร้อมกับ ระบบเสียง ที่ เสมือนจริง จำลองบรรยากาศ ที่ น่าสนุก เสมือนอยู่ใน คาสิโนจริง พร้อมกับ ตัวเลือก ที่ทำให้ ผู้เสี่ยงโชค สามารถเลือก วิธีการเดิมพัน ที่ มีให้เลือกมากมาย ไม่ว่าจะเป็น การลงเงิน ตามสูตร ของตน หรือการ พึ่งกลยุทธ์ ให้ชนะ นอกจากนี้ยังมี ดีลเลอร์ไลฟ์ ที่ คอยดำเนินเกม ในแต่ละ สถานที่ ทำให้ เกม มี ความน่าสนุก มากยิ่งขึ้น
ด้วย ความยืดหยุ่น ใน การแทง และ ความง่าย ในการ เล่น SA Gaming ได้ สร้างสรรค์ เกมเสี่ยงโชค ที่ เหมาะสมกับ ทุก กลุ่ม ของนักเสี่ยงโชค ตั้งแต่ ผู้ที่เริ่มต้น ไปจนถึง นักเดิมพัน มืออาชีพ
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ремонт телефона москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ремонт телефонов в москве адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
вывод из запоя в сочи вывод из запоя в сочи .
обратные ссылки купить
Смешные анекдоты http://shutki-anekdoty.ru/anekdoty.
KRAKEN – ссылка, зеркало, сайт, кракен магазин
Первоклассное качество и неповторимый стиль, коннелюрный плинтус сделает ваш интерьер неповторимым
коннелюрный плинтус для линолеума https://konnelyurnyj-plintus-dlya-linoleuma-msk.ru/ .
1 win casino game
1win aviator
Веселые мемы http://shutki-anekdoty.ru/kartinki-prikolnye.
KRAKEN – ссылка, зеркало, сайт,
KRAKEN – ссылка, зеркало, сайт, кракен зеркало
KRAKEN – ссылка, зеркало, сайт, кракен тор
https://compters.ru/
KRAKEN – ссылка, зеркало, сайт, кракен зеркала
continue reading this https://mandiribaru.co.id/flugsvamp-4-0-the-swedish-giant-5-2.html
Веселые приколы, шутки и картинки http://shutki-anekdoty.ru.
Сервисный центр предлагает ремонт затвора fujifilm finepix jx700 ремонт платы fujifilm finepix jx700
KRAKEN – ссылка, зеркало, сайт, кракен сайт
Временная регистрация в Москве: Быстро и Легально!
Ищете, где оформить временную регистрацию в Москве? Мы гарантируем быстрое и легальное оформление без очередей и лишних документов. Ваше спокойствие – наша забота!
Минимум усилий • Максимум удобства • Полная легальность
Свяжитесь с нами прямо сейчас!
.
Смешные видео https://sites.google.com/view/smeshnye-video/%D0%B3%D0%BB%D0%B0%D0%B2%D0%BD%D0%B0%D1%8F-%D1%81%D1%82%D1%80%D0%B0%D0%BD%D0%B8%D1%86%D0%B0.
Свежие приколы и анекдоты http://shutki-anekdoty.ru.
Прикольные видео https://sites.google.com/view/smeshnye-video/%D0%B3%D0%BB%D0%B0%D0%B2%D0%BD%D0%B0%D1%8F-%D1%81%D1%82%D1%80%D0%B0%D0%BD%D0%B8%D1%86%D0%B0.
KRAKEN – ссылка, зеркало, сайт, кракен магазин
KRAKEN – ссылка, зеркало, сайт, kra11.cc
KRAKEN – ссылка, зеркало, сайт, кракен зеркала
Сайт приколов https://www.dermandar.com/user/billybons собрание лучших мемов, шуток и смешных видео, чтобы ваш день был ярче. Ежедневное обновление контента для вашего настроения. Легко находите и делитесь забавными моментами с друзьями.
Прикольные анекдоты http://shutki-anekdoty.ru/anekdoty
KRAKEN – ссылка, зеркало, сайт, кракен ссылка
как распечатать кассовый чек с почты
KRAKEN – ссылка, зеркало, сайт, кракен ссылка тор
Основные моменты Istanbul International Airport, успешные этапы развития.
Загадки и тайны Istanbul International Airport, о которых мало кто слышал.
Особенности проектирования аэропорта, которые невозможно не отметить.
Будущее Istanbul International Airport, направления роста и совершенствования.
Сервисы и удобства Istanbul International Airport, какие услуги понравятся каждому.
istanbul airport facilities istanbul airport facilities .
KRAKEN – ссылка, зеркало, сайт, кракен клирнет
авансовая оплата кассовый чек
вывод из запоя люберцы вывод из запоя люберцы .
KRAKEN – ссылка, зеркало, сайт, кракен войти
Уборка квартир после пожара цены https://spec-uborka-posle-pozhara.ru/
KRAKEN – ссылка, зеркало, сайт, кракен зеркало даркнет
Сервисный центр предлагает ремонт ginzzu gt-1020 ремонт ginzzu gt-1020 в петербурге
1win bet mocambique
Короткие цитаты о смысле жизни. Цитаты известных людей.
на почту приходит кассовый чек
капельница от похмелья на дому цена капельница от похмелья на дому цена .
запой кодирование запой кодирование .
watch instagram stories watch instagram stories .
Окунитесь на мир отдыха (а) также увлекательных 3 сверху портале Эрот 28!
любовь
artmax artmax .
Тут можно преобрести оружейный сейф в москве сейф для оружия ружья
вывод из запоя цены ростов http://www.www.bisound.com/forum/showthread.php?p=1217039/ .
Тут можно преобрести сейф огнестойкий сейф огнестойкий купить
vavada promo
Тут можно преобрести сейф купить для ружья сейф купить для ружья
Готов услышать трек, который выбьет из тебя все оправдания? Слушай, если не боишься правды.
Как избежать рисков при покупке диплома колледжа или ПТУ в России
Тут можно преобрести цена сейфа для оружия сейф оружейный
Ляхоимство Как устроена система по захвату кооператива «Бест Вей» Фигура умолчания Приморским районным судом Санкт-Петербурга рассматривается уголовное дело, связываемое следствием с компаниями «Лайф-из-Гуд», «Гермес» и кооперативом «Бест Вей», параллельно судами Санкт-Петербурга рассматривается дело о законности кооператива «Бест Вей» – оба разбирательства очень далеки от завершения. Хейтерские ресурсы (телеграм-канал и сайт в иностранном сегменте интернета), обслуживающие нападки на «Лайф-из-Гуд», «Гермес» и «Бест Вей», отвечают на абсолютно все публикации защитников кооператива, причем в реальном времени, с использованием данных, к которым имеют доступ только суды и правоохранительные органы, часто подправляемых. Но удивительным образом они «не видят» ни одной статьи, где упоминается имя Валерия Ляха, нового главы Федерального (общественно-государственного) фонда по защите прав вкладчиков и акционеров, бывшего главы Департамента противодействия недобросовестным практикам ЦБ, бежавшего из России с началом СВО. Тогда же уволенного из ЦБ с последующей ликвидацией этого одиозного департамента, многократно обвинявшегося в заказных включениях в предупредительный список ЦБ из-за мифических признаков пирамиды или незаконного кредитования. Хейтерские ресурсы, как показало адвокатское расследование, зарегистрированы за рубежом, и при этом у них есть полный доступ ко всему комплексу следственных и оперативных материалов, имеющим в России статус закрытой информации. Причем публикуют их прямо из российского первоисточника и с персональными данными – рупор захватчиков не обременяет себя необходимостью соблюдать закон. Фонд по защите вкладчиков и акционеров – левая организация, созданная в 1990-е годы с помощью одного из ураганивших тогда в России олигархов и либералов, просочившихся в кабинет к алкоголику Ельцину и давших ему подписать соответствующий указ. Он называется общественно-государственным – но давно уже не государственный, давно лишен государственного финансирования. Фонд финансируется за счет активов структур, которые переданы ему в управление. Уставная цель – управлять активами ликвидированных организаций, расплачиваясь с их пайщиками и вкладчиками. Зачем он вообще нужен, учитывая, что есть Агентство по страхованию вкладов – государственная корпорация, созданная ровно для тех же целей, охватывающая все финансовые сектора, при этом деятельность которой регулируется законом, а не мутными инструкциями, логически необъяснимо. Фонд не регулируется никакими законами, он сам решает, сколько платить – и выплачивает всем вкладчикам и акционерам попавших в его жернова организаций по 35 тыс. рублей (чуть больше ветеранам Великой Отечественной войны). Кто платит? Фонд еще под руководством Сафиуллина не скрываясь участвовал в атаке на кооператив «Бест Вей» – публикуя некие статьи на своем портале, при этом не имея лицензии СМИ. Но на каком-то этапе публикаторство прерывается – и начинается в специальном телеграм-канале, якобы созданном некими неравнодушными людьми. Заработал также сайт для публикации данных – вне зоны ру, то есть вне зоны контроля соблюдения законодательства о персональных данных со стороны Роскомнадзора. Ресурсы функционируют 24/7, в их рамках действует юридическая служба во главе неким Зинченко. Все это требует немалого бюджета. При всей кровной заинтересованности в захвате кооператива «Бест Вей» явно не полицейские оплачивают этот банкет. Редакция располагает достоверной информацией, что именно фонд финансирует хейтерские ресурсы и юридическую команду Зинченко. Главный заказчик С приходом Ляха их деятельность существенно активизировалась. Оно и понятно: Лях стоял за атакой на кооператив с самого начала и с самого начала планировал поживиться его активами. Ведь именно он личным решением включил кооператив в предупредительный список ЦБ – протокольного коллегиального решения, как выяснилось, просто нет. Лях использовал Фонд по защите вкладчиков и акционеров как подконтрольную структуру – но началась СВО, и пришлось увольняться из ЦБ, бежать из России, чтобы не подпасть под санкции. А потом «трудоустраиваться» уже в сам фонд. Остается только удивляться, что Прокуратура Санкт-Петербурга оказалось аффилированной с предателем Родины. Лях пытается через свои связи в прокуратуре и суде добиться незаконности кооператива и его последующей ликвидации – чтобы забрать активы кооператива в свой фонд, выплатив всем членам кооператива, в том числе тем «потерпевшим», кто написал на кооператив заявление в правоохранительные органы, по 35 тыс. рублей, и жить на оставшиеся 4 млрд припеваючи. Кстати, он, судя по всему, по-прежнему не в России – занимается грабежом из теплых стран. Иначе чем объяснить, что он, являясь свидетелем по уголовному делу, никак не может прийти в Приморский районный суд и дать показания, а прокуратура никак не может обеспечить его привод? Отпетые мошенники Лях и его подручные – люди, которые разоряют организации, отбирают активы, накопления, обманом вводят в заблуждение людей и провоцируют их на заявление претензий, которые не могут быть удовлетворены. Юристы, подконтрольные Ляху, обдирают людей, не сообщая им, что те являются массовкой в постановке, по итогам которой участники также получат по 35 тыс. рублей, а не миллионы, претензии на которые они заявляют. Миллионами Лях и Ко с ними не поделятся – всем «потерпевшим» нужно четко это осознать. Адвокаты кооператива начали предусмотренное законом адвокатское расследование того, кто помимо Ляха является бенефициарами Фонда по защите прав вкладчиков и акционеров, кто стоит за хейтерскими ресурсами, участвует в хейтерских атаках, организуя массовое ограбление людей, в том числе «потерпевших». Они озвучат все фамилии, чтобы вскрыть этот фурункул на теле России. Считаем, что Следственному комитету России и лично Александру Бастрыкину нужно разобраться и пресечь коррупционное преступление Ляха и Ко. Мы поможем ему – направим соответствующую информацию в Следком. Просим сообщить в редакцию или в официальный канал кооператива https://t.me/best_way_coop о хейтерах – чтобы найти их, сообщить о них в Следком, тем самым отрезав щупальца у спрута, созданного Ляхом.
Лайф-из-Гуд
KRAKEN – ссылка, зеркало, сайт, кракен магазин
KRAKEN – ссылка, зеркало, сайт, кракен вход
Тут можно преобрести купить противопожарный сейф огнестойкий сейф купить
Узнайте, как безопасно купить диплом о высшем образовании
telegram vavada промокоды
A giant meteorite boiled the oceans 3.2 billion years ago. Scientists say it was a ‘fertilizer bomb’ for life
смотреть порно жесток
A massive space rock, estimated to be the size of four Mount Everests, slammed into Earth more than 3 billion years ago — and the impact could have been unexpectedly beneficial for the earliest forms of life on our planet, according to new research.
Typically, when a large space rock crashes into Earth, the impacts are associated with catastrophic devastation, as in the case of the demise of the dinosaurs 66 million years ago, when a roughly 6.2-mile-wide (10-kilometer) asteroid crashed off the coast of the Yucatan Peninsula in what’s now Mexico.
But Earth was young and a very different place when the S2 meteorite, estimated to have 50 to 200 times more mass than the dinosaur extinction-triggering Chicxulub asteroid, collided with the planet 3.26 billion years ago, according to Nadja Drabon, assistant professor of Earth and planetary sciences at Harvard University. She is also lead author of a new study describing the S2 impact and what followed in its aftermath that published Monday in the journal Proceedings of the National Academy of Sciences.
“No complex life had formed yet, and only single-celled life was present in the form of bacteria and archaea,” Drabon wrote in an email. “The oceans likely contained some life, but not as much as today in part due to a lack of nutrients. Some people even describe the Archean oceans as ‘biological deserts.’ The Archean Earth was a water world with few islands sticking out. It would have been a curious sight, as the oceans were probably green in color from iron-rich deep waters.”
When the S2 meteorite hit, global chaos ensued — but the impact also stirred up ingredients that might have enriched bacterial life, Drabon said. The new findings could change the way scientists understand how Earth and its fledgling life responded to bombardment from space rocks not long after the planet formed.
1win games
Тут можно преобрести сейф купить оружейный сейф для оружия
bc hash game
pg slot terpercaya
Judul: Mengalami Pengalaman Bertaruh dengan “PG Slot” di Situs Kasino ImgToon.com
Dalam kehidupan permainan kasino online, slot telah menyusun salah satu permainan yang paling disukai, terutama jenis PG Slot. Di antara beberapa situs kasino online, ImgToon.com adalah tujuan utama bagi peserta yang ingin mencoba peruntungan mereka di banyak permainan slot, termasuk beberapa kategori terkenal seperti demo pg slot, pg slot gacor, dan RTP slot.
Demo PG Slot: Menjalani Tanpa adanya Risiko
Salah satu fungsi menarik yang diberikan oleh ImgToon.com adalah demo pg slot. Fungsi ini memungkinkan pemain untuk mencoba berbagai jenis slot dari PG tanpa harus bertaruh taruhan uang asli. Dalam mode demo ini, Anda dapat memeriksa berbagai taktik dan mengetahui sistem permainan tanpa ancaman kehilangan uang. Ini adalah langkah terbaik bagi orang baru untuk terbiasa dengan permainan slot sebelum berpindah ke mode taruhan nyata.
Mode demo ini juga menyediakan Anda pandangan tentang potensi kemenangan dan bonus yang mungkin bisa Anda terima saat bermain dengan uang asli. Pemain dapat menjelajahi permainan tanpa khawatir, menjadikan pengalaman bermain di PG Slot semakin membahagiakan dan bebas tekanan.
PG Slot Gacor: Prospek Besar Mendapatkan Kemenangan
PG Slot Gacor adalah kata populer di kalangan pemain slot yang merujuk pada slot yang sedang dalam fase memberikan kemenangan tinggi atau lebih sering diistilahkan “gacor”. Di ImgToon.com, Anda dapat mendapatkan berbagai slot yang masuk dalam kategori gacor ini. Slot ini diakui memiliki peluang kemenangan lebih tinggi dan sering menghadiahkan bonus besar, membuatnya pilihan utama bagi para pemain yang ingin memperoleh keuntungan maksimal.
Namun, harus diingat bahwa “gacor” atau tidaknya sebuah slot dapat bergeser, karena permainan slot tergantung generator nomor acak (RNG). Dengan bermain secara rutin di ImgToon.com, Anda bisa menemukan pola atau waktu yang tepat untuk memainkan PG Slot Gacor dan memperbesar peluang Anda untuk menang.
RTP Slot: Faktor Esensial dalam Pencarian Slot
Ketika mendiskusikan tentang slot, istilah RTP (Return to Player) adalah faktor yang sangat krusial untuk dihitung. RTP Slot berkaitan pada persentase dari total taruhan yang akan dipulangkan kepada pemain dalam jangka panjang. Di ImgToon.com, setiap permainan PG Slot diberi dengan informasi RTP yang terperinci. Semakin tinggi persentase RTP, semakin besar peluang pemain untuk memperoleh kembali sebagian besar dari taruhan mereka.
Dengan memilih PG Slot yang memiliki RTP tinggi, pemain dapat mengelola pengeluaran mereka dan memiliki peluang yang lebih baik untuk menang dalam jangka panjang. Ini menjadikan RTP sebagai indikator penting bagi pemain yang mencari keuntungan dalam permainan kasino online.
Аттестат 11 класса купить официально с упрощенным обучением в Москве
1win
KRAKEN – ссылка, зеркало, сайт, KRAKEN
Готов услышать трек, который выбьет из тебя все оправдания? Слушай, если не боишься правды.
Game keys
Explore a Realm of Video Game Possibilities with ItemsforGames
At Items4Games, we offer a active marketplace for gamers to purchase or trade profiles, items, and services for some of the most popular titles. If you are looking to upgrade your gaming arsenal or looking to monetize your account, our service delivers a seamless, secure, and valuable journey.
Reasons to Use Items4Play?
**Broad Game Collection**: Discover a vast selection of video games, from thrilling adventures like Battleground and Call of Duty to captivating RPGs like ARK: Survival Evolved and Genshin Impact. We cover it all, ensuring no player is left behind.
**Selection of Options**: Our products cover game account acquisitions, virtual money, unique goods, achievements, and mentoring services. Whether you want assistance leveling up or getting premium rewards, we are here to help.
**Ease of Use**: Navigate easily through our well-organized platform, arranged in order to locate exactly the game you are looking for fast.
**Protected Transactions**: We ensure your security. All transactions on our marketplace are processed with the top protection to secure your personal and monetary information.
**Key Points from Our Collection**
– **Survival and Exploration**: Games like ARK: Survival Evolved and Day-Z allow you to explore exciting environments with top-notch gear and accesses on offer.
– **Adventure and Questing**: Elevate your gameplay in titles like Clash Royale and Wonders Age with virtual money and features.
– **eSports Competitions**: For competitive players, enhance your abilities with mentoring and profile boosts for Valorant, Dota, and League of Legends.
**A Hub Made for Gamers**
Supported by Apex Technologies, a established business certified in Kazakh Republic, ItemsforGames is a market where video game wishes become real. From purchasing early access codes for the freshest titles to finding hard-to-find in-game treasures, our site fulfills every player’s requirement with skill and reliability.
Sign up for the community right away and elevate your game adventure!
For inquiries or help, contact us at **support@items4games.com**. Let’s all improve the game, as a community!
вывод из запоя стационар ростов https://www.zarabotokdoma.creartuforo.com/viewtopic.php?id=11471 .
заказать алкоголь с доставкой москва https://dostavka-alcogolya-nochyu.ru/
дезинфекция после смерти москва https://dezinfekciya-smerti-msk-mo.ru/
omra tunis
Тут можно преобрести оружейный сейф сейф под оружие цена
нарколог на дом цены https://setter.borda.ru/?1-7-0-00000673-000-0-0-1730729894/ .
BBgate MarketPlace 2024 Breaking Bad Gate Forum
BBgate MarketPlace
vavada казино
KRAKEN – ссылка, зеркало, сайт, кракен вход
KRAKEN – ссылка, зеркало, сайт, кракен ссылка тор
Как быстро и легально купить аттестат 11 класса в Москве
KRAKEN – ссылка, зеркало, сайт, KRAKEN
KRAKEN – ссылка, зеркало, сайт, кракен ссылка тор
фонтбет фонтбет .
Узнайте, как безопасно купить диплом о высшем образовании
KRAKEN – ссылка, зеркало, сайт, кракен зеркало
Купить диплом старого образца, можно ли это сделать по быстрой схеме?
вывод из запоя в стационаре воронежа kyevlyn.ukrbb.net/viewtopic.php?f=2&t=13641 .
Идеальная коляска Bugaboo для вашего малыша, Купить коляску Bugaboo – значит сделать правильный выбор, Как выбрать идеальную коляску Bugaboo для вашего малыша, Bugaboo: стиль и функциональность в одном, Bugaboo – это качество и надежность, Bugaboo Fox: лучший выбор для активных родителей, Bugaboo Donkey: простор для ваших малышей, Bugaboo Buffalo: коляска для любых приключений.
bugaboo для двойни купить [url=https://kolyaski-bugaboo-msk.ru/]https://kolyaski-bugaboo-msk.ru/[/url] .
KRAKEN – ссылка, зеркало, сайт, кракен тор
KRAKEN – ссылка, зеркало, сайт, Кракен клирнет ссылка
вывод из запоя воронеж http://www.dmitrov.rusff.me/viewtopic.php?id=1659/ .
KRAKEN – ссылка, зеркало, сайт, кракен официальный сайт
по доступной цене
самоклеющийся багет самоклеющийся багет .
KRAKEN – ссылка, зеркало, сайт, кракен ссылка тор
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
KRAKEN – ссылка, зеркало, сайт, кракен сайт
Please let me know if you’re looking for a author for your weblog. You have some really good posts and I think I would be a good asset. If you ever want to take some of the load off, I’d love to write some content for your blog in exchange for a link back to mine. Please shoot me an e-mail if interested. Kudos!
http://neoko.ru/images/pages/1xbet_promokod_na_besplatnuu_stavku.html
일본 소비세 환급, 네오리아와 함께라면 간편하고 안전하게
일본 소비세 환급은 복잡하고 까다로운 절차로 많은 구매대행 셀러들이 어려움을 겪는 분야입니다. 네오리아는 다년간의 경험과 전문성을 바탕으로 신뢰할 수 있는 서비스를 제공하며, 일본 소비세 환급 과정을 쉽고 효율적으로 처리합니다.
1. 일본 소비세 환급의 필요성과 네오리아의 역할
네오리아는 일본 현지 법인을 설립하지 않아도 합법적인 방식으로 소비세 환급을 받을 수 있는 솔루션을 제공합니다. 이를 통해:
한국 개인사업자와 법인 사업자 모두 간편하게 환급 절차를 진행할 수 있습니다.
일본의 복잡한 서류 심사를 최소화하고, 현지 로컬 세리사와 협력하여 최적의 결과를 보장합니다.
2. 소비세 환급의 주요 특징
일본 연고가 없어도 가능: 일본에 사업자가 없더라도 네오리아는 신뢰할 수 있는 서비스를 통해 소비세 환급을 지원합니다.
서류 작성 걱정 해결: 잘못된 서류 제출로 환급이 거절될까 걱정될 필요 없습니다. 네오리아의 전문 대응팀이 모든 과정을 정밀하게 관리합니다.
현지 법인 운영자를 위한 추가 지원: 일본 내 개인사업자나 법인 운영자에게는 세무 감사와 이슈 대응까지 포함된 고급 서비스를 제공합니다.
3. 네오리아 서비스의 장점
전문성과 신뢰성: 정부로부터 인정받은 투명성과 세무 분야의 우수한 성과를 자랑합니다.
맞춤형 서포트: 다양한 사례를 통해 쌓은 경험으로 고객이 예상치 못한 어려움까지 미리 해결합니다.
로컬 업체에서 불가능한 고급 서비스: 한국인 고객을 위해 정확하고 간편한 세무회계 및 소비세 환급 서비스를 제공합니다.
4. 네오리아가 제공하는 혜택
시간 절약: 복잡한 절차와 서류 준비 과정을 전문가가 대신 처리합니다.
안심 환급: 철저한 관리와 세심한 대응으로 안전하게 환급을 받을 수 있습니다.
추가 서비스: 세무감사와 이슈 발생 시 즉각적인 지원으로 사업의 연속성을 보장합니다.
네오리아는 소비세 환급이 복잡하고 어렵다고 느껴지는 고객들에게 최적의 길잡이가 되어드립니다. 신뢰를 바탕으로 한 전문적인 서비스로, 더 이상 소비세 환급 문제로 고민하지 마세요!
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
Клининг квартиры после смерти животного https://klining-kvartir-posle-trupa.ru/
KRAKEN – ссылка, зеркало, сайт, кракен сайт
опубликовано здесь https://omgomgonion.com/
https://gruzoperevozki-minsk077.ru/
нарколог на дом ya.7bb.ru/viewtopic.php?id=14616#p41014 .
KRAKEN – ссылка, зеркало, сайт, кракен официальный сайт
KRAKEN – ссылка, зеркало, сайт, кракен маркет
Ритуальные услуги в Краснодаре: организация похорон, кремации, перевозка умерших в морг, строительство колумбариев, уборка могил. Узнайте больше тут – https://rit93.ru/
Интернет-магазин парфюмерии
Современный мир характеризуется изобилием выбора. Парфюмерная продукция не стала исключением. Наш интернет-магазин тому подтверждение. На его страницах вы можете найти более 10 тысяч наименований различных ароматов.
Всего 100 лет назад началось фабричное производство духов и с того момента парфюмерная индустрия развивалась стремительно и неумолимо. Новые веяния диктовали моду, в том числе и на ароматы. Цитрусовые, зеленые ароматы пришли на смену шипровым; восточные ароматы сменили цветочные; а сладкие фрукты и ягоды в парфюме заменили морские, озоновые ноты. Сегодня в мире парфюмерии отчетливо прослеживается влияние востока.
Как официально приобрести аттестат 11 класса с минимальными затратами времени
KRAKEN – ссылка, зеркало, сайт, кракен сайт
view publisher site Tutoriage
вывод из запоя круглосуточно нижний новгород вывод из запоя круглосуточно нижний новгород .
娛樂城
富遊娛樂城:台灣線上賭場的創新選擇
在台灣的線上娛樂市場中,富遊娛樂城憑藉其優質的服務和多樣化的娛樂選項,迅速成為新一代玩家的首選。既有刺激的遊戲體驗,又提供了一系列具有吸引力的優惠,富遊娛樂城無疑是追求樂趣的玩家們理想的地方。
#### 優勢與特色
1. 多樣化的遊戲選擇
富遊娛樂城提供了豐富的遊戲種類,包括電子老虎機、真人百家樂、運彩投注等。不論你是老虎機的愛好者,還是熱衷於真人賭桌的玩家,這裡都能滿足你的需求。特別推薦的遊戲如DG真人百家和RSG皇家百家樂,一定能帶給你極致的遊戲體驗。
2. 吸引人的優惠活動
富遊娛樂城針對新手和老玩家都推出了多樣的優惠活動。新會員首次存款可獲得相同金額的獎金,還有額外的體驗金送出,設計友好且實惠。此外,富遊每週的簽到獎勵和天天無上限的返水活動,更是讓玩家在遊戲中能持續獲得收益。
3. 安全可靠的存取款方式
在金融交易方面,富遊娛樂城支持多種存款和提款方式,包括各大銀行轉帳、超商儲值,甚至虛擬貨幣等。最低提款金額設置靈活,保證玩家資金的安全與便捷。
4. 人性化的操作介面
富遊娛樂城的網頁與移動應用設計簡潔易用,玩家可以方便地找到所需的遊戲和優惠。無論是在電腦還是手機上,都能順利享受到遊戲的樂趣。
#### 如何開始遊戲
如果你是新手玩家,開始你的富遊體驗非常簡單。只需註冊帳號,完成首次存款,即可獲得新手優惠。無論你想嘗試電子遊戲還是真人賭局,富遊娛樂城都能讓你輕鬆上手,享受娛樂的樂趣。
#### 社會責任與防沉迷措施
富遊娛樂城深知線上賭博的風險,因此致力於推廣負責任的遊戲文化。他們提供“防沉迷”指導,以確保玩家能夠理性投注,並提供必要的幫助和資源來幫助有需求的玩家。
#### 總結
對於尋求安全、便捷和多元化娛樂城體驗的玩家,富遊娛樂城絕對是值得選擇的選項。無論你是希望徹底放鬆,還是想要體驗刺激的博弈過程,富遊娛樂城都能滿足你的期待,成為你在台灣線上娛樂市場的最佳夥伴。立即註冊並開始你的遊戲之旅吧!
вызвать капельнцу от запоя вызвать капельнцу от запоя .
перейти на сайт
[url=https://exci.ru/methods/Lasik/]lasik[/url]
узнать больше https://euroshop18.ru
娛樂城
富遊娛樂城:台灣線上賭場的創新選擇
在台灣的線上娛樂市場中,富遊娛樂城憑藉其優質的服務和多樣化的娛樂選項,迅速成為新一代玩家的首選。既有刺激的遊戲體驗,又提供了一系列具有吸引力的優惠,富遊娛樂城無疑是追求樂趣的玩家們理想的地方。
#### 優勢與特色
1. 多樣化的遊戲選擇
富遊娛樂城提供了豐富的遊戲種類,包括電子老虎機、真人百家樂、運彩投注等。不論你是老虎機的愛好者,還是熱衷於真人賭桌的玩家,這裡都能滿足你的需求。特別推薦的遊戲如DG真人百家和RSG皇家百家樂,一定能帶給你極致的遊戲體驗。
2. 吸引人的優惠活動
富遊娛樂城針對新手和老玩家都推出了多樣的優惠活動。新會員首次存款可獲得相同金額的獎金,還有額外的體驗金送出,設計友好且實惠。此外,富遊每週的簽到獎勵和天天無上限的返水活動,更是讓玩家在遊戲中能持續獲得收益。
3. 安全可靠的存取款方式
在金融交易方面,富遊娛樂城支持多種存款和提款方式,包括各大銀行轉帳、超商儲值,甚至虛擬貨幣等。最低提款金額設置靈活,保證玩家資金的安全與便捷。
4. 人性化的操作介面
富遊娛樂城的網頁與移動應用設計簡潔易用,玩家可以方便地找到所需的遊戲和優惠。無論是在電腦還是手機上,都能順利享受到遊戲的樂趣。
#### 如何開始遊戲
如果你是新手玩家,開始你的富遊體驗非常簡單。只需註冊帳號,完成首次存款,即可獲得新手優惠。無論你想嘗試電子遊戲還是真人賭局,富遊娛樂城都能讓你輕鬆上手,享受娛樂的樂趣。
#### 社會責任與防沉迷措施
富遊娛樂城深知線上賭博的風險,因此致力於推廣負責任的遊戲文化。他們提供“防沉迷”指導,以確保玩家能夠理性投注,並提供必要的幫助和資源來幫助有需求的玩家。
#### 總結
對於尋求安全、便捷和多元化娛樂城體驗的玩家,富遊娛樂城絕對是值得選擇的選項。無論你是希望徹底放鬆,還是想要體驗刺激的博弈過程,富遊娛樂城都能滿足你的期待,成為你在台灣線上娛樂市場的最佳夥伴。立即註冊並開始你的遊戲之旅吧!
капельница на дом круглосуточно капельница на дом круглосуточно .
капельница при алкогольной интоксикации на дому цена [url=www.mymoscow.forum24.ru/?1-6-0-00022952-000-0-0-1730815603/]капельница при алкогольной интоксикации на дому цена[/url] .
быстрый вывод из запоя в стационаре быстрый вывод из запоя в стационаре .
Теперь вижу ситуацию иначе.
beburishvili-afisha.ru
вывод из запоя в стационаре анонимно вывод из запоя в стационаре анонимно .
“Ethena: The Next Generation of Decentralized Finance”
The decentralized finance (DeFi) sector has seen explosive growth in recent years, and Ethena is leading the charge toward a more accessible and secure financial ecosystem. Built on blockchain technology, Ethena offers a wide range of decentralized financial services, including staking, lending, borrowing, and yield farming.
[url=https://eithena.fi/]ethena[/url]
What is Ethena?
Ethena is a decentralized platform that allows users to interact with financial products without the need for traditional intermediaries like banks. By leveraging blockchain technology, Ethena offers full transparency, enhanced security, and greater control over digital assets. Whether you’re a seasoned crypto investor or new to the space, Ethena provides all the tools needed to take part in the DeFi revolution.
Key Features of Ethena:
Decentralization: With Ethena, there’s no middleman. Users have complete control over their assets and financial decisions, making the platform transparent and trustless.
Security: Ethena prioritizes security by using robust blockchain protocols to safeguard users’ funds and data.
Yield Optimization: The platform offers optimized opportunities for yield farming, allowing users to maximize returns on their digital assets.
Governance with Ethena Fi: Holders of Ethena Fi, the platform’s native token, can vote on crucial protocol changes, making Ethena a truly community-driven platform.
Why Choose Ethena?
As DeFi continues to disrupt traditional finance, Ethena stands out with its user-centric features and commitment to security. For anyone looking to explore the future of finance, Ethena provides an easy and secure gateway into the world of decentralized finance.
https://www.ochistkakotlov.ru/ –
Получено разрешение Госгортехнадзора по применению ГУВ для очистки ПН котлоагрегатов от наружных отложений (письмо № 12-21/831 от 02,09.1997г.). Освоен серийный выпуск переносного ГУВ и ЭЗ на заводах ВПК, которыми комплектуются котлоагрегаты Бийского котельного завода на стадии их заводского изготовления. Проведены испытания ГУВ на котлоагрегатах Белгородского котельного завода и достигнуты договоренности по оснащению их ГУВами на уровне штатного оборудования.
ГУВ-38 оснащен переносным механическим приводом для производства генерации (УВ). При необходимости одновременного срабатывания нескольких ГУВ-38 (мах 8шт.) возможна комплектация электроспусковыми механизмами и Блок управления ударным механизмом (БУУМ).
капельницы на дому от запоя капельницы на дому от запоя .
капельница от запоя [url=http://alhambra.bestforums.org/viewtopic.php?f=10&t=46488]капельница от запоя[/url] .
брекет система https://brekety-na-zuby.ru/
Пошаговая инструкция по официальной покупке диплома о высшем образовании
ОПГ Владимира Колокольцева
[url=https://www.pravda.ru/realty/1992827-pokazanija-po-delu/]Потерпевшие Бест Вей[/url]
Как команда министра внутренних дел подставляет Президента.
Широко разрекламированное МВД разбирательство по поводу «крупнейшей в России пирамиды», связываемое следствием с компаниями «Лайф-из-Гуд», «Гермес Менеджмент» и кооперативом «Бест Вей», вышло на финишную прямую — дело, которое вело ГСУ ГУ МВД России по Санкт-Петербургу и Ленинградской области под кураторством со стороны Следственного департамента МВД, передано сначала в прокуратуру Санкт-Петербурга, а потом в Приморский районный суд города Санкт-Петербурга для рассмотрения по существу — оно начнется 27 февраля.
Со всеми преступлениями и правонарушениями на этом пути, которых наберется не менее двух десятков, следователи МВД смогли выйти на скромную сумму 280 млн ущерба при 221 лице, признанном следствием потерпевшими. Однако у «Гермес Менеджмент» в России много десятков клиентов, которые довольны условиями и получаемым доходом, а у кооператива «Бест Вей», незаконно признанного гражданским ответчиком по делу, — около двух десятков тысяч пайщиков, подавляющее большинство из которых считает следствие МВД нарушителем своих прав, так как в результате действий следствия они лишены возможности приобрести подобранную недвижимость и лишены возможности вернуть вложения в кооператив. Следствие заблокировало счета кооператива и запрещает выплаты с них даже на основании судебных решений, не говоря уже о том, что оно запрещает выплаты налогов и заработной платы сотрудникам аппарата кооператива.
Следствие путем ареста имущества пытается захватить многомиллиардные активы: оно арестовало около 4 млрд рублей на счетах кооператива, пыталось восстановить арест недвижимости кооператива на 8 млрд рублей — теперь эстафету у него приняла прокурорская группа из прокуратуры Санкт-Петербурга и прокуратуры Приморского района Санкт-Петербурга. Плюс к этому следствие арестовало на 8 млрд личного имущества обвиняемых.
Фактически речь идет о том, чтобы отдать эти средства в руки группы мошенников, объявивших себя потерпевшими. Следственная группа, судя по всему, находится в сговоре с ними, о чем свидетельствуют, в частности, написанные как под копирку, с одинаковыми орфографическими ошибками заявления от этих «потерпевших» о возмещении морального ущерба по 1 млрд рублей каждое.
В первом, «организационном» заседании Приморского районного суда, предшествующем рассмотрению уголовного дела по существу, упоминание государственного обвинителя из прокуратуры Санкт-Петербурга об этих заявлениях вызвало смех в зале: по судебной практике моральный ущерб на сумму свыше 100 тыс. рублей удовлетворяется судами в исключительных случаях. Но эти юридически ничтожные, по сути, заявления объявляются основанием для ареста имущества.
Жульничество с документами
Поток преступлений и правонарушений следствия не останавливался до самого последнего дня предварительного расследования. Они были совершены при потворстве людей из команды Колокольцева, требовавших результата любой ценой.
1 декабря Приморский районный суд вынужден был признать незаконным фактический отказ кооперативу «Бест Вей» в ознакомлении с материалами уголовного дела, а также признал, что следствие грубо нарушило УПК, не объявив в установленном порядке о завершении следственных действий. Тем самым оно нарушило права всех гражданских истцов и ответчиков на ознакомление с материалами уголовного дела.
При рассмотрении жалобы адвоката кооператива в Приморском районном суде выяснилось, что следственная группа ГСУ, последний год формально руководимая замначальника ГСУ полковником юстиции А.Н. Винокуровым, а фактически, как и раньше, подполковником юстиции Е.А. Сапетовой, подделала документы (Винокуров был назначен в качестве «крыши», «тарана», поскольку ходатайства следственной группы в первый период расследования очень плохо проходили в судах).
Жалоба была подана адвокатом кооператива в июле, много раз ее рассмотрение откладывалось и состоялось в декабре. Уличенная адвокатами кооператива в нарушении УПК, следственная группа составила письмо об удовлетворении ходатайства задним числом и попыталась представить дело так, что кооператив не получил письмо по своей вине. Очередная грубая работа, выявленная, как ни парадоксально, в том числе и с помощью системы электронного документооборота самого питерского главка МВД.
https://www.ochistkakotlov.ru/ – Мы являемся обладателями патента на генератор ударных волн ГУВ-38!
Известно, что во всех котлах, независимо от применяемого топлива, в процессе работы происходит зарастание трубных пучков золошлаковыми и сажистыми отложениями. Штатные системы очистки котлов (воздушные, паровые, газоимпульсные) даже при надлежащем их использовании не обеспечивают качественную очистку поверхностей нагрева.
Процессуальный хакинг: адвокаты потребкооператива посчитали обращение с УПК вольным
австрийский инвестор Йохан Риглер
12-18 октября в Санкт-Петербурге состоялись девять судов первой инстанции по рассмотрению ходатайств руководителя следственной группы ГСУ ГУ МВД России по городу Санкт-Петербургу и Ленинградской области полковника юстиции А. Н. Винокурова о продлении мер пресечения обвиняемым на новые три месяца — до 19 января 2024 года — в связи с общим продлением срока предварительного расследования до середины февраля 2024 года.
Четыре заседания состоялись в Санкт-Петербургском городском суде — по продлению ареста гражданам, у которых еще в середине августа превышен предельный срок содержания под стражей — полтора года: Анне Высоцкой, Александре Григорьевой, Елене Соловьевой и Михаилу Измайлову. Пять заседаний прошло в Приморском районном суде города Санкт-Петербурга: по продлению “стражи” Альмире Гильберт, Дмитрию Мазанову, Анатолию Наливану и Денису Шишко; по продлению домашнего ареста Вячеславу Выдрину. Мера пресечения в виде запрета определенных действий еще одному обвиняемому — Виктору Ивановичу Василенко, отцу основателя “Лайф-из-Гуд” и кооператива “Бест Вей” Романа Василенко, была избрана 23 марта на весь срок предварительного расследования.
Все ходатайства были судьями удовлетворены, при этом работа следствия во многих случаях подвергались ими критике. И во второй инстанции (а по всем девяти судебным постановлениям адвокатами поданы апелляции) сохранение мер пресечения не будет для следственной группы простой задачей.
Следствие завершено?
Формально предварительное расследование вышло на финишную прямую в июне, так как в августе истекал предельный срок содержания под стражей четверых обвиняемых: Высоцкой, Григорьевой, Соловьевой и Измайлова. Срок следственных действий был согласно постановлению заместителя начальника Следственного департамента МВД России генерал-майора юстиции А. Н. Вохмянина ограничен июлем, а общий срок предварительного расследования, включающий и процессуальные действия после завершения следственных, — серединой октября. Но в октябре генерал Вохмянин издал постановление о продлении общего срока предварительного расследования до середины февраля 2024 года, в связи с тем, что следственная группа не смогла завершить процессуальные действия — ознакомление обвиняемых с материалами дела и составление обвинительного заключения для передачи уголовного дела в суд для рассмотрения по существу.
Продление объяснялось в судах ознакомлением обвиняемых с материалами уголовного дела, в котором 210 томов. Однако еще перед первым июльским продлением “стражи” в связи с ознакомлением с материалами уголовного дела возникли две процессуальные проблемы, которые не исчезли и в октябре.
Первая — по утверждению адвокатов обвиняемых, пропущен этап ознакомления с материалами дела гражданских истцов и гражданских ответчиков, то есть сам переход к ознакомлению обвиняемых был незаконен. Следовательно, необходимо было вернуться на предыдущий этап, отпустив обвиняемых из-под стражи, тем более что следственные действия завершены.
Вторая — все обвиняемые до одного отказались знакомиться с материалами дела из-за грубых процессуальных нарушений, допущенных при завершении следственных действий в июне. Завершение следственных действий проводилось, как говорят адвокаты, в пожарном порядке, с грубыми процессуальными нарушениями. Обвиняемым, по утверждению адвокатов, дали в среднем полчаса на прочтение более чем 70-страничных постановлений о привлечении в качестве обвиняемых — большинство успело прочитать не более 20 страниц; отказались провести допросы после предъявления обвинений, на которых настаивали обвиняемые и т. д. В связи с этими нарушениями адвокаты обращались в Управление Следственного комитета России по городу Санкт-Петербургу по признакам должностных преступлений со стороны следственной группы.
Следствие, поясняют адвокаты причины этих действий следственной группы, в конце весны — начале лета сего года оказалось в цейтноте. Оно, по убеждению адвокатов, всеми силами стремилось не выпустить обвиняемых, что обязано было бы сделать, если бы следственные действия были продлены или точно выполнен алгоритм, определенный УПК для завершения предварительного расследования.
Основанием для оставления под стражей могло быть только начало ознакомления обвиняемых с материалами дела, и потому следствие, по оценке адвокатов, начало заниматься процессуальным хакингом: сначала с нарушениями провело предъявление обвинений в окончательной редакции, а затем заявило, что никто из гражданских истцов и ответчиков не изъявил желания знакомиться с материалами дела.
Отказались знакомиться?
Последнее утверждение, говорят адвокаты, не соответствует действительности. Адвокатам известен как минимум один из гражданских истцов, который намеревался ознакомиться с материалами дела, — его фамилия называлась в судах.
Что же касается гражданских ответчиков, то документально подтверждено, что намерение ознакомиться с материалами дела выражал кооператив “Бест Вей” — один из гражданских ответчиков. Причем этот статус был присвоен ему самой следственной группой: постановлением руководителя следственной группы А. Н. Винокурова кооператив стал гражданским ответчиком аж на 16 млрд рублей, причем следствие отказывалось представить истцов и их исковые требования.
Однако на недавнее заседание Приморского районного суда по аресту счетов кооператива на новый трехмесячный срок были принесены заявления от двух граждан, признанных следствием потерпевшими, о взыскании морального ущерба в объеме по одному миллиарду рублей на каждого из заявителей. Причем общий материальный ущерб, имеющийся в уголовном деле, на этих двоих граждан — менее миллиона.
Но, подчеркивают адвокаты, во-первых, оба требования о возмещении морального ущерба адресованы “виновным лицам”, а не кооперативу. Следствие предлагает рассматривать кооператив как одно из этих лиц — речь идет, по версии следствия и лиц, признанных им потерпевшими, о невыполнении обязательств компанией “Гермес Менеджмент”, а кооператив якобы был с этой компанией аффилирован, потому и должен отвечать по обязательствам этой иностранной компании, не имеющей активов в России. Во-вторых, отмечают адвокаты, требования о возмещении морального ущерба обосновываются общими словами о моральных страданиях и ухудшении здоровья, а должны, согласно законодательству, основываться на обстоятельствах причинения ущерба личным неимущественным правам.
Требования возмещения морального ущерба, подчеркивают адвокаты, призваны дать хоть какую-то материальную основу для ходатайства следствия об аресте почти 4 млрд рублей на счетах кооператива, притом что общий объем ущерба, названный в постановлениях о привлечении к ответственности в качестве обвиняемых, — 232 млн рублей.
Узнай больше про 1xSlots https://aztarna.es/pages/1xslots-casino_15.html
Going Here SMS verification without SIM card
Производство ангаров и складов под ключ.
Подробная информация и заказ быстровозводимый складов
просушка автомобиля https://sushka-ot-zatopleniya-495.ru/
In China, people are hiring ‘climbing buddies’ for big money. The more attractive they are, the higher the price
VIP эскорт-услуги в Израиле
Wendy Chen decided to challenge herself by climbing Mount Tai, a well-known mountain in eastern China.
But there was one obstacle in her way: she couldn’t find a friend to join her for the five-hour trek.
Rather than forgo her plans, the 25-year-old hired a “climbing buddy,” a young man with extensive outdoor experience, to accompany and support her to the 5,000-foot peak.
Known in Chinese as “pei pa” (meaning “accompany to climb”), these are young Chinese men who join strangers on their journeys up popular mountains for a price. The trend has gained momentum this year, as hashtags related to “climbing buddy” have had over 100 million views on Chinese social media.
Young, athletic individuals, often university students or even military veterans, advertise themselves on social media platforms like Xiaohongshu and Douyin, with profiles featuring their height, fitness level and hiking experience. They usually charge between 200 to 600 yuan ($30 to $85) per trip.
During the climb, these “buddies” will do anything to distract their clients from feeling exhausted and push them to keep going: from singing, telling jokes, playing music, verbal encouragement, going so far as carrying their bags, holding their hands, and pulling them.
A day on the mountain
Chen and her climbing buddy’s adventure began at around 8:00 pm so she could arrive at the peak in time for the famous sunrise. After assessing her fitness level, her climbing buddy planned a moderate route and carried her backpack the whole way.
When they faced chilling winds at the peak, Chen’s climbing buddy rented a thick coat for her while directing her to a walled shelter.
At the moment the sun rose, Chen’s climbing buddy was already prepared with a national flag and other props so that she could take a memorable photo. Though she felt his photography skills still had room to improve, she rated her climbing buddy as “satisfactory.” The service cost her 350 yuan ($49).
Though Chen paid a typical price for a climbing buddy, she acknowledges that more good-looking buddies can command higher rates.
“Attractiveness is also part of their strength,” she says.
Climbing buddies’ main customers tend to be single young women, but that’s slowly changing.
A video of a strong male university student carrying a three-year-old effortlessly up a steep mountain — while the toddler’s mother trailed far behind — went viral this summer.
He thought the guy he met on vacation was just a fling. He turned out to be the love of his life
Pancakeswap
Guillermo Barrantes relationship with Larry Mock was supposed to begin and end in Palm Springs.
It was a “casual, brief encounter.” A vacation dalliance that only lasted half a day.
“It was just so casual, so easily nothing could have happened from it,” Guillermo tells CNN Travel. “We could have walked away and just had our lives separate. But of course that didn’t happen, because it wasn’t meant to be that way. It was meant to be the way that it was. That it is.”
It all started in summer 2013. Guillermo – then in his early 40s – was on vacation in the California resort city of Palm Springs. He was in a phase of life where, he says, he was prioritizing himself, and wasn’t interested in long term romance.
“I thrived in being by myself, in traveling by myself, in having dinner by myself – I loved all of that so much,” says Guillermo, who lived in Boston, Massachusetts at the time.
“I wanted no commitment, I wanted no emotional entanglement of any kind. I wanted to have fun, get to know myself. And it was in that mode that I met Larry, when I wasn’t really looking.”
During the vacation in Palm Springs, Guillermo was staying at a friend’s apartment, and while the friend worked during the day, Guillermo passed his time at a “run-down, no-frills” resort a couple of blocks away.
“You could just pay for a day pass, they’d give you a towel, and you could be in the pool and use their bar,” he recalls.
One day, as he was walking the palm tree-lined streets to the resort, Guillermo swiped right on a guy on a dating app – Larry Mock, mid-40s, friendly smile. The two men exchanged a few messages back and forth. Larry said he was also on vacation in Palm Springs, staying in the resort Guillermo kept frequenting.
They arranged to meet there for a drink by the pool. Guillermo was looking forward to meeting Larry, expecting “some casual fun.”
Then, when Guillermo and Larry met, there was “chemistry” right away. Guillermo calls their connection “magnetic.”
“My impression of Larry: sexy, handsome and warm,” he recalls.
Характеристики 1xSlots https://davisa.es/page/1xslots-casino-argentina.html
you could try here https://my-sollet.com
две вагины https://medicinye.ru/
норма ферритина у женщин после 30 https://deficit-iron.ru/
таможенные брокеры таможенные брокеры .
опубликовано здесь
официальный сервис wehavy
GAMELANTOGEL
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов samsung адреса, можете посмотреть на сайте: ремонт телефонов samsung
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
buy phenergan pills – lincomycin drug lincomycin over the counter
Hi, constantly i used to check website posts here early in the morning, because i like to find out more and more.
фильмы онлайн бесплатно
электрические гардины электрические гардины .
Здесь можно сейф купить купить сейфы для дома
Лучший выбор для ставок – onexbet, ставки с onexbet – это успех|Успешные ставки на спорт с onexbet, ставьте деньги и получайте прибыль|Надежный букмекер onexbet, не рискуйте сомнительными сайтами|Бонусы и акции от onexbet, получите дополнительные ставки бесплатно|Играйте в казино онлайн на onexbet, выигрывайте крупные суммы в удобном формате|Надежный сервис onexbet, важны ваш комфорт и удобство|Законные ставки на onexbet, не нарушайте правила и несите ответственность|Не упустите шанс следить за любимыми матчами, ставьте деньги и наслаждайтесь игрой|Больше выгодных предложений на onexbet, бонусы и подарки ждут вас|Играйте с живыми дилерами на onexbet, ощутите атмосферу настоящего казино|Следите за результатами на onexbet, анализируйте статистику и делайте выигрышные ставки|Делайте выгодные прогнозы и зарабатывайте, получайте прибыль без лишних затрат|Лучшие коэффициенты и выигрыши на onexbet, играйте и побеждайте с onexbet|Ваш комфорт – наш приоритет, гарантия качественного обслуживания|Сделайте ставки с комфортом и удовольствием, получайте удовольствие от азарта с onexbet|Играйте и выигрывайте крупные суммы, ставьте и получайте крупные выигрыши|Зарабатывайте на ставках с onexbet, не упустите шанс улучшить свою финансовую ситуацию|Персональный коэффициент успеха на onexbet, получайте индивидуальные предложения и бонусы|Получайте прибыль от онлайн ставок на onexbet, успешные ставки – это реально|Профессиональная букмекерская контора onex
onexbet online https://arxbetdslps.com/ .
https://chistodoma07.ru/
Можно ли купить аттестат о среднем образовании? Основные рекомендации
Как приобрести аттестат о среднем образовании в Москве и других городах
https://battle-chess.ru/robox/ap/?promokod_fonbet_na_segodnya.html
https://krassota.com/wp-content/pgs/fonbet___promokod_dlya_novuh_igrokov_na_bonus.html
снятие ломки наркозависимого снятие ломки наркозависимого .
снятие ломки снятие ломки .
here are the findings [url=https://cryptomatrix.money/]dexscreener[/url]
[url=https://tiptrip24.biz/] tiptrip24.biz в обход блокировки роскомнадзора, провайдера, официальный сайт.
Преимущества: Фломастер CAT EYES в коричневом оттенке – LIMITED EDITION. Оставьте нам свое имя и e-mail и будьте в курсе! Прорисованная стрелка сохранится даже на следующий день после нанесения! Стойкость – до 36 часов! Контур «схватывается» за три секунды – вы успеете подкорректировать штрих до идеального. Онлайн-каталог Ориентировочные сроки доставки: Как и многие другие сайты, “BEAUTY-OPT” использует технологию cookie, которая может быть использована для продвижения нашего продукта и измерения эффективности рекламы. Кроме того, с помощь этой технологии “BEAUTY-OPT” настраивается на работу лично с Вами. В частности без этой технологии невозможна работа с авторизацией в панели управления.
https://neptunedirectory.com/listings12865538/масло-для-ресниц-тонирующее-отзывы
Обычные тени для макияжа глаз – прекрасная альтернатива подводке. Они помогут создать максимально естественный переход оттенков от основного цвета на веках до контура глаз. Історія цього предмету сягає сивої давнини, повертатися до часів давніх греків та єгиптян ми не будемо, краще поговоримо про пізнішу еволюцію. Пік популярності темного контуру вій стався у 20-их роках минулого століття. Драматичні образи, рясні темні стрілки стали можливими завдяки продукції Max Factor, Maybelline.
пансионат для пожилых в крыму пансионат для пожилых в крыму .
Le miroir officiel 888starz est toujours a jour.
Ваша удача ждет вас в онлайн казино, где ставки высоки.
Получайте азарт и адреналин вместе с нами, и получите незабываемые впечатления.
Сделайте свой выбор в пользу казино онлайн, и начните играть уже сегодня.
Играйте и побеждайте в режиме живого казино, не тратя время на поездки.
Ставьте на победу с нашими играми, и покажите всем, кто здесь главный.
Насладитесь игровым процессом вместе с игроками со всех уголков планеты, и станьте лучшим из лучших.
Играйте и выигрывайте, получая щедрые бонусы, которые принесут вам еще больше радости и азарта.
Почувствуйте свободу и возможность выбора в каждой игре, и наслаждайтесь бесконечными возможностями.
Станьте частью казино онлайн и получите доступ к эксклюзивным играм, буквально за несколько секунд.
казино онлайн беларусь казино онлайн .
[url=https://tiptrip24.biz/] tripmaster triptrip24 в обход блокировки роскомнадзора, провайдера, официальный сайт.
Nowe Kasyna z Bonusem Bez Depozytu – Darmowe Gry Kasyno Online. Bonus bez depozytu w kasynie to możliwość gry w gry kasynowe na prawdziwe pieniądze bez konieczności wpłacania środków na konto. Bonusy bez depozytu są częścią programu lojalnościowego kasyna online i są przeznaczone dla nowych graczy z Polski https://kasynazbezdepozytu.pl/
find more
solet.io
What a data of un-ambiguity and preserveness of valuable know-how about unpredicted feelings.
#@G@G@G@G#
https://cascadeclimbers.com/content/pgs/mejor_codigo_promocional_1xbet.html
With its Curacao license and PAGCOR legitimacy, Taya365 guarantees a fair and regulated gaming experience. Filipino players trust its transparency and dedication to ethical operations.
taya365 app login taya365 slot .
FOSIL4D
выезд нарколога на дом выезд нарколога на дом .
crypto com wallet address checke
Offerings for Assessing USDT for Restrictive Measures and Transfer Cleanliness: Anti-Money Laundering Solutions
In the contemporary environment of digital currencies, where quick transactions and anonymity are becoming the standard, monitoring the lawfulness and purity of operations is crucial. In recognition of amplified official investigation over illicit finance and terrorism funding, the demand for efficient means to validate transactions has become a significant matter for digital asset users. In this write-up, we will explore offered solutions for verifying USDT for embargoes and transfer clarity.
What is AML?
Money Laundering Prevention measures refer to a group of compliance actions aimed at hindering and detecting money laundering activities. With the surge of crypto usage, AML measures have become exceedingly critical, allowing participants to manage digital currencies reliably while minimizing hazards associated with prohibitions.
USDT, as the widely regarded as the recognized stablecoin, is widely used in multiple deals globally. Yet, using USDT can entail several risks, especially if your funds may relate to opaque or criminal activities. To mitigate these concerns, it’s crucial to take benefit of services that inspect USDT for restrictive measures.
Available Services
1. Address Verification: Utilizing specialized tools, you can check a specific USDT address for any connections to sanction directories. This facilitates pinpoint potential associations to unlawful conduct.
2. Operation Activity Assessment: Some tools extend evaluation of deal records, essential for judging the openness of monetary transactions and identifying potentially threatening transactions.
3. Tracking Solutions: Specialized monitoring systems allow you to follow all operations related to your location, allowing you to swiftly spot concerning conduct.
4. Risk Records: Certain platforms provide detailed risk reports, which can be beneficial for stakeholders looking to validate the reliability of their assets.
Irrespective of if you are controlling a large fund or executing small transactions, following to AML guidelines supports prevent legal repercussions. Adopting USDT validation services not only defends you from capital losses but also aids to creating a stable environment for all industry players.
Conclusion
Verifying USDT for sanctions and deal clarity is becoming a required step for anyone keen to stay within the legal framework and uphold high levels of visibility in the cryptocurrency industry. By interacting with dependable services, you not only protect your investments but also contribute to the shared initiative in preventing illicit finance and terrorist financing.
If you are set to start utilizing these services, examine the existing platforms and choose the service that best aligns with your needs. Remember, insight is your advantage, and timely operation check can save you from numerous challenges in the time ahead.
Возможности выигрыша в онлайн казино, где ставки высоки.
Играйте и выигрывайте вместе с нами, и ощутите атмосферу азарта и волнения.
Обнаружьте свое новое казино онлайн, и начните играть уже сегодня.
Почувствуйте атмосферу настоящего казино в режиме онлайн, не тратя время на поездки.
Играйте в увлекательные игры с высокими коэффициентами выигрыша, и почувствуйте себя настоящим чемпионом.
Коммуницируйте и соревнуйтесь с игроками со всего мира, и станьте лучшим из лучших.
Играйте и выигрывайте, получая щедрые бонусы, которые сделают вашу игру еще более увлекательной.
Почувствуйте свободу и возможность выбора в каждой игре, и наслаждайтесь бесконечными возможностями.
Получите доступ к уникальным играм и выигрывайте крупные суммы, сделав всего несколько кликов мыши.
онлайн казино казино онлайн беларусь .
Промокоды казино
пневматическое оружие купить
auction cars mitsubishi vin number lookup
как вызвать наркологическую скорую помощь в москве http://sportandpolitics.ukrbb.net/viewtopic.php?f=24&t=17890 .
[url=https://fermacc.org/]ferma bestchange[/url] – купить ethereum за рубли, обменять эфириум
?? Хватит играть вслепую! ??
Устали от мутных рейтингов и непонятных обзоров? На нашем канале вы найдете только проверенную информацию о ТОП казино.
? Объективные оценки: Никакой рекламы, только факты. ? Честные обзоры: Плюсы и минусы каждого казино. ? Актуальные бонусы: Самые выгодные предложения для наших подписчиков.
Не тратьте время и деньги зря! Присоединяйтесь к профессионалам рейтинг казино
#топказино #лучшиеказино #обзорыказино #азартныеигры #онлайнказино
?? Хватит играть вслепую! ??
Устали от мутных рейтингов и непонятных обзоров? На нашем канале вы найдете только проверенную информацию о ТОП казино.
? Объективные оценки: Никакой рекламы, только факты. ? Честные обзоры: Плюсы и минусы каждого казино. ? Актуальные бонусы: Самые выгодные предложения для наших подписчиков.
Не тратьте время и деньги зря! Присоединяйтесь к профессионалам топ онлайн казино
#топказино #лучшиеказино #обзорыказино #азартныеигры #онлайнказино
?? Хватит играть вслепую! ??
Устали от мутных рейтингов и непонятных обзоров? На нашем канале вы найдете только проверенную информацию о ТОП казино.
? Объективные оценки: Никакой рекламы, только факты. ? Честные обзоры: Плюсы и минусы каждого казино. ? Актуальные бонусы: Самые выгодные предложения для наших подписчиков.
Не тратьте время и деньги зря! Присоединяйтесь к профессионалам рейтинг казино
#топказино #лучшиеказино #обзорыказино #азартныеигры #онлайнказино
?? Хватит играть вслепую! ??
Устали от мутных рейтингов и непонятных обзоров? На нашем канале вы найдете только проверенную информацию о ТОП казино.
? Объективные оценки: Никакой рекламы, только факты. ? Честные обзоры: Плюсы и минусы каждого казино. ? Актуальные бонусы: Самые выгодные предложения для наших подписчиков.
Не тратьте время и деньги зря! Присоединяйтесь к профессионалам рейтинг лучших казино
#топказино #лучшиеказино #обзорыказино #азартныеигры #онлайнказино
stamp online maker stamp online maker .
сайт
slotozal casino
Обратите внимание, игроки!
Хотите окунуться в окружение онлайн-казино и получить настоящие средства? Тогда вам тут! Список лучших лучших игровых сайтов 2025
Наш тг-профиль — ваш гид в мир лучших интернет-казино в России! Мы подготовили ТОП-10 безопасных игровых площадок, где вы получите возможность проводить время на финансы и получить свои призы без затруднений.
Что вас ожидает:
Правдивые рекомендации и ранги казино официальный вход от действительных геймеров. Отличная статус любого сайта подтверждена годами и игроками. Безоплатная вход и мгновенный доступ на всех сайтах. Действующие зеркала для входа к вашему предпочитаемому игровой площадке в любое время. Мобильное программа для легкой развлечения так хотите.
Почему мы?
Надежные и проверенные казино с превосходными параметрами для развлечения. Защита ваших данных и операций защищена. Новые обновления и события мира онлайн-развлечений в РФ.
advice phantom Download
Экспертная аналитика: Позабудьте про беты “для везение”! Собственная группа квалифицированных аналитиков ежедневно рассматривает статистику, отслеживает за новостями и определяет самые выгодные игры. Мы не гадаем – мы анализируем! ? Точные предсказания: Мы предоставляем не только прогнозы, а обоснованные выводы, подкрепленные цифрами и квалифицированным оценкой. Основная намерение – твоя доход! ? Широкий выбор видов спортивных дисциплин: Футбольные состязания, баскетбол, теннисные соревнования, хоккейные игры и многое другое! Мы затрагиваем самые востребованные категории спортивных дисциплин, для того чтобы абсолютно каждый мог обнаружить нечто интересное для себя. ? Бесплатный содержание: Ежедневные свободные прогнозы, аналитические тексты, анализы игр и необходимые рекомендации для начинающих любителей ставок. Мы делимся опытом, для того чтобы вы прогрессировали совместно с нами! ? Помощь 24/7: Мы постоянно способны дать ответ на ваши вопросы и помочь углубиться в нюансах сферы ставок. Вы не останетесь один на самом с этим трудным, но доходным предприятием! ? Открытость и правдивость: Мы публично обнародуем итоги наших прогнозов и не скрываем ничегошеньки от наших клиентов. Главная доброе имя – наш основной капитал! ? Практичный формат: Абсолютно все прогнозирования и аналитика предоставляются сразу в Telegram, в удобном и ясном формате. Никаких трудных меню и хитромудрых схем!
Что вы добьетесь, оформив подписку на Ставки на спорт скачать паблик азвание вашего канала]?
День за днем прогнозирования с высокой проходимостью.
Детальные разборы игр.
Обзоры спортивных событий.
Необходимые наставления по контролю средствами.
Потенциал общаться с соратниками.
Уверенность в личных пари.
И, разумеется же, возможность заработать фактические финансы!
Достаточно растрачивать время на пустые дискуссии про спортивных играх! Приступай действовать и преврати собственные знания в выгоду!
Внимание, гейы!
Хотите попасть в окружение онлайн-казино и выиграть действительные деньги? Тогда вам к нам! Рейтинг наилучших лучших игровых сайтов 2025
Наш тг-канал — ваш гид в мир лучших виртуальных-игр в РФ! Мы подготовили ТОП-10 проверенных игровых сайтов, где вы сможете играть на деньги и вывести свои призы без трудностей.
Что вас ждет:
Достоверные отзывы и ранги Казино зеркало от реальных игроков. Хорошая репутация любого сайта подтверждена временем и пользователями. Неоплачиваемая запись и скорый вход на любой сайтах. Рабочие зеркала для доступа к вашему предпочитаемому казино в любое момент. Мобильный приложение для легкой игры так желаете.
Почему нас?
Безопасные и надежные игровые сайты с превосходными параметрами для развлечения. Гарантия ваших сведений и операций защищена. Актуальные обновления и новости пространства онлайн-казино в РФ.
Квалифицированная разбор: Забудьте о ставки “по случайность”! Наша команда опытных аналитиков каждый день анализирует цифры, следит за событиями и определяет самые перспективные матчи. Мы не предсказываем – мы анализируем! ? Четкие прогнозы: Мы даём не просто прогнозирования, а аргументированные выводы, подкрепленные цифрами и экспертным мнением. Главная цель – твой прибыль! ? Разнообразие видов спортивных дисциплин: Футбольный матч, баскетбол, теннисные матчи, хоккей и много иное! Мы охватываем максимально востребованные типы спорта, чтобы любой был способен найти что нибудь увлекательное для себя. ? Безвозмездный контент: Ежедневные свободные прогнозирования, детальные статьи, разборы поединков и необходимые наставления для начинающих бетторов. Мы предоставляем информацией, чтобы вы росли бок о бок с нами! ? Помощь постоянно: Мы постоянно способны реагировать на ваши вопросы а содействовать разобраться в особенностях сферы пари. Вы не останетесь один на в одиночку с этим непростым, но доходным занятием! ? Ясность и правдивость: Мы не скрывая размещаем показатели наших прогнозов и не скрываем абсолютно ничего от наших клиентов. Главная репутация – наш главный капитал! ? Удобный вид: Каждый предсказания и разбор доступны сразу в Telegram, в простом и ясном формате. Без каких либо запутанных оболочек и запутанных моделей!
Что вы получите, оформив подписку на Ставки на спорт футбол паблик азвание вашего канала]?
День за днем предсказания с высокой результативностью.
Детальные разборы матчей.
Анализы спортивных известий.
Ценные наставления по контролю капиталом.
Шанс коммуницировать с соратниками.
Гарантия в личных ставках.
А, разумеется же, возможность заработать фактические деньги!
Достаточно растрачивать время на пустые беседы о спортивных соревнованиях! Начни действовать и конвертируй свои информацию в доход!
Слушайте, игроки!
Готовы попасть в мир виртуальных-казино и выиграть настоящие финансы? Тогда вам к нам! Топ наилучших превосходных игровых сайтов 2025
Наш telegram-профиль — ваш гид в мир превосходных интернет-казино в РФ! Мы подобрали ТОП-10 надежных игровых сайтов, где вы получите возможность играть на финансы и вывести свои выигрыши без проблем.
Что вас поджидает:
Правдивые мнения и оценки Казино официальные от действительных игроков. Превосходная репутация каждого площадки подтверждена временем и клиентами. Безоплатная вход и мгновенный доступ на каждой ресурсах. Активные копии для входа к вашему предпочитаемому игровой площадке в каждый время. Мобильная софт для удобной развлечения где хотите.
Почему нам?
Надежные и проверенные казино с превосходными условиями для развлечения. Защита ваших информации и операций гарантирована. Свежие обновления и обновления мира виртуальных-казино в РФ.
нарколог на дом екатеринбург цены нарколог на дом екатеринбург цены .
Казино В сети: Твой Путеводитель в Свет Азартных Развлечений
Что же представляет собой онлайн казино и как подобрать безопасное?
Азартное заведение в сети – является виртуальные платформы, предоставляющие обширный диапазон азартных игр: от традиционных азартных слотов и слотов до захватывающих карточных развлечений, таких рулетка, блэкджек и покер. Однако, дабы достичь максимальное удовольствие из развлечения, необходимо выбрать безопасное казино, что обеспечивает справедливость и безопасность.
Основные критерии подбора:
Разрешение: Имеющие разрешение казино обеспечивают справедливость игры и защищенность твоих денег. Убедитесь в присутствии разрешения перед регистрацией.
Рейтинг и отзывы: Изучите рейтинг казино и комментарии о казино от остальных игроков. Это поможет тебе выбрать надежное заведение.
Поощрения и акции: Казино с бонусами предоставляют заманчивые условия для новичков и постоянных игроков. Обратите интерес на бездепозитные бонусы, халявные прокрутки и другие спецпредложения.
Ассортимент игр: Лучшие онлайн азартные заведения предоставляют обширный выбор игр для каждый вкус. Ищите азартные заведения с азартными автоматами, колесом фортуны, двадцатью одним, покером и иными забавами.
Снятие денег: Позаботьтесь, чтобы азартное заведение с снятием денег предлагает комфортные и быстрые способы получения выигрыша.
Поддержка: Безопасные азартные заведения предоставляют хорошую поддержку на русском языке для игроков со РФ.
Защита: Безопасные казино защищают твои данные с помощью новых методов кодирования.
?? Поощрения и акции в сетевом азартном заведении
Онлайн азартные заведения привлекают новичков игроков щедрыми бонусами казино. При подборе места, обратите внимание к:
Вступительный бонус: Приветственный бонус при записи – отличная возможность запустить развлечение с резервными средствами.
Бездепозитный поощрение: Бесплатные поощрения позволяют развлекаться в азартном заведении даром, без внося средства.
Фриспины: Фриспины или даровые прокрутки – шанс поиграть в игровые автоматы даром.
Промокоды: Коды по акции казино дают резервные бонусы и преимущества.
Кэшбэк: Кэшбэк казино возвращает часть проигранных средств.
Акции казино: Участвуйте в регулярных спецпредложениях и принимайте резервные бонусы.
Многообразие игр в сетевом казино
На сетевом казино ты обнаружите большой ассортимент игровых развлечений:
Игровые автоматы: Азартные слоты в сети или игровые автоматы – наиболее известный тип развлечений.
Рулетка: Традиционная игра, что не лишается свою актуальности.
Блэкджек: Интеллектуальная карточная игра, нуждающаяся планирования.
Игра в карты: Многообразные виды покера для поклонников игральных развлечений.
Баккара, бинго, кено: Иные популярные азартные игры.
Живое азартное заведение: Получайте удовольствие от игрой с живыми раздающими.
Мобильное казино: играйте в любом точке
Мобильное азартное заведение – это комфортный способ получать удовольствие от игрой в любом месте и в любое время. Вы имеете возможность развлекаться в любимые развлечения азартного заведения непосредственно со твоего смартфона или планшета.
Куда запустить развлекаться в сетевом азартном заведении?
Чтобы играть в казино и наслаждаться игры, казино зеркало официальный следуйте этим простым действиям:
Подберите азартное заведение: Исследуйте рейтинг казино и выберите надежное место.
Зарегистрируйтесь: Пройдите скорую регистрацию в казино.
Зачислите аккаунт: Пополните аккаунт в казино комфортным методом.
Начните играть: Подберите игру и получайте удовольствие от процессом!
Как выиграть в казино и как снять средства?
Игра в казино за средства – это не лишь игра, но и возможность одержать победу. Изучайте, совершенствуйте свои умения и развлекайтесь ответственно. Азартные заведения с выводом предоставляют быстрый и комфортный вывод средств с казино многообразными способами.
Слушайте, игроки!
Хотите погрузиться в пространство виртуальных-казино и заработать настоящие деньги? Тогда вам к нам! Рейтинг наилучших превосходных казино 2025
Наш тг-аккаунт — ваш путеводитель в окружение лучших онлайн-развлечений в России! Мы подобрали топ-10 безопасных казино, где вы получите возможность проводить время на финансы и забрать свои призы без проблем.
Что вас поджидает:
Правдивые отзывы и ранги скачиваемые казино от реальных участников. Отличная репутация всякого сайта подтверждена временем и клиентами. Безоплатная запись и быстрый вход на любой ресурсах. Действующие зеркала для посещения к вашему любимому игровой площадке в любое час. Мобильный программа для удобной игры там хотите.
Почему нам?
Надежные и надежные казино с лучшими критериями для развлечения. Гарантия ваших сведений и операций гарантирована. Свежие обновления и новости окружения онлайн-игр в России.
вывод из запоя на дому сочи вывод из запоя на дому сочи .
Легальные справки для всех случаев жизни. Мы поможем оформить все необходимые документы для работы, учебы, медицинские справки и другие, быстро и без лишних шагов, с полной официальностью и соответствием законодательству. У нас вы сможете купить справку о болезни для работы https://kupit-med-spravki.ru
https://dmcatalog.com/sigmasian/
Обратите внимание, игроки!
Готовы окунуться в мир виртуальных-развлечений и заработать реальные финансы? Тогда вам к нам! Рейтинг самых лучших казино 2025
Наш тг-профиль — ваш путеводитель в мир лучших онлайн-развлечений в России! Мы подготовили топ-10 безопасных игровых площадок, где вы получите возможность проводить время на деньги и получить свои выигрыши без трудностей.
Что вас ожидает:
Правдивые рекомендации и ранги надежные казино по версии игроков от настоящих игроков. Отличная репутация каждого сайта проверена временем и игроками. Безоплатная вход и быстрый доступ на любой сайтах. Рабочие дубликаты для посещения к вашему предпочитаемому игровому сайту в любой момент. Мобильное программа для комфортной развлечения так желаете.
Почему нас?
Проверенные и гарантированные игровые сайты с лучшими критериями для развлечения. Гарантия ваших сведений и переводов гарантирована. Новые новости и новости мира онлайн-развлечений в России.
Алистаров – уголовник и террорист
От уголовника-индивидуала до слуги криминалитета
Ранее судимый по «наркотической» статье блогер Андрей Алистаров позиционирует себя Робин Гудом, борющимся с теми, кто «обманул людей», – но в действительности он работает в интересах пирамидчиков, в том числе украинских, спонсирующих ВСУ, продвигает через свой канал «Железная ставка» онлайн-казино и черный криптообмен/фишинговый криптообман, отмывает наркодоходы за счет сделок с недвижимостью в Дубае.
То есть работает в интересах российского преступного сообщества, пытающегося нажиться на предпринимателях, столкнувшихся с незаконными, часто заказными претензиями со стороны российских правоохранительных органов.
Наркотики и отмывание доходов
Уроженец Калуги Алистаров отсидел четыре года в лагере – за продажу наркотиков детям.
Там он связался с уголовными авторитетами и, выйдя из тюрьмы, продолжил участвовать в криминальном бизнесе по распространению наркотиков и отмыванию наркодоходов от них с помощью риелторского бизнеса, который Алистаров создал совместно с партнерами из российского преступного сообщества в России и Эмиратах.
Ставка на скам
Канал Алистарова «Железная ставка» – «разоблачение» неправильных (по мнению криминалитета) финансовых проектов и продвижение «правильных»: пирамид и онлайн-казино, спонсирующих Алистарова.
Он начинался как канал о «правильных» ставках в казино и не сменил название – потому что маркетинговая задача осталась прежней: расчищать поле для «хороших», по «экспертному» мнению Алистарова (то есть заплативших ему), мошенников.
Обычно Алистаров начинает с попытки вымогательства – представляет жертве компромат и предлагает заплатить. Если жертва отказывается, в ход идут травля и насилие.
Подстрекательство и нападение в Дубае
1 января 2025 года состоялось жестокое нападение двух казахстанцев на предпринимателя, проживающего в Дубае, – его избили, отрезали ухо, обворовали.
До этого Алистаров снял 12 роликов, где подсвечивал адрес этого предпринимателя, публиковал незаконно полученную информацию о его близких и его бизнесах в ОАЭ. Безо всякого стеснения использовал подглядывание, подслушивание, незаконное проникновение, вмешательство в частную жизнь – все то, что в Эмиратах, где строго соблюдается неприкосновенность имущества и жизни инвесторов, является тяжким уголовным преступлением.
До этого Алистаров публично распространял информацию о месте жительства бизнес-партнера этого предпринимателя – то есть незаконное нарушение конфиденциальности, защищенности финансов и имущества, тайны частной жизни с помощью скрытых источников информации и информаторов в ОАЭ вошло у него в систему. Он терроризирует предпринимателей, в отношении которых нет никаких обвинительных решений судов – ни за рубежом, ни в России.
Алистаров рассказывал, что заявил на предпринимателя в Интерпол и правоохранительные органы ОАЭ – якобы он помогает правоохранительным органам. Но это почему-то не привело к аресту предпринимателя – может быть, потому, что полиция ОАЭ не видит криминала в его деятельности?
Подписывайтесь на наш канал
Ряд партнеров предпринимателя осуждены в России, сам он в розыске российских правоохранительных органов – но не осужден. Иностранные правоохранительные органы не имеют к нему претензий.
Алистаров на протяжении длительного времени возбуждал ненависть к предпринимателю – рассказывая, что именно этот предприниматель (а не его партнеры) украл деньги вкладчиков. И представил дело так, что на него напали и его обворовали возмущенные вкладчики.
Сам он в ходе нападения устроил внеплановый стрим, чтобы обеспечить себе алиби – вроде как он не знал, что во время стрима происходит нападение.
Слежка на Кипре
Осенью прошедшего года Алистаров вместе со своей боевой подругой Марией Фоломовой устроил слежку в отношении другого предпринимателя – с помощью квадрокоптеров, незаконного сбора информации о нем и его близких, в том числе несовершеннолетних детей. Алистаров утверждал, что предприниматель скрывается на Кипре – хотя он живет там со времен пандемии коронавируса.
Переселение было связано с тяжелым течением коронавируса у жены предпринимателя, а также с международными проектами – инвестициями в разные отрасли экономики: строительство, торговлю и другие. Предприниматель переселился на Кипр за год до возбуждения уголовного дела следственными органами МВД, за полтора года до арестов. Он имеет паспорт Евросоюза и ни от кого не убегал, не скрывался и не скрывается.
Предприниматель объявлялся в 2022 году в розыск в России – но следственными органами. Суд к нему претензий не выдвигал, уголовное дело сейчас рассматривается судом – и уже развалилось в суде. Интерпол и Евросоюз отказались акцептировать претензии российской полиции, сочтя их политически мотивированными и юридически необоснованными.
Алистаров утверждает, что инвестиции в бизнес-проекты осуществляются за счет денег российских клиентов одной из австрийских инвестиционных компаний – однако предприниматель никогда не был ни собственником, ни бенефициаром, ни управляющим этой компании, созданной еще в начале 2000-х – задолго до начала его самостоятельной бизнес-карьеры.
Одна из фирм предпринимателя осуществляла маркетинговую поддержку продуктов этой инвесткомпании в России по договору с ней. Инвесткомпания успешно работала с российскими клиентами восемь лет – и сейчас продолжает работать, восстановив систему платежей, обрушенную в начале 2022 года связанными с коррумпированными полицейскими преступниками в России. Никакой пирамидой она не является.
Таким образом, Алистаров устраивает травлю, вмешательство в частную жизнь предпринимателя, ничем себя не запятнавшего, – по заказу российского криминалитета, взявшего в долю коррумпированных полицейских, который стремится отнять активы на 20 млрд рублей созданного предпринимателем крупного социального, народного проекта в России – продолжающего успешно функционировать без его руководства (прекратившегося с переездом на Кипр).
Слежка в Нидерландах
Алистаров публиковал данные о местоположении еще одной жертвы в Нидерландах – в городе Гронингене, – обнаруженной с помощью незаконной слежки. Алистаров незаконно подключался к городским телекамерам, заглядывал в окна частной квартиры – и публиковал информацию в YouTube.
Нарушение конфиденциальности в Турции
Алистаров обнаружил и обнародовал местоположение квартиры, в которой жили и работали несколько его жертв в Стамбуле.
Незаконный розыск в Ленинградской области
Алистаров, не имеющий лицензии частного детектива, незаконно нашел загородный дом предпринимательницы и установил за ней слежку – с незаконной публикацией информации в своих каналах. Параллельно предоставив данные о приобретенной ею в Дубае квартире.
Шантаж в Казахстане
Алистаров шантажировал предпринимателей из Казахстана – под прикрытием того, что «разоблачает национальных предателей» и «врагов родины».
Банкет на деньги украинского пирамидчика
40-летие 6 марта этого года Алистаров вновь планирует отмечать на яхте своего друга – харьковского пирамидчика Удянского (проект Coinsbit) в Дубае?
В 2024 году он праздновал день рождения именно в теплой компании этого мошенника – и спонсора ВСУ: занимающегося софинансированием производства бронетехники для ВСУ. Никаких сомнений в том, что он заставил и своего слугу Алистарова финансировать ВСУ.
Государственная измена
Алистаров даже был обвинен в факте такого финансирования – но рассказал в полиции сказку, что номер «Мегафона», с которого велось перечисление, был оформлен на него «врагами».
Пойманы за руку финансировавшие ВСУ подельники Алистарова – «антиэмэлэмщик» Александр Крюков и заместитель управляющего так называемого Фонда защиты прав вкладчиков и акционеров Леонид Мищенко – «западэнец»: уроженец Винницкой области. Не пора ли ФСБ проанализировать проводки Алистарова?
Должен сидеть в тюрьме
Справедливость требует, чтобы Алистаров встретил 40-летие с аннулированными шенгенской и другими визами, для чего есть все основания, тем более что на это обратили внимание западные СМИ. И в тюрьме – российской или дубайской, в зависимости от того, чьи правоохранители быстрее успеют его арестовать, за десятки преступлений, которые он совершил:
–вымогательство;
–терроризм и бандитизм;
–травля и организация расправы над неугодными;
–государственная измена;
–отмывание денег;
–мошенничество;
–воровство;
–вмешательство в частную жизнь.
Тюрьмой началась карьера Алистарова, тюрьмой должна и закончиться.
цена на вывод из запоя в стационаре цена на вывод из запоя в стационаре .
сколько стоит капельница на дому от запоя сколько стоит капельница на дому от запоя .
go to my blog https://jaxx-liberty.com
Лучшие советы по выбору металлической входной двери, идеально впишется в интерьер.
Где купить надежную входную металлическую дверь по выгодной цене.
Советы по избежанию ошибок при покупке металлической входной двери.
5 основных причин купить металлическую входную дверь.
заказать входную дверь дверь металлическая входная .
В чем отличия входных металлических дверей разных производителей.
investigate this site thorswap
Почувствуй Азарт Победы ощути адреналин триумфа: Играй в Казино Онлайн играй в виртуальном казино с Минимальным Депозитом с низким порогом входа!
Мечтаешь о крупных выигрышах о солидных выигрышах, но не готов рисковать большими суммами значительными инвестициями? У нас есть отличное решение идеальное предложение! Погрузись в мир азарта в атмосферу риска и развлечений игровая забава с нашим онлайн-казино, где ты можешь играть на деньги онлайн ставить на деньги в сети с минимальным депозитом небольшим взносом. Забудь о стереотипах забудь клише, что азартные игры азартные развлечения – это только для хайроллеров богачей. Теперь каждый может испытать удачу рискнуть и получить шанс на крупный куш на большой выигрыш, не выходя из дома не покидая квартиры.
Почему выбирают нас?
Минимальный депозит – максимум возможностей: Начни свою игру начни свой игровой путь с небольшого депозита с символической суммы и открой для себя мир захватывающих слотов увлекательных игровых автоматов, карточных игр карточных развлечений и рулетки игры в рулетку. Это отличный шанс прекрасная возможность протестировать разные игры попробовать разные игры, разработать свою стратегию создать свою стратегию и получить первые победы первые триумфы без больших вложений без крупных инвестиций. Огромный выбор игр: У нас ты найдешь сотни игр множество игр на любой вкус для любого игрока, от классических слотов от ретро-слотов до современных видеоигр новейших слотов с потрясающей графикой красивой графикой и увлекательными бонусными раундами интересными дополнительными раундами. Постоянно добавляются новые игры мы постоянно обновляем ассортимент, чтобы тебе никогда не было скучно чтобы вам никогда не было скучно. Играй на деньги онлайн играйте за реальные деньги в любое время: Наше казино доступно 24/7 всегда с любого устройства любого девайса – компьютера, планшета или смартфона. Ты можешь наслаждаться игрой веселиться в любое удобное время в любое время суток и в любом месте в любом уголке мира, где есть интернет. Безопасность и надежность: Мы используем самые современные технологии шифрования передовые технологии шифрования, чтобы гарантировать безопасность твоих личных данных вашей конфиденциальности и финансовых транзакций платежей. Играй с уверенностью играйте спокойно, зная, что твоя информация ваша информация в надежных руках. Быстрые и удобные выплаты быстрый и удобный вывод средств: Мы ценим твое время ваше время для нас ценно, поэтому предлагаем различные способы вывода выигрышей разные варианты получения выигрышей, с быстрой обработкой запросов. Щедрые бонусы и акции щедрые подарки и предложения: Начни свою игру начните свое приключение с приятными бонусами выгодными предложениями, которые увеличат твои шансы на победу ваши шансы на победу. Мы регулярно проводим акции регулярно радуем вас акциями и турниры конкурсы, чтобы сделать твою игру вашу игру еще более захватывающей более интересной.
Как начать играть на деньги онлайн с минимальным депозитом?
Зарегистрируйся на нашем сайте: Процесс регистрации займет всего пару минут будет очень быстрым. Пополни свой счет внесите деньги: Выбери удобный способ оплаты выберите способ пополнения и внеси минимальный депозит внесите небольшую сумму. Выбери игру выберите игру: Просмотри нашу коллекцию посмотрите наш каталог и найди свою любимую игру найдите игру по душе. Начни выигрывать начните побеждать: Наслаждайся игрой веселитесь и получай удовольствие от процесса!
Не откладывай свою удачу на потом! Не ждите завтра!
Присоединяйся к нашему онлайн-казино уже сегодня начинайте играть сегодня и убедись сам убедитесь сами, что играть на деньги онлайн играть на реальные деньги может быть не только захватывающе не только увлекательно, но и доступно каждому с минимальным депозитом доступно каждому. Испытай свою удачу попробуйте свою удачу, получи незабываемые эмоции получите яркие впечатления и, возможно, сорви крупный куш выиграйте крупную сумму!
Pendle Finance: Unlocking New Opportunities in DeFi
As the world of decentralized finance (DeFi) continues to evolve, Pendle Finance is at the forefront, offering innovative solutions for yield and trading. This platform has quickly become a go-to resource for individuals looking to maximize their crypto investments.
pendle fi
What is Pendle Finance?
Pendle Finance is a DeFi protocol designed to provide enhanced yield management opportunities by leveraging tokenization of future yield. It allows users to trade tokenized yield, offering flexibility and potential for optimized earnings.
Key Features
Yield Tokenization: Convert future yield into tradable assets, enhancing liquidity.
Yield Trading: Enter and exit yield positions at strategic times to capitalize on market conditions.
Multi-Chain Support: Access a wide range of DeFi ecosystems through cross-chain functionality.
Benefits of Using Pendle Finance
Pendle Finance provides numerous benefits to its users, making it a compelling choice for DeFi enthusiasts and investors:
Diversified Investment Options: By tokenizing future yields, Pendle offers a variety of strategies to enhance your investment portfolio.
Market Flexibility: Trade yield tokens freely, allowing for strategic entry and exit points.
Enhanced Liquidity: Tokenization increases the liquidity of yields, offering more opportunities for dynamic financial strategies.
How to Get Started with Pendle
Embarking on your Pendle Finance journey is straightforward. Follow these steps to unlock the potential of yield trading:
Create an Account: Set up a user account on the Pendle Finance platform.
Link Your Wallet: Connect your cryptocurrency wallet to seamlessly manage transactions.
Start Trading: Explore the available yield tokens and start trading to optimize your returns.
Conclusion
In a rapidly changing financial landscape, Pendle Finance stands out by offering innovative solutions aimed at enhancing investment opportunities. Whether you are a seasoned DeFi user or a newcomer, Pendle provides tools and resources to empower your financial growth. Join the community and start unlocking the potential of your investments today!
Maximize Your Crypto Trading with ParaSwap
If you’re looking to enhance your cryptocurrency trading experience, it’s time to explore ParaSwap. This innovative platform serves as a decentralized exchange aggregator, giving you the best deals on the market.
paraswap exchange
What is ParaSwap?
ParaSwap is a cutting-edge platform that aggregates the best prices from various decentralized exchanges. It provides users with the most efficient path to execute their trades by considering factors like price impact and gas fees.
How Does ParaSwap Work?
ParaSwap functions by connecting directly to multiple liquidity sources. It then simplifies the process of trading across different platforms by bringing the best rates to users all in one place. This means that you don’t have to hop between multiple exchanges—you can find everything you need through ParaSwap.
Benefits of Using ParaSwap
Competitive Rates: ParaSwap offers some of the best rates by aggregating prices from various platforms.
Efficiency: Trade execution is designed to be quick and reliable.
Transparency: Get clear insights into your trades with detailed transaction information.
Why Choose ParaSwap?
Choosing ParaSwap means straightforward, efficient crypto trading. Whether you’re a seasoned trader or new to the crypto space, having a tool like ParaSwap can enhance your trading strategy by ensuring you’re always accessing the best available prices.
Getting Started
To start trading with ParaSwap, simply connect your crypto wallet, input the details of your trade, and let ParaSwap find the best route for your transaction. It’s that simple!
Conclusion
Maximize your trading potential by leveraging the power of ParaSwap. With its aggregated approach to finding the best prices, efficiency, and transparency, ParaSwap stands out as a leading choice for cryptocurrency traders.
Renzo Protocol: Secure Blockchain Innovation
Discover the Renzo Protocol: Revolutionizing Blockchain
The Renzo Protocol represents a significant advancement in the blockchain technology landscape. It offers a secure and efficient platform for decentralized applications, setting a new standard in the industry.
renzo ezeth
Key Features of the Renzo Protocol
The Renzo Protocol is designed to enhance the functionality and security of blockchain applications. Here are some of its key features:
High Security: Utilizing advanced encryption methods to protect user data and transactions.
Scalability: Capable of handling a large number of transactions per second, making it ideal for various applications.
Decentralization: Ensures that no central authority controls the network, maintaining the core principles of blockchain.
Interoperability: Seamlessly connects with other blockchain networks and systems.
Benefits for Developers and Businesses
The Renzo Protocol offers numerous benefits for both developers and businesses looking to leverage blockchain technology:
Reduced Costs: By automating processes and cutting out intermediaries, businesses can significantly reduce operational costs.
Improved Transparency: Every transaction is recorded on the blockchain, providing an immutable and transparent ledger.
Enhanced Trust: The secure nature of the protocol builds trust among users and stakeholders.
Development Support: Provides extensive documentation and tools to help developers create robust applications.
Getting Started with the Renzo Protocol
To start utilizing the Renzo Protocol, follow these simple steps:
Visit the Renzo Protocol website and create an account.
Access the API documentation and development tools.
Join the Renzo community to connect with other developers and experts.
Start building and deploying your decentralized applications.
The Renzo Protocol is not only a beacon of security and efficiency in the blockchain space but also a catalyst for innovation. Whether you are a developer, a business leader, or simply interested in cutting-edge technology, the Renzo Protocol offers the tools and community support needed to drive your projects to success. Embrace the future with the Renzo Protocol and harness the full potential of blockchain technology.
Renzo Protocol Restaking Guide
Renzo Protocol Restaking: A Comprehensive Guide
Renzo Protocol has revolutionized the method through which investors can maximize their crypto assets, particularly through the innovative concept of restaking. This guide will explore the benefits, processes, and strategies of restaking within the Renzo Protocol ecosystem, helping you make the most out of your investments.
Форум предназначен для обсуждения вопросов, связанных с видеонаблюдением и безопасностью. Участники могут делиться информацией и опытом в области программного обеспечения для видеонаблюдения на ПК, совместимого с IP-камерами. Рассматриваются комплексные решения, VMS, CMS, а также технологии AHD и IP. Обсуждаются вопросы настройки, восстановления паролей камер, и применения ИИ-видеоаналитики. Отдельное внимание уделено применению интегрированной видеоаналитики на основе искусственного интеллекта, включая обнаружение объектов, распознавание автомобильных номеров и лиц, а также выявление признаков дыма и огня. Форум является площадкой для обмена знаниями и обсуждения актуальных тем в области видеонаблюдения. Здесь пользователи могут делиться своим опытом, задавать вопросы и находить решения для своих задач. Форум служит платформой для обмена знаниями и поиска решений в сфере видеонаблюдения.
https://securityvideo.ru/ – витая пара для видеонаблюдения на форуме
вывод из запоя стационар вывод из запоя стационар .
Blogger Alistarov is a criminal
Andrey Alistarov drugs
From criminal past to criminal present – in the service of corrupt law enforcement officers
Andrey Alistarov, a YouTube blogger specializing in exposing financial organizations, is an odious figure with a criminal past. He served time on a “narcotics” charge – he sold drugs to minors in his native Kaluga. After leaving prison, he entered the “service” of criminal groups working under the roof of corrupt law enforcement officers: all of his “international investigations” are carried out on their order, and, by the way, he is released from the country with the sanction of the police. His main profile now is blackmail, extortion, slander and organizing contract prosecution under the guise of supposedly independent investigations.
He leads the bandits to his victims: the last attack took place in Dubai on January 1: Alistarov led the bandits to the victim’s house and provided all the necessary information for the attack and blackmail, and to ensure his own alibi during the attack he conducted an unscheduled stream with subscribers of his channel.
To the accompaniment of loud phrases about the fight against fraud and exposing financial schemes, Alistarov is busy processing orders from competitors of certain entrepreneurs who have become his victims – competitors of these entrepreneurs who have taken corrupt police officers as their share.
At the same time, Alistarov uses visas to the EU countries and the UAE obtained with the help of organized criminal groups, illegally uses drones and listening equipment purchased with money from organized crime groups, organizes an invasion of privacy, and persecutes the families of his victims, including young children. It also steals and illegally uses content, violates all possible laws and regulations regarding the dissemination of information. He was also accused of treason.
However, he did not give up drug trafficking, laundering criminal proceeds by purchasing real estate in the UAE and Russia (*country sponsor of terrorism). Alistarov also promotes outright scam for a percentage of criminal transactions and his own fraudulent business – selling real estate in Dubai with a horse, thieves’ commission, as well as cryptocurrency exchange using phishing schemes.
вывод из запоя в стационаре самары вывод из запоя в стационаре самары .
Useful info. Fortunate me I discovered your site accidentally, and I’m stunned why this twist of fate didn’t happened in advance! I bookmarked it.
https://xn--b1adgjdbhc1aebbqccldhhe2a7a.xn--p1ai/
????????? – ???? ???????
?? ????? ???? ??? ???? ??????? ???????
????? ??????? ?????? ????????? ?????? ????? ????????? ?????? ???? ?? ???? ???? ??? ???? ????? ?? ?? “????? ?????”. ??? ??? ?? ?????? ???? ????? ??????? ??????? ??????? – ??? ???? ??? ??????????? ????? ?????? ?????? ??????? ?????????? (AFU). ??? ????? ??? ????? “?????? ???????” (Zheleznaya Stavka) ??????????? ??????????? ????????? ??????? ???????? ???????/?????? ????? ?????? ???? ?????? ??? ????? ?????? ???????? ?? ???? ????? ?????? ?? ???.
?? ??? ???? ????? ?????? ?????? ????? ???? ????????? ?? ???? ?????? ?????? ??????? ??? ????? (?????? ?? ???? ?????? ?????) ????? ?? ???? ????? ????? ?????.
???????? ?????? ????????
?????????? ??? ?? ?????? ??????? ??? ???? ?????? ?? ???? ????? ??? ???????? ????????.
????? ????? ?? ??????? ???????. ???? ????? ?? ?????? ???? ???????? ?? ????? ???????? ?????? ??????? ??? ????? ?????? ?????? ???????? ?? ????? ?? ???? ??????? ?????? ?? ???? ?? ????? ?????????.
?????? ??? ??????? ??????????
???? ????????? “?????? ???????” ?????? ??????? “???” ????????? ??????? “???????” ???? ??????? ?????????? ???????? ??? ???????? “??????”: ????? ????? ?????????? ????????? ????? ?????????.
???? ?????? ?????? ?? “???????? ???????” ?? ???????????? ??? ????? ????? ??? ?????? ????????? ???? ?????: ????? ????? ????? “????????? ???????” ?? ???? ??? “??????” ????????? (?? ?? ?????? ??).
?????? ?? ???? ????????? ??????? ??????: ???? “?????” ??? ?????? ???????? ???? ?????. ???? ???? ??????? ?????? ????? ??????? ??????.
??????? ????????? ?? ???
?? 1 ????? 2025? ???? ??????? ????????????? ??????? ?????? ?? ??? ?????? ???? ?? ???? ??? ???? ????? ???? ???? ??????.
??? ???? ??? ????????? 12 ???? ????? ?????? ???????? ?? ????? ??? ?????? ?? ??? ??????? ??????? ?????? ??????? ???????? ?? ???????? ????? ??? ???????. ??? ?? ???? ?????? ????? ????? ??????? ??????? ??? ????? ???????? – ????? ????? ?????? ??????? ?????? ?? ????????? ?? ???? ??????? ????? ?????????? ???? ?????? ?????.
???? ??? ???????? ??? ????????? ?? ??? ????? ???????? ?? ????? ???? ??? ????? ?? ????? – ?? ??? ????? ??????? ?????? ??????? ?????? ????????? ??????? ???????? ???????? ????? ?????? ?? ????????. ??? ???? ???? ?????? ?? ???? ????? ??? ?????? ??????? ?? ???? ????? ??? ??????.
????? ????????? ??? ???? ????????? ???????? ?????????? ?? ??? ????? – ????? ?????? ?? ??????? ???????. ??? ??? ??? ?? ????? ??? ???????? ????? ??? ???? ???????? ?? ??? ?? ???? ??????? ?? ??????.
??????? ?? ??????
????? ??? ????? ??? ????? ??????? ?? ?????? ????? ?? ???? ?????? ??? ????? ????? ???????? ???? ??? ????. ??? ??????? ??????? ???????? ??? ?????? ??? ????.
?? ????????? ?????? ?????? ???? ?????? ???? ??????? ??? ??? ????? (???? ??????) ?? ???? ??? ????? ?????????? – ????? ????? ????? ??????? ?????? ?????? ????? ?? ????? ????????.
?????? ????????? ??? ????????? ????? ?????? ?????? ?????? ????? ????? – ?????? ??????? ??? ?? ??? ?? ????? ?????? ????? ?? ??? ????.
???????? ?? ????
?? ???? ????? ??????? ??? ????????? ????? ?????? ?? ??????? ????? ???????? ??????? ??? ?????? ??? – ???????? ??????? ?????? ??????? ?????? ??? ?????? ???????? ??????? ??????? ?????? ??? ???? ??????? ???????. ????? ????????? ?? ??? ????? “?????” ?? ????? ??? ??? ??? ???? ???? ??? ???? ??????.
??? ??????? ?????? ???? ????? ????? ?????? ?????? ??????? ????? ?? ??????? ????? – ?????????? ?? ?????? ???????? ??????. ????? ??? ???? ??? ???? ?? ??? ????? ??????? ???? ?? ????? ???????? ???????? ???? ???? ????? ?? ?????? ??????. ???? ???? ???? ?????? ??? ???? ?? ?????? ?? ???????.
???? ???? ?? ??? 2022 ??”?????” ??? ????? – ?????? ?? ???? ???????. ??? ?? ???? ???????? ??????? ?? ??????? ????? ??????? ???????? ?????? ?????? ???? ?????? ??? ?????? ??????. ??? ????????? ???????? ???????? ???? ??? ?????? ???????? ??????? ??? ?? ????? ?????? ?????? ????? ?????????.
????? ????????? ?? ?????????? ?????? ?? ????? ??????? ??? ??? ???? ????????? ???????? ????? ??? ????? ?? ??? ??? ?????? ??? ???????? ??? ?????? ???? ?????? ???? ????? ????? ??????? – ?? ??? ?? ???? ?????? ???????? ???????? ?????? ?????.
???? ?????? ???? ????? ??????? ??????? ??? ?????? ?? ????? ????? ???. ???? ?????? ??????????? ?? ??????? ?? ????? ??? ???? ????? ????? – ??? ???? ?????? ????? ??????? ???????? ??????? ???? ?????? ????? 2022 ???? ?????? ?? ????? ?????? ????? ??????? ??????. ??? ???? ????? ?????? “???? ????”.
?????? ????? ????????? ????? ???????? ???????? ??????? ?????? ????? ????? ????? ??????? ????? ????? ????? ?? ???? ????? ??????? ????? ??????? ????? ????? 20 ????? ????? ?? ?????? ??????? ??? ????? ??? ????? ?? ????? – ??????? ?? ???? ???? ?????? ??? ????? ?? ?????? (??? ????? ??? ????).
???????? ?? ??????
???? ????????? ?????? ????? ???? ???? ?? ????? ???????? ?????????? ??? ????? ????? ???? ??????? ??? ???????. ????? ??? ??? ????? ??? ????? ??? ??????? ??????? ?????? ??? ???? ?????? ?? ??? ????????? ??? ??????.
?????? ???????? ?? ?????
??? ????????? ????? ?? ??? ???? ?? ??????? ??? ???? ????? ???? ??????? ?? ??????.
???? ??? ???? ?? ?????? ?????????
?? ??? ??????? ???? ?????? ???? ????? ????????? ?????? ?????? ????? ?????? ?????? ??? ????????? ???? ?????? ??? ??? ?????? – ??? ???? ??????? ?? ???? ??????? ?? ???.
???????? ?? ?????????
????? ????????? ??? ???? ??????? ??????????? ??????? ??????? “??? ???? ?????” ?”????? ??????”.
???? ??? ???? ????? ???????
?? ???? ????????? ???????? ???? ?????? ???????? ?? 6 ???? ?????? ?????? ??? ??? ??? ????? ??????? ????????? ?? ?????? (????????? – ????? Coinsbit) ?? ????
?? ??? 2024? ????? ???? ?????? ??? ????? ??? ??????? – ?????? ?????? ??????? ??????????? ?? ????? ?? ????? ????? ????? ????? ???. ?? ?? ?? ????????? ??? ????? ????????? ????? ?????? ??????? ?????????? ????.
??????? ??????
??? ???? ????????? ??????? ???? ?????? ?????????? ???????? ???? ???? ?????? ??? ??? “???????” ???? ??? ????? ??????? ???? ?????? ????? ?? ???? “?????” ??.
?????? ????????? ?? ??? ?????? ?????????? – ???? “???? ?????? ????? ??????” ??????? ??????? ????? ???? ?? ???? ??”????? ????? ???? ?????????” ?????? ??????? (???? ?? ?????? ???????) – ?????? ???????. ??? ?? ?????? ?? ???? ????? FSB (????? ????????? ??????) ???????? ?????? ???????????
????? ?????
????? ??????? ?? ???? ????????? ??? ?????? ???????? ??? ?????? ??????? ????? ?????? ???? – ?? ????? ?? ??????? ????? ????? ??? ?? ???? ????? ?????? ????? ???????? ????? – ??? ??? ???? ?? ?????: ????? ???? ???? ?? ???? ????? ??? ????? ?? ??????? ?????? ????? ?????? ??????? ???? ???????? ?????:
????????
??????? ????????
??????? ??? ????? ????? ?? ?? ?? ???? ????
??????? ??????
????? ???????
????????
??????
?????? ??? ?????? ??????
???? ????? ????????? ?? ?????? ???? ?? ????? ???? ?????.
Hi all, here every person is sharing these kinds of knowledge, therefore it’s pleasant to read this web site, and I used to go to see this website every day.
https://xn—–7kcgiiy1bf2ancu8h.xn--p1ai
Witaj w Slottica PL! To miejsce, gdzie ekscytacja spotyka się z różnorodnością, a niezawodność staje się Twoim codziennym towarzyszem w świecie gier online. Dla polskich graczy w Slottica PL przygotowaliśmy ofertę, która spełni wszystkie oczekiwania – od doskonałej kompatybilności mobilnej, przez szeroką gamę gier, aż po usługi skoncentrowane na Twoim komforcie i bezpieczeństwie.
GAMELANTOGEL
토토사이트 커뮤니티: 안전한 베팅을 위한 길잡이
토토사이트 커뮤니티는 스포츠 베팅을 즐기는 사람들에게 단순한 정보 공유의 장을 넘어, 안전한 배팅 환경을 조성하는 데 중요한 역할을 합니다. 이곳에서는 초보자부터 전문가까지 다양한 사람들이 모여 베팅 전략을 논의하고, 신뢰할 수 있는 토토사이트를 추천하며, 먹튀 사고를 예방하기 위한 정보를 공유합니다. 특히, 사설 토토사이트의 위험성을 알리고, 이를 피할 수 있는 방법을 제시함으로써 사용자들이 더 안전하게 베팅을 즐길 수 있도록 돕습니다.
사설 토토사이트의 숨겨진 위험
사설 토토사이트는 정부의 규제를 받지 않기 때문에 다양한 문제를 일으킬 수 있습니다. 예를 들어, 공정하지 않은 배당률, 과장된 광고, 개인정보 유출 등이 대표적인 문제점입니다. 또한, 사설 토토사이트는 법적 문제로 인해 갑자기 사라지는 경우가 많아 사용자들이 금전적 손실을 입을 위험이 큽니다. 이런 이유로, 토토 커뮤니티에서는 사설 토토사이트보다는 규제를 받는 공식 사이트를 이용할 것을 권장합니다.
토토 커뮤니티가 제공하는 가치
토토 커뮤니티는 단순히 정보를 나누는 공간이 아니라, 사용자들이 안전하게 베팅할 수 있도록 돕는 네트워크입니다. 예를 들어, 새로운 토토사이트가 등장했을 때 커뮤니티 멤버들은 해당 사이트의 운영 주체, 결제 시스템, 사용자 리뷰 등을 꼼꼼히 검토합니다. 이를 통해 먹튀 사고를 미리 방지하고, 신뢰할 수 있는 사이트만을 추천합니다. 또한, 문제가 발생했을 때는 보증 사이트를 통해 사용자들이 손실을 최소화할 수 있도록 돕습니다.
어떻게 신뢰할 수 있는 토토사이트를 찾을까?
토토 커뮤니티에서는 신뢰할 수 있는 토토사이트를 찾기 위해 몇 가지 중요한 기준을 제시합니다. 먼저, 사이트의 운영 주체가 명확한지 확인하는 것이 중요합니다. 정부나 공인된 기관에서 관리하는 사이트라면 신뢰할 수 있습니다. 또한, 다른 사용자들의 리뷰를 참고하여 사이트의 신뢰성을 판단할 수 있습니다. 긍정적인 평가가 많고, 문제가 거의 없는 사이트라면 안전하게 이용할 수 있습니다.
결제 시스템도 중요한 확인 요소 중 하나입니다. 신용카드, 전자지갑 등 다양한 결제 방법을 지원하고, SSL 암호화를 통해 금융 정보를 보호하는 사이트라면 더욱 신뢰할 수 있습니다. 마지막으로, 온라인 커뮤니티나 포럼에서 해당 사이트에 대한 평판을 확인하는 것도 좋은 방법입니다. 다른 사용자들이 어떻게 평가하는지, 문제가 없는지 꼼꼼히 살펴보는 것이 중요합니다.
토토 커뮤니티의 보증 사이트
토토 커뮤니티에서는 먹튀 사고를 예방하기 위해 보증 사이트를 추천합니다. 이러한 사이트는 사용자들의 개인정보와 금융 정보를 보호하며, 문제가 발생했을 때 빠르게 해결할 수 있는 시스템을 갖추고 있습니다. 보증 사이트를 이용하면 안전하게 베팅을 즐길 수 있으며, 만약 문제가 생기더라도 커뮤니티의 도움을 받아 해결할 수 있습니다.
마무리
토토사이트 커뮤니티는 스포츠 베팅을 즐기는 사람들에게 안전하고 신뢰할 수 있는 정보를 제공하는 중요한 공간입니다. 사설 토토사이트의 위험성을 인지하고, 신뢰할 수 있는 사이트를 선택하는 것이 무엇보다 중요합니다. 토토 커뮤니티의 정보를 참고하여 안전한 베팅 환경을 조성하고, 스포츠 베팅을 더욱 즐겁게 즐기시길 바랍니다. 항상 책임감 있게 베팅에 임하는 것도 잊지 마세요!
купить диплом в рязани
пропуск в москву для грузовых автомобилей пропуск в москву для грузовых автомобилей .
Форум предназначен для обсуждения вопросов, связанных с видеонаблюдением и безопасностью. Участники могут делиться информацией и опытом в области программного обеспечения для видеонаблюдения на ПК, совместимого с IP-камерами. Рассматриваются комплексные решения, VMS, CMS, а также технологии AHD и IP. Обсуждаются вопросы настройки, восстановления паролей камер, и применения ИИ-видеоаналитики. Отдельное внимание уделено применению интегрированной видеоаналитики на основе искусственного интеллекта, включая обнаружение объектов, распознавание автомобильных номеров и лиц, а также выявление признаков дыма и огня. Форум является площадкой для обмена знаниями и обсуждения актуальных тем в области видеонаблюдения. Здесь пользователи могут делиться своим опытом, задавать вопросы и находить решения для своих задач. Форум служит платформой для обмена знаниями и поиска решений в сфере видеонаблюдения. выбор камеры видеонаблюдения форум
Играй за Реальные Деньги с Удобством! Онлайн покер – это ни просто игра, данное вся вселенная азарта, тактики и шанса заработать реальные деньги, без выходя с дома. Когда вы ищете где поиграть в покер в интернете, на русском языке а с выводом денег непосредственно на карту, то ты оказались по месту. Данная статья – твой проводник в мир онлайн покера в россии.
Почему Онлайн Покер так Популярен? Покер – это классическая карточная игра, что целые столетия завлекала миллионы людей. Онлайн формат дал ей новую жизнь, сделав игры доступными для каждого желающих. Вот лишь пара оснований известности онлайн покера:
Удобство и открытость: Играть возможно в всякое время и в любом месте, имея только подключение к браузере либо мобильному устройству. Широкий выбор: Покеррумы предлагают разнообразные виды покера, форматы турниров и уровни ставок. Играть с реальными людьми: Вы способен бороться с реальными соперниками со всего мира, а не с компьютерными ботами. Возможность выигрывать реальные деньги: Играть на деньги – это не только азарт, а также шанс наполнить свой бумажник. Социальный аспект: Возможно играть с друзьями либо заводить свежие знакомства с людьми, разделяющими твой интерес. Где Играть в Онлайн Покер в россии на Реальные Деньги? В россии есть большое количество сайты и покеррумы, предлагающих игры в онлайн покер. Однако каким образом выбрать оптимальный из них? Мы поможем вам разобраться:
Популярные Покеррумы для Русских Игроков:
Мы организовали рейтинг лучших покеррумов для русском языке игроков, учитывая такие критерии:
Наличие русского языка: Интерфейс и обслуживание должны быть на русском языке. Возможность играть на рубли: Депозиты и вывод средств должны быть открыты в рублях. Многообразие игр и турниров: Обширный выбор столов и турниров для всевозможных уровней игроков. Наличие мобильного приложения: Возможность скачать приложение для андроид и играть с мобильного устройства. Наличие выгодных бонусов: Бездепозитным бонусом за регистрацию, начальным капиталом, бонусы на депозит а другие акции. Безопасность а авторитет: Безопасность транзакций и честность игры. Топ румов постоянно обновляется, из-за этого советуем наблюдать за свежими обзорами а отзывами игроков.
Особое Внимание на Минимальный Депозит:
Когда ты новичок, тогда стоит обратить внимание на покеррумы с минимальным депозитом. Данное позволит тебе начать играть на реальные деньги без больших финансовых вложений.
Разрешенные Покеррумы:
Проверьте, что подобранный тобой рум есть разрешенным в россии, чтобы избежать возможных проблем с доступом а выводом средств.
Онлайн Покер с Выводом Денег на Карту: Как Это Работает? После того, как вы определились с покеррумом и выбрали игру, вы способен пополнить свой счет и начать играть на деньги. Большая часть сайтов предлагают различные способы пополнения а вывода средств, включая:
Банковские карты (Visa, Mastercard) Электронные кошельки Другие платежные системы Вывод денег на карту как правило требует от нескольких часов до нескольких дней, в зависимости от рума а выбранного способа вывода.
Как Играть в Онлайн Покер с Друзьями? Многие покеррумы дают возможность играть с друзьями за приватными столами. Данное замечательный метод уделить время с людьми, с которыми вы знакомы, а побороться за звание лучшего игрока в вашей компании.
Бесплатный Покер: Возможность Попробовать Свои Силы Когда вы новичок и желаешь вначале привыкнуть с правилами, многие сайты предлагают шанс играть в бесплатный покер. Данное прекрасный метод поупражняться а получить опыта перед тем, как начать играть на реальные деньги.
Покер на пк: Комфорт и Удобство Если вы предпочитаете играть на пк, тогда большая часть покеррумов предлагают клиенты для компьютеров, которые гарантируют намного комфортный а надежный игровой процесс.
Заключение: Начните Свой Путь в Мир Онлайн Покера Сегодня! Онлайн покер – есть захватывающая игра, что может предоставить тебе не просто удовольствие, но также реальные деньги. Подбирайте надежные сайты и румы, принимайте участие в турнирах, играйте с друзьями и людьми со всего мира, и знайте, что главное – есть получать наслаждение от игры!
Не откладывайте на потом, приступайте твою игру в онлайн покер прямо сейчас! Окунитесь в мир тактики, волнения и шансов! Везенья за столами!
Berikut artikel yang Anda minta berdasarkan konteks sebelumnya:
Misteri Tulisan Yesus di Pasir: Rahasia Tersembunyi dalam Kitab Suci
Dalam tradisi Kristen, salah satu momen paling misterius adalah ketika Yesus menulis di pasir saat menghadapi seorang perempuan yang tertangkap berzina. Apa sebenarnya yang ditulisnya?
Jejak Ilahi dalam Tulisan
Merujuk pada Kitab Keluaran, Allah sendiri pernah menulis dengan jari-Nya di atas batu. Yesus, sebagai inkarnasi Ilahi, tampaknya mengulang tindakan sakral ini.
Hipotesis Tulisan Rahasia
Beberapa sarjana menafsirkan bahwa Yesus mungkin menulis:
– Nama-nama para penuduh
– Daftar dosa mereka
– Ayat-ayat hukum yang mereka langgar
Makna Tersembunyi
Tindakan menulis di pasir bukan sekadar gerakan acak, tetapi memiliki signifikansi teologis mendalam. Yesus secara simbolis mengungkapkan kebenaran tersembunyi tentang kemanusiaan.
Kesimpulan
Meskipun isi tulisan tetap menjadi misteri, tindakan Yesus menunjukkan kebijaksanaan yang melampaui pemahaman manusia.
토토사이트
토토사이트 커뮤니티: 안전한 베팅을 위한 길잡이
토토사이트 커뮤니티는 스포츠 베팅을 즐기는 사람들에게 단순한 정보 공유의 장을 넘어, 안전한 배팅 환경을 조성하는 데 중요한 역할을 합니다. 이곳에서는 초보자부터 전문가까지 다양한 사람들이 모여 베팅 전략을 논의하고, 신뢰할 수 있는 토토사이트를 추천하며, 먹튀 사고를 예방하기 위한 정보를 공유합니다. 특히, 사설 토토사이트의 위험성을 알리고, 이를 피할 수 있는 방법을 제시함으로써 사용자들이 더 안전하게 베팅을 즐길 수 있도록 돕습니다.
사설 토토사이트의 숨겨진 위험
사설 토토사이트는 정부의 규제를 받지 않기 때문에 다양한 문제를 일으킬 수 있습니다. 예를 들어, 공정하지 않은 배당률, 과장된 광고, 개인정보 유출 등이 대표적인 문제점입니다. 또한, 사설 토토사이트는 법적 문제로 인해 갑자기 사라지는 경우가 많아 사용자들이 금전적 손실을 입을 위험이 큽니다. 이런 이유로, 토토 커뮤니티에서는 사설 토토사이트보다는 규제를 받는 공식 사이트를 이용할 것을 권장합니다.
토토 커뮤니티가 제공하는 가치
토토 커뮤니티는 단순히 정보를 나누는 공간이 아니라, 사용자들이 안전하게 베팅할 수 있도록 돕는 네트워크입니다. 예를 들어, 새로운 토토사이트가 등장했을 때 커뮤니티 멤버들은 해당 사이트의 운영 주체, 결제 시스템, 사용자 리뷰 등을 꼼꼼히 검토합니다. 이를 통해 먹튀 사고를 미리 방지하고, 신뢰할 수 있는 사이트만을 추천합니다. 또한, 문제가 발생했을 때는 보증 사이트를 통해 사용자들이 손실을 최소화할 수 있도록 돕습니다.
어떻게 신뢰할 수 있는 토토사이트를 찾을까?
토토 커뮤니티에서는 신뢰할 수 있는 토토사이트를 찾기 위해 몇 가지 중요한 기준을 제시합니다. 먼저, 사이트의 운영 주체가 명확한지 확인하는 것이 중요합니다. 정부나 공인된 기관에서 관리하는 사이트라면 신뢰할 수 있습니다. 또한, 다른 사용자들의 리뷰를 참고하여 사이트의 신뢰성을 판단할 수 있습니다. 긍정적인 평가가 많고, 문제가 거의 없는 사이트라면 안전하게 이용할 수 있습니다.
결제 시스템도 중요한 확인 요소 중 하나입니다. 신용카드, 전자지갑 등 다양한 결제 방법을 지원하고, SSL 암호화를 통해 금융 정보를 보호하는 사이트라면 더욱 신뢰할 수 있습니다. 마지막으로, 온라인 커뮤니티나 포럼에서 해당 사이트에 대한 평판을 확인하는 것도 좋은 방법입니다. 다른 사용자들이 어떻게 평가하는지, 문제가 없는지 꼼꼼히 살펴보는 것이 중요합니다.
토토 커뮤니티의 보증 사이트
토토 커뮤니티에서는 먹튀 사고를 예방하기 위해 보증 사이트를 추천합니다. 이러한 사이트는 사용자들의 개인정보와 금융 정보를 보호하며, 문제가 발생했을 때 빠르게 해결할 수 있는 시스템을 갖추고 있습니다. 보증 사이트를 이용하면 안전하게 베팅을 즐길 수 있으며, 만약 문제가 생기더라도 커뮤니티의 도움을 받아 해결할 수 있습니다.
마무리
토토사이트 커뮤니티는 스포츠 베팅을 즐기는 사람들에게 안전하고 신뢰할 수 있는 정보를 제공하는 중요한 공간입니다. 사설 토토사이트의 위험성을 인지하고, 신뢰할 수 있는 사이트를 선택하는 것이 무엇보다 중요합니다. 토토 커뮤니티의 정보를 참고하여 안전한 베팅 환경을 조성하고, 스포츠 베팅을 더욱 즐겁게 즐기시길 바랍니다. 항상 책임감 있게 베팅에 임하는 것도 잊지 마세요!
покер онлайн на реальные деньги с выводом
24-часовая доставка алкоголя внутри Москве: удобство или задача?
Столица – город, который никогда не отдыхает, а ради большинства ее населения шанс приобрести требуемое в любое час суток стала привычной. Это относится также к поставке спиртных напитков, что, невзирая на свою противоречивость, прочно проникла в повседневную бытие столичных жителей. Однако ли ли всё просто, словно кажется на первого взгляд?
Каким образом это работает?
24-часовая поставка спиртного в Москве осуществляется через многообразные сервисы:
Онлайн-платформы: Профильные сайты и программы, которые предлагают обширный выбор алкогольных продуктов с доставкой в дом. Заведения общепита и пабы: Отдельные заведения, имеющие разрешение для реализацию спиртного, предлагают поставку их товаров в вечернее время суток. Доставщики службы: Компании, которые сотрудничают с лицензированными продавцами алкоголя и проводят поставку по запросу. Преимущества:
Комфорт: Возможность заказать излюбленный продукт, не покидая из дома, в всякое время дня. доставка алкоголя в москве Экономия времени: Не нужно тратить время на поход в магазин, особенно в позднее время. Большой выбор: Обширный ассортимент спиртных напитков, включая редкие и особенные позиции. Возможность для праздников и мероприятий: Оперативная поставка дает возможность быстро добавить резервы алкоголя, если это потребуется. Недостатки и противоречия:
Правомерность: В России не разрешена реализация спиртного в вечернее время (с 23:00 до 8:00). Службы доставки, которые предоставляют 24-часовую доставку, обычно применяют всевозможные схемы, что способны быть противозаконными. Употребление спиртного: Простой доступ к спиртному в любое время может способствовать росту потребления, что может повлечь отрицательные последствия на самочувствия. Проверка над реализацией несовершеннолетним: Имеется опасность, что доставщики способны не контролировать возраст клиентов, что способен привести к реализации спиртного не достигшим совершеннолетия.
покер онлайн
Deepika Padukone and Christy Turlington star in landmark Sabyasachi fashion show
гей порно член
Camera phones at the ready, around 700 guests hailing from across India and the world expected a visual spectacle on Saturday evening — and they weren’t disappointed. A hush descended as the doors opened to the Jio World Center in Mumbai, where legendary Indian fashion designer Sabyasachi Mukherjee presented a star-studded 25th anniversary runway show for his namesake brand.
The celebrated designer — known for his maximalist Indian style — has dressed some of the biggest names across Bollywood and Hollywood, including Priyanka Chopra, Deepika Padukone, Oprah Winfrey, Rihanna and Jennifer Lopez. For his landmark show, the stars showed up to lend their support: Padukone opened proceedings in an all-white ensemble adorned with necklaces, including a crucifix from Mukherjee’s jewelry line. She later walked again with supermodel Christy Turlington as part of the grand finale.
Over 150 looks were presented, including pants and skirts embroidered with gold threads, frilled head gear, stacked jewelry and tops with slogans such as “cat lady,” “table for one,” “where has love gone,” and “all dressed up nowhere to go.” Mukherjee explained in a phone interview that these pieces were intended to be satire on how technology is dehumanizing humans. “We seem to have forgotten how to establish human relationships,” he said.
There were also trench coats, sweaters, shorts and shirts made in more conventionally western silhouettes. These marked a departure from Mukherjee’s usual festive and bridal wear, which are heavily inclined towards traditional Indian styles, such as saris, ghagra cholis and sherwanis.
But with no shortage of drama, the new collection featured heavily embroidered jackets embellished with semi-precious stones, brocade dresses, ostrich leather jackets and skirts, and blouses with velvet appliques overlaid with faux fur.
Рейтинг казино честных
see this https://web-freewallet.com
https://allswingersclubs.org/swingers-club/splash-takeovers/
In the immense expanse of the digital realm, Search Engine Optimization emerges as the linchpin that anchors companies to visibility and relevance. It is both art and science of positioning websites strongly within search engine results, acting as a bridge that connects companies with their intended audience. Through a mix of keyword research, superior content creation, and technical site optimization, SEO strategies ensure that a website’s message resonates with both search engine algorithms and human users. By constantly adapting to the shifting parameters set by search engines like Bing, effective SEO translates to increased organic traffic, heightened brand awareness, and, in the end, sustained business growth.
Additionally, the beauty of SEO lies in its organic nature, concentrating on providing authentic value to users rather than resorting to expensive shortcuts. When executed effectively, it builds a base of trust and authority for websites, making them the go-to sources within their specific niches. Beyond simple rankings, it’s about crafting user experiences that are uninterrupted and informative, fostering long-term relationships with visitors. In an age where information is at all fingertips, SEO ensures that the right message reaches the right audience at the perfect moment, solidifying a brand’s position in the web landscape.
https://seomarketify.blogprodesign.com/49277605/Примеры-успешных-кейсов-студии-xrumer-art
Умный способ управления жалюзи, повысит комфорт в помещении.
Оптимизируйте освещение и температуру в помещении с автоматикой для жалюзи.
Удобное управление жалюзи через интернет.
Повысьте уровень безопасности с автоматическими жалюзи.
Профессиональная установка автоматики для жалюзи.
автоматика на жалюзи автоматика на жалюзи .
elon bet casino elon bet casino .
Круглосуточная поставка спиртного внутри Москве: удобство либо задача?
Столица – город, что никогда никак спит, а ради многих его населения шанс приобрести желаемое в всякое час дня стала обычной. Данное принадлежит и к доставке алкоголя, которая, невзирая на ее спорность, надежно вошла в повседневную жизнь столичных жителей. Однако ли так все элементарно, словно видится с первого раза?
Как это работает?
Круглосуточная доставка алкоголя в Москве производится через различные сервисы:
Интернет-сервисы: Специализированные веб-сайты и приложения, которые дают широкий ассортимент алкогольных напитков с поставкой на дом. Рестораны и бары: Отдельные заведения, имеющие разрешение для реализацию спиртного, предлагают поставку своей продукции в ночное время суток. Доставщики сервисы: Фирмы, которые взаимодействуют с лицензированными продавцами спиртного и осуществляют поставку по запросу. Преимущества:
Комфорт: Возможность приобрести любимый продукт, не покидая из жилища, в любое время суток. алкоголь на дом москва Сбережение времени: Не нужно тратить время на визит в маркет, особо в вечернее время. Большой ассортимент: Обширный ассортимент спиртных продуктов, включая необычные и эксклюзивные позиции. Шанс для вечеринок и мероприятий: Оперативная доставка дает возможность быстро добавить резервы алкоголя, если это потребуется. Недостатки и споры:
Законность: В РФ не разрешена продажа спиртного в вечернее время (с 23:00 до 8:00). Службы доставки, которые предоставляют 24-часовую поставку, обычно применяют всевозможные схемы, что могут оказаться незаконными. Употребление спиртного: Легкий доступ к спиртному в всякое время способен помогать росту потребления, что может повлечь негативные последствия на здоровья. Контроль за реализацией несовершеннолетним: Существует риск, что курьеры способны не контролировать лета клиентов, что может вызвать к реализации спиртного не достигшим совершеннолетия.
Круглосуточная доставка спиртного внутри Москве: удобство или проблема?
Столица – город, что никогда никак спит, а для многих ее жителей возможность получить требуемое в любое час дня стала привычной. Данное относится также к доставке алкоголя, что, невзирая на свою противоречивость, прочно проникла в повседневную жизнь столичных жителей. Однако так ли всё элементарно, словно кажется на первый взгляд?
Как это работает?
Круглосуточная поставка спиртного в Москве производится посредством различные службы:
Онлайн-платформы: Профильные веб-сайты и приложения, которые предлагают обширный ассортимент спиртных продуктов с поставкой на квартиру. Рестораны и бары: Отдельные заведения, обладающие лицензию для продажу алкоголя, предлагают поставку своей товаров в ночное время суток. Доставщики сервисы: Компании, которые сотрудничают с лицензированными продавцами алкоголя и осуществляют поставку по запросу. Преимущества:
Удобство: Шанс заказать излюбленный продукт, не выходя из дома, в всякое время дня. доставка алкоголя в москве Экономия часа: Не требуется тратить время на визит в маркет, особо в позднее время. Широкий выбор: Большой ассортимент алкогольных напитков, в том числе необычные и особенные позиции. Шанс для праздников и мероприятий: Оперативная доставка позволяет быстро добавить запасы алкоголя, если это потребуется. Недостатки и споры:
Правомерность: В РФ запрещена продажа алкоголя в вечернее время (от 23:00 до 8:00). Сервисы поставки, что предлагают 24-часовую доставку, обычно используют всевозможные способы, что способны быть незаконными. Потребление алкоголя: Простой получение к алкоголю в любое время способен помогать увеличению употребления, что способен повлечь отрицательные результаты для здоровья. Контроль над реализацией несовершеннолетним: Имеется опасность, что курьеры способны не проверять лета покупателей, что может вызвать к продаже спиртного несовершеннолетним.
купить читы кс го приватные – Apex Legends вх, актуальные читы на GTA 5 Online
והכרה ישראל עשתה צעדים משמעותיים בהכרה ובהגנה וזכויותיהם של דירות דיסקרטיות בחיפה ולהט”ב. תל אביב, בפרט, התפתחה כמרכז תוסס של האולטימטיבי של דירות דיסקרטיות באשדוד ואתה במאה אחוז תמצא כאן את הבחירה הכי רלוונטית עבורך. דירות דיסקרטיות באשדוד, כאן חלומות review
24-часовая поставка спиртного в Москве: комфорт либо проблема?
Столица – мегаполис, что никогда не спит, и ради большинства ее населения шанс приобрести желаемое в всякое час дня стала обычной. Данное принадлежит и к поставке спиртных напитков, что, невзирая на свою спорность, надежно проникла в повседневную жизнь горожан. Но так ли всё элементарно, словно кажется с первый раза?
Каким образом это функционирует?
Круглосуточная доставка алкоголя в Москве осуществляется через многообразные сервисы:
Онлайн-платформы: Профильные веб-сайты и программы, которые дают обширный ассортимент спиртных напитков с доставкой на квартиру. Рестораны и бары: Отдельные заведения, обладающие лицензию на продажу алкоголя, предоставляют доставку их товаров в вечернее время. Доставщики службы: Компании, что взаимодействуют с имеющими лицензию реализаторами алкоголя и осуществляют поставку по требованию. Преимущества:
Удобство: Шанс заказать любимый продукт, не покидая из жилища, в любое время дня. доставка алкоголя в москве круглосуточно Экономия часа: Не требуется терять часы на визит в магазин, особо в вечернее время. Широкий ассортимент: Обширный ассортимент алкогольных напитков, в том числе редкие и эксклюзивные предложения. Шанс для праздников и мероприятий: Быстрая доставка позволяет оперативно пополнить резервы алкоголя, когда это потребуется. Недостатки и споры:
Законность: В РФ не разрешена продажа спиртного в вечернее время (от 23:00 до 8:00). Службы поставки, которые предоставляют круглосуточную доставку, часто используют всевозможные схемы, что способны быть незаконными. Употребление спиртного: Легкий получение к алкоголю в любое время способен способствовать росту потребления, что может иметь отрицательные результаты на здоровья. Контроль за реализацией несовершеннолетним: Имеется риск, что курьеры способны не контролировать лета покупателей, что способен вызвать к продаже алкоголя не достигшим совершеннолетия.
A brief history of sunglasses, from Ancient Rome to Hollywood
Площадка кракен
Sunglasses, or dark glasses, have always guarded against strong sunlight, but is there more to “shades” than we think?
The pupils of our eyes are delicate and react immediately to strong lights. Protecting them against light — even the brilliance reflected off snow — is important for everyone. Himalayan mountaineers wear goggles for this exact purpose.
Protection is partly the function of sunglasses. But dark or colored lens glasses have become fashion accessories and personal signature items. Think of the vast and famous collector of sunglasses Elton John, with his pink lensed heart-shaped extravaganzas and many others.
When did this interest in protecting the eyes begin, and at what point did dark glasses become a social statement as well as physical protection?
The Roman Emperor Nero is reported as holding polished gemstones to his eyes for sun protection as he watched fighting gladiators.
We know Canadian far north Copper Inuit and Alaskan Yupik wore snow goggles of many kinds made of antlers or whalebone and with tiny horizontal slits. Wearers looked through these and they were protected against the snow’s brilliant light when hunting. At the same time the very narrow eye holes helped them to focus on their prey.
In 12th-century China, judges wore sunglasses with smoked quartz lenses to hide their facial expressions — perhaps to retain their dignity or not convey emotions.
чит на вх кс 1.6 – cheat gta 5 online, приватный чит кс го
A brief history of sunglasses, from Ancient Rome to Hollywood
kraken войти
Sunglasses, or dark glasses, have always guarded against strong sunlight, but is there more to “shades” than we think?
The pupils of our eyes are delicate and react immediately to strong lights. Protecting them against light — even the brilliance reflected off snow — is important for everyone. Himalayan mountaineers wear goggles for this exact purpose.
Protection is partly the function of sunglasses. But dark or colored lens glasses have become fashion accessories and personal signature items. Think of the vast and famous collector of sunglasses Elton John, with his pink lensed heart-shaped extravaganzas and many others.
When did this interest in protecting the eyes begin, and at what point did dark glasses become a social statement as well as physical protection?
The Roman Emperor Nero is reported as holding polished gemstones to his eyes for sun protection as he watched fighting gladiators.
We know Canadian far north Copper Inuit and Alaskan Yupik wore snow goggles of many kinds made of antlers or whalebone and with tiny horizontal slits. Wearers looked through these and they were protected against the snow’s brilliant light when hunting. At the same time the very narrow eye holes helped them to focus on their prey.
In 12th-century China, judges wore sunglasses with smoked quartz lenses to hide their facial expressions — perhaps to retain their dignity or not convey emotions.
1 мостбет gtrtt.com.kg .
24-часовая поставка спиртного в Москве: удобство или задача?
Каким образом это функционирует?
Круглосуточная поставка спиртного в Москве производится посредством различные службы:
Онлайн-платформы: Специализированные веб-сайты и программы, что предлагают широкий выбор алкогольных напитков с доставкой на дом. Рестораны и пабы: Некоторые заведения, обладающие разрешение для продажу спиртного, предоставляют поставку их товаров в ночное время. Доставщики службы: Фирмы, которые взаимодействуют с имеющими лицензию продавцами алкоголя и проводят поставку по требованию. Плюсы:
Комфорт: Возможность заказать любимый напиток, не покидая из дома, в всякое время суток. алкоголь на дом москва – Сбережение часа: Не требуется терять время на поход в магазин, особенно в позднее время. Большой ассортимент: Обширный ассортимент спиртных напитков, в том числе редкие и эксклюзивные предложения. Шанс для праздников и мероприятий: Быстрая доставка дает возможность оперативно пополнить резервы алкоголя, если это потребуется. Недостатки и споры:
Законность: В России не разрешена продажа алкоголя в ночное время (с 23:00 до 8:00). Службы доставки, что предлагают 24-часовую доставку, обычно применяют различные способы, что могут оказаться незаконными. Потребление спиртного: Легкий доступ к алкоголю в любое время способен способствовать росту потребления, что способен иметь отрицательные последствия для здоровья. Проверка за продажей не достигшим совершеннолетия: Имеется опасность, что курьеры могут не контролировать лета покупателей, что может привести к реализации спиртного не достигшим совершеннолетия.
Круглосуточная поставка алкоголя в Москве: комфорт либо проблема?
Каким образом это функционирует?
Круглосуточная доставка спиртного в Москве осуществляется через многообразные сервисы:
Интернет-сервисы: Профильные сайты и приложения, которые дают обширный выбор спиртных напитков с поставкой на дом. Заведения общепита и бары: Отдельные заведения, имеющие лицензию на реализацию алкоголя, предоставляют поставку своей продукции в ночное время. Доставщики службы: Фирмы, которые сотрудничают с лицензированными реализаторами спиртного и осуществляют доставку по требованию. Преимущества:
Комфорт: Шанс заказать любимый продукт, не покидая из дома, в любое время суток. доставка алкоголя в москве – Сбережение времени: Не нужно терять часы на визит в маркет, особенно в вечернее время. Широкий выбор: Обширный выбор спиртных продуктов, в том числе редкие и эксклюзивные позиции. Возможность для вечеринок и событий: Оперативная поставка дает возможность оперативно добавить резервы спиртного, если это необходимо. Недостатки и противоречия:
Законность: В РФ не разрешена реализация алкоголя в вечернее время (от 23:00 до 8:00). Сервисы поставки, которые предлагают 24-часовую поставку, обычно используют всевозможные способы, которые могут оказаться противозаконными. Потребление спиртного: Простой получение к алкоголю в всякое время способен помогать росту потребления, что способен повлечь отрицательные последствия на здоровья. Контроль за продажей не достигшим совершеннолетия: Имеется риск, что курьеры могут не контролировать возраст клиентов, что способен вызвать к продаже алкоголя не достигшим совершеннолетия.
1Win casino Lucky Jet Chile
her latest blog https://web-smartwallet.org/
important source https://web-martianwallet.io/
Появление сайта вверх лидирующие места Яндекса: Квалифицированное SEO оптимизация от экспертов
Стремитесь, чтобы Ваш сайт располагался верхнюю место в выдаче поиска Yandex? В таком разе вам необходимо экспертное раскрутка сайта в сети. Наша компания даём полные сервисы SEO и оптимизации ресурсов, спроектированные конкретно чтобы получения оптимальной результативности.
Наши специалисты задействуют только легальные SEO методы чтобы гарантированного вывода вашего веб-сайта в верхние позиции поисковых машин. seo продвижение Мы изучаем ваш веб-сайт, подстраиваем его под стандарты Яндекса, разрабатываем результативную стратегию продвижения и запускаем грамотную рекламу для привлечения потенциальной публики.
Избавьтесь об утраченных покупателях! Обратитесь SEO продвижение веб-сайта в нашей компании, и Ваш компания приобретёт значительный подъём прогресса. Мы содействуем вам опередить конкурентов и занять ведущие позиции в сети.
Что мы предлагаем:
Всесторонний SEO аудит ресурса.
Оптимизацию сайта под Яндекса.
Действенную продвижение сайта.
Разработку плана раскрутки в интернете.
Коррекцию и сопровождение контекстной рекламы.
Поднятие ресурса в верх и на лидирующую позицию искательной выдачи.
Увеличьте доход вашего бизнеса – закажите качественное продвижение сайта прямо в данный момент! Наша цель – поместить ваш сайт в топ! Получите качественные услуги по SEO и сделайте ресурс в эффективный средство сбыта. Мы понимаем, как поместить Ваш ресурс на лидирующую страницу в Yandex!
Временная регистрация в Москве – быстро и надежно!
Нужна временная прописка для работы, учебы или оформления документов?
Оформим официальную регистрацию в Москве всего за 1 день. Без очередей,
с гарантией и юридической чистотой!
1. Подходит для граждан РФ и СНГ
2. Регистрация от 3 месяцев до 5 лет
3. Легально, с внесением в базу МВД
Работаем без предоплаты! Документы можно получить лично или дистанционно.
Доступные цены, оперативное оформление!
Звоните или пишите в WhatsApp прямо сейчас – поможем быстро и без лишних вопросов!
Временная регистрация в Москве
1win
elon casino bangladesh elon casino bangladesh .
ван вин ван вин .
read this https://web-kaspawallet.com/
USDT
USDT:加密世界的穩定之錨
在加密貨幣的驚濤駭浪中,USDT宛如一座穩固的燈塔,為投資者指引方向。作為最廣泛使用的穩定幣,USDT以其與美元1:1錨定的特性,在動盪的數位資產市場中扮演著關鍵角色。
USDT的出現,解決了加密貨幣價格波動過大的痛點。它不僅為投資者提供了避風港,更成為連接傳統金融與加密世界的重要橋樑。在交易所之間轉移資金、進行跨境支付、對沖市場風險,USDT的身影隨處可見。
然而,USDT也面臨著監管壓力與信任危機。其發行公司Tether的儲備金透明度一直備受質疑,監管機構對穩定幣的審查也日益嚴格。這為USDT的未來發展蒙上了一層陰影。
儘管如此,USDT在加密經濟中的地位依然舉足輕重。它不僅是一種工具,更是一種象徵,代表著數位資產市場對穩定與信任的追求。隨著區塊鏈技術的發展與監管框架的完善,USDT或將迎來新的機遇與挑戰。
在這個新興的金融生態系統中,USDT的故事仍在繼續。它提醒我們,在追求創新的同時,穩健與透明同樣不可或缺。唯有如此,才能真正贏得市場的信任,推動加密經濟走向成熟。
сниму квартиру в сочи на длительный срок
https://www.dr-ay.com/blogs/213066/Shisha-tobacco-from-4-eur
карниз с электроприводом для штор купить карниз с электроприводом для штор купить .
x teacher video x teacher video .
шторы на электроприводе шторы на электроприводе .
сниму квартиру в сочи на длительный срок
секс веб чат
онлайн порно чат пары
снять квартиру в сочи авито
https://aldk24.ru/
снять квартиру в сочи на длительный
Откройте двери в изысканности и тайны, где возможно всё. Наш Telegram-канал “Проститутки Москва” приветствует вас вас ждет изысканный ассортимент самых обворожительных и пленительных девушек Москвы. Поверьте, что любое свидание — это способ погрузиться в мир чувственности и открыть для себя новые грани удовольствия.
Москва — это не просто столица, но и столица, где индивидуалки и эскортницы предлагают свои услуги самым требовательным клиентам. Мы предлагаем только самых надежных в сфере сопровождения, способных воплотить ваши мечты. У нас легко найти Индивидуалки, которая идеально подойдет вам.
Эскортницы, с которыми мы сотрудничаем, обладают не только безупречной внешностью, но и талантом делать каждый момент особенным. Они знают, как доставить вам удовольствие, и готова предложить неповторимый опыт. Обращаясь к нам, вы получаете высокое качество сервиса, конфиденциальность и гарантию. что вы получите массу приятных эмоций.
Шлюхи, которых мы предлагаем, тщательно отобраны, чтобы ваше время было потрачено не зря. Вы можете быть уверены в их компетентности и честности. Любая из них — это не только шикарная упаковка, но и искусство соблазнения. Благодаря удобному интерфейсу нашего канала вы можете изучить анкеты, найти ту, которая вам подойдет и быстро договориться о встрече.
Telegram-канал “Проститутки Москва” ваш ключ к миру страсти. Мы понимаем, что каждый клиент уникален, поэтому у нас широкий ассортимент, чтобы все остались довольны. У нас вы найдете Эскортницы на любой вкус и цвет, которые наполнят вашу жизнь новыми красками.
Вырвитесь из обыденности и почувствуйте себя в мире роскоши и комфорта. Вызовите Проститутки из нашего канала, и ваша жизнь станет незабываемой. Почувствуйте себя королем, наслаждаясь обществом прекрасных девушек, которые готовы исполнить ваши желания.
Все подробности здесь тг: https://t.me/indimoscow11 и определитесь со своим выбором. Сделайте первый шаг к незабываемому вечеру, который вы будете вспоминать с восторгом. Шлюхи готовы встретиться с вами, чтобы этот вечер стал особенным.
Почувствуйте себя особенным, наслаждаясь каждым мгновением. Москва полна загадок и соблазнов, и мы поможем вам найти то, что вы ищете. Пора наслаждаться жизнью — остановите свой выбор на нас, знакомьтесь с теми, кто воплотит ваши мечты.
Мы поможем вам исполнить ваши мечты, и вы забудете о буднях. Вместе с “Проститутки Москва” ваши мечты станут реальностью в самом центре Москвы.
https://rt.mdksex.com/
Lucky Jet – твой шанс на большие выигрыши!
Попробуй захватывающую краш-игру прямо сейчас! Регистрируйся и получи бонус до 500% на первый депозит с промокодом: LuckyJetTeam.
сигналы лаки джет
Об игре
Lucky Jet — это не просто игра, а захватывающее приключение, в котором каждый момент может стать решающим! Эта краш-игра бросает вызов вашим инстинктам и способности быстро принимать решения. В основе игры — динамичная механика, где игроки ставят на рост коэффициента, но задача не в том, чтобы ждать до последнего, а вовремя вывести свой выигрыш, прежде чем персонаж взлетит слишком высоко и случится крах.
Чем выше коэффициент, тем более значительная награда! Но не забывайте: в этом азартном путешествии важен каждый момент, ведь именно ваше решение о выводе решит, насколько велик будет ваш выигрыш. Это не просто игра, а настоящее испытание на скорость и удачу! Простые правила, быстрые раунды и реальные выигрыши – вот почему игроки выбирают Lucky Jet.
Бонусы и промокоды в Lucky Jet
В Lucky Jet вас ждут щедрые бонусы и эксклюзивные промокоды, которые помогут увеличить ваш баланс и продлить удовольствие от игры! Мы ценим активных игроков и регулярно запускаем новые акции, чтобы сделать ваш игровой процесс еще выгоднее.
Актуальные бонусные предложения
Бонус 500% на первый депозит
Используйте промокод LuckyJetTeam при пополнении счета и получите увеличение депозита в 5 раз! Это отличная возможность начать игру с солидным запасом.
Еженедельные акции и фриспины
Чем больше вы играете, тем больше подарков получаете! Участвуйте в регулярных промо-акциях и получайте фриспины, бонусные деньги и дополнительные награды за активность.
Кэшбэк до 10%
Проиграли? Не беда! В Lucky Jet вы можете вернуть часть потерянных средств благодаря системе кэшбэка. Еженедельно вам будет начисляться до 10% возврата от проигранных ставок.
Следите за новыми акциями! Мы постоянно обновляем бонусные предложения, поэтому не упустите возможность воспользоваться самыми выгодными промо. Подписывайтесь на новости и следите за актуальными акциями, чтобы всегда быть в выигрыше!
Используйте бонусы и повышайте свои шансы на победу в Lucky Jet!
Как начать играть в Lucky Jet
Готовы испытать удачу и выиграть по-крупному? Следуйте этим простым шагам:
Зарегистрируйтесь на официальном сайте 1win. Процесс регистрации занимает всего пару минут.
Пополните счет удобным для вас способом: банковской картой, электронными кошельками или даже криптовалютой.
Откройте Lucky Jet в разделе казино и приготовьтесь к динамичному игровому процессу.
Сделайте ставку и следите за ростом коэффициента. Чем выше он поднимается – тем больше ваш потенциальный выигрыш.
Выведите выигрыш до того, как Lucky Jet взлетит! Главное – не жадничать и вовремя остановиться, иначе ставка сгорит.
Используйте стратегии, анализируйте предыдущие раунды и комбинируйте ставки, чтобы увеличить свои шансы на победу!
Look of the Week: Kendrick Lamar’s Super Bowl pants signal the return of flares
кракен онион
This year’s Super Bowl halftime show was hardly a fashion extravaganza, with headliner Kendrick Lamar keeping things simple in a backwards cap and motorbike-style varsity jacket, which he kept on throughout.
And without the costume-change roulette we’ve come to expect of halftime shows, the internet fixated on one item in particular: his jeans.
While not quite the bell-bottoms of decades past (the 1970s and the 2000s, specifically), the Compton-born rapper’s washed denim pants flared out at the knee and dragged beneath his heels along the stage at Caesars Superdrome in New Orleans. His silhouette stood in stark contrast to that of record producer Mustard, who made a brief cameo in a pair of outsized jeans straight from the West Coast hip-hop playbook.
Opinions were, as ever, divided on social media. Some users described Lamar’s flares as “women’s jeans” and “Hannah Montana pants,” earning him comparisons to everyone from Jennifer Aniston to country singer Lainey Wilson. Others joked that their moms were looking for a similar pair or that they nodded to millennials, for whom flares were a teenage staple.
But those suggesting his style was outdated, or gender-inappropriate, may not have been paying attention to the recent resurgence of flares — in both womenswear and menswear. After all, Lamar’s jeans were designed by one of the most influential figures in modern fashion, Celine’s former creative director Hedi Slimane, before he departed the French label in October.
Look of the Week: Kendrick Lamar’s Super Bowl pants signal the return of flares
Кракен тор
This year’s Super Bowl halftime show was hardly a fashion extravaganza, with headliner Kendrick Lamar keeping things simple in a backwards cap and motorbike-style varsity jacket, which he kept on throughout.
And without the costume-change roulette we’ve come to expect of halftime shows, the internet fixated on one item in particular: his jeans.
While not quite the bell-bottoms of decades past (the 1970s and the 2000s, specifically), the Compton-born rapper’s washed denim pants flared out at the knee and dragged beneath his heels along the stage at Caesars Superdrome in New Orleans. His silhouette stood in stark contrast to that of record producer Mustard, who made a brief cameo in a pair of outsized jeans straight from the West Coast hip-hop playbook.
Opinions were, as ever, divided on social media. Some users described Lamar’s flares as “women’s jeans” and “Hannah Montana pants,” earning him comparisons to everyone from Jennifer Aniston to country singer Lainey Wilson. Others joked that their moms were looking for a similar pair or that they nodded to millennials, for whom flares were a teenage staple.
But those suggesting his style was outdated, or gender-inappropriate, may not have been paying attention to the recent resurgence of flares — in both womenswear and menswear. After all, Lamar’s jeans were designed by one of the most influential figures in modern fashion, Celine’s former creative director Hedi Slimane, before he departed the French label in October.
Здесь можно купить сейф в москве в магазине сейфов купить сейф в москве
снять квартиру в сочи на длительный
auto transport companies
Зажги твою звезду фарта вместе с “Комета казино”! ?
Салют, авантюрист подвигов! Ты настроен ринуться на космическое вояж, в коем каждая точка обещает невероятные награды да ошеломляющие чувства?
Тогда вам безусловно следовало бы присоединиться к этому эксклюзивному телеграм-каналу https://t.me/s/kometacasino17. Тут вас поджидают совсем не лишь игры, а реальные звездные приключения, насыщенные непредвиденных поворотов и сверкающих сияний удачи!
Почему выбирают наше казино?
Звездные бонусы: Вступай к объединенную группу а возьми начальный комплект бонусов, какой содействует вам быстрее добиться своей задачи. Развлекательные галактики: Наши игровые слоты – это целые миры, кишащие тайнами и даже сокровищами. Исследуй все полностью и конечно же найди свой совершенный аппарат! Конкурсные миры: Участвуй на космических турнирах а также борись во имя пост лучшего геймера вселенной. Наградные пулы в такой мере масштабны, что в силах ослепить даже самую что ни на есть блестящую звезду! Быстрая перевод: Едва только ты одержишь победы, личные капитал окажутся моментально зачислены в собственный аккаунт. Абсолютно никаких задержек – исключительно неподдельная восторг успеха! Помощь круглосуточно: Наш собственный состав постоянно в связи, нацеленный помочь вам при какой угодно положении. Если даже коль ты сбился с пути среди галактик, мы все поможем открыть направление к себе. ?? Каким образом приступить? Легко оформляйте подписку на этот ресурс а потом отправься на рейс! Затем вас подстерегают бесконечные горизонты шансов и даже целое море наслаждения.
Не упустить момент, в тот момент когда ваша светило заблестит светлее каждого!
#kometa #casino #Премии #Выигрыш #KometaCasino #kometacasino
order semaglutide 14mg pill – rybelsus without prescription how to get periactin without a prescription
перейти на сайт https://18ps.ru/info/biznes-plan/planplitka/
Привет, в случае если ты ищете игровые автоматы, которые действительно приносят крупные призы, ты попали как раз куда нужно! Наша команда сделали для тебя лучшие 5 игровых автоматов, какие за последний месяц сотворили родных игроков счастливее. Это все не просто слова — это факты, основанные в реальной исчислении выплат.
Применяйте бонусы и фриспины для испытания свежих игровых автоматов.
Попробуйте эти игровые автоматы на интернет-сайте Starda — и, вероятно, следующий крупный выигрыш будет твоим!
Pinco kazino VIP proqramı ilə əlavə bonuslar qazanın | Pinco casino-da loyallıq proqramı ilə mükafatlar qazanın | Pinco casino-da böyük cekpotlar sizi gözləyir | Pinco kazino ilə mərc dünyasını kəşf edin Pinco AZ rəsmi saytı .
What’s Really Behind the M23 Conflict and Who’s Involved? PLO Lumumba
PLO Lumumba CONGO Conflict
Привет, если вы ищете игровые автоматы, которые вправду дарят большие призы, вы очутились как раз куда нужно! Наша команда сделали ради тебя топ-5 слотов, какие за последний 30 дней сделали наших игроков более радостными. Это не просто речи — данные факты, базирующиеся на реальной исчислении вознаграждений.
Используйте бонусы и фриспины для испытания новых автоматов.
Попробуйте эти игровые автоматы на сайте vodka casino играть online — и, вероятно, будущий крупный выигрыш станет вашим!
квартиры в сочи снять недорого
‘You get one split second’: The story behind a viral bird photo
kraken marketplace
By his own admission, James Crombie knew “very, very little” about starlings before Covid-19 struck. An award-winning sports photographer by trade, his only previous encounter with the short-tailed birds occurred when one fell into his fireplace after attempting to nest in the chimney of his home in the Irish Midlands.
“I always had too much going on with sport to think about wildlife,” said Crombie, who has covered three Olympic Games and usually shoots rugby and the Irish game of hurling, in a Zoom interview.
With the pandemic bringing major events to a halt, however, the photographer found himself at a loose end. So, when a recently bereaved friend proposed visiting a nearby lake to see flocks of starlings in flight (known as murmurations), Crombie brought along his camera — one that was conveniently well-suited to the job.
“You get one split second,” he said of the similarities between sport and nature photography. “They’re both shot at relatively high speeds and they’re both shot with equipment that can handle that.”
On that first evening, in late 2020, they saw around 100 starlings take to the sky before roosting at dusk. The pair returned to the lake — Lough Ennell in Ireland’s County Westmeath — over successive nights, choosing different vantage points from which to view the birds. The routine became a form of therapy for his grieving friend and a source of fascination for Crombie.
“It started to become a bit of an obsession,” recalled the photographer, who recently published a book of his starling images. “And every night that we went down, we learned a little bit more. We realized where we had to be and where (the starlings) were going to be. It just started to snowball from there.”
‘I’ve got something special here’
Scientists do not know exactly why starlings form murmurations, though they are thought to offer collective protection against predators, such as falcons. The phenomenon can last from just a few seconds to 45 minutes, sometimes involving tens of thousands of individual birds. In Ireland, starlings’ numbers are boosted during winter, as migrating flocks arrive from breeding grounds around Western Europe and Scandinavia.
Crombie often saw the birds form patterns and abstract shapes, their varying densities appearing like the subtle gradations of paint strokes. The photographer became convinced that, with enough patience, he could capture a recognizable shape.
Lucky Jet – твой шанс на большие выигрыши!
Попробуй захватывающую краш-игру прямо сейчас! Регистрируйся и получи бонус до 500% на первый депозит с промокодом: LuckyJetTeam.
lucky jet игра
Об игре
Lucky Jet — это не просто игра, а захватывающее приключение, в котором каждый момент может стать решающим! Эта краш-игра бросает вызов вашим инстинктам и способности быстро принимать решения. В основе игры — динамичная механика, где игроки ставят на рост коэффициента, но задача не в том, чтобы ждать до последнего, а вовремя вывести свой выигрыш, прежде чем персонаж взлетит слишком высоко и случится крах.
Чем выше коэффициент, тем более значительная награда! Но не забывайте: в этом азартном путешествии важен каждый момент, ведь именно ваше решение о выводе решит, насколько велик будет ваш выигрыш. Это не просто игра, а настоящее испытание на скорость и удачу! Простые правила, быстрые раунды и реальные выигрыши – вот почему игроки выбирают Lucky Jet.
Бонусы и промокоды в Lucky Jet
В Lucky Jet вас ждут щедрые бонусы и эксклюзивные промокоды, которые помогут увеличить ваш баланс и продлить удовольствие от игры! Мы ценим активных игроков и регулярно запускаем новые акции, чтобы сделать ваш игровой процесс еще выгоднее.
Актуальные бонусные предложения
Бонус 500% на первый депозит
Используйте промокод LuckyJetTeam при пополнении счета и получите увеличение депозита в 5 раз! Это отличная возможность начать игру с солидным запасом.
Еженедельные акции и фриспины
Чем больше вы играете, тем больше подарков получаете! Участвуйте в регулярных промо-акциях и получайте фриспины, бонусные деньги и дополнительные награды за активность.
Кэшбэк до 10%
Проиграли? Не беда! В Lucky Jet вы можете вернуть часть потерянных средств благодаря системе кэшбэка. Еженедельно вам будет начисляться до 10% возврата от проигранных ставок.
Следите за новыми акциями! Мы постоянно обновляем бонусные предложения, поэтому не упустите возможность воспользоваться самыми выгодными промо. Подписывайтесь на новости и следите за актуальными акциями, чтобы всегда быть в выигрыше!
Используйте бонусы и повышайте свои шансы на победу в Lucky Jet!
Как начать играть в Lucky Jet
Готовы испытать удачу и выиграть по-крупному? Следуйте этим простым шагам:
Зарегистрируйтесь на официальном сайте 1win. Процесс регистрации занимает всего пару минут.
Пополните счет удобным для вас способом: банковской картой, электронными кошельками или даже криптовалютой.
Откройте Lucky Jet в разделе казино и приготовьтесь к динамичному игровому процессу.
Сделайте ставку и следите за ростом коэффициента. Чем выше он поднимается – тем больше ваш потенциальный выигрыш.
Выведите выигрыш до того, как Lucky Jet взлетит! Главное – не жадничать и вовремя остановиться, иначе ставка сгорит.
Используйте стратегии, анализируйте предыдущие раунды и комбинируйте ставки, чтобы увеличить свои шансы на победу!
Привет, если ты ищете игровые автоматы, какие вправду приносят крупные призы, вы очутились как раз куда нужно! Мы подготовили ради тебя топ-5 игровых автоматов, которые в последний месяц сотворили родных игроков более радостными. Это все не есть легкие речи – это факты, базирующиеся в существующей исчислении выплат.
Используйте бонусы и бесплатные вращения ради испытания новых игровых автоматов.
Попробуйте эти игровые автоматы на интернет-сайте https://telegra.ph/vodka-bet-vhod-promokod-02-28-3 — а, вероятно, следующий большой выигрыш будет твоим!
Porque e que a FullBet e a melhor plataforma de apostas desportivas no Brasil em 2025?
A FullBet e uma das plataformas de apostas desportivas e jogos de azar online mais populares do Brasil e continua a conquistar os coracoes dos jogadores em 2025. Com licenciamento que garante legalidade e integridade, e tecnologia de seguranca avancada, a FullBet oferece aos utilizadores uma experiencia de jogo confortavel e segura. Depositos convenientes e levantamentos rapidos via PIX, uma aplicacao movel de ultima geracao, regras de bonus transparentes e apoio aos principios do jogo responsavel fazem desta plataforma a escolha ideal para os jogadores brasileiros. Nesta analise, vamos analisar as principais carateristicas do FullBet, desde o processo de registo ate ao fair play, para que possa apreciar todos os seus beneficios.
fulltbet app
Como registar-se no FullBet? Guia detalhado
O registo na plataforma FullBet e simples, rapido e seguro, mas e importante conhecer os detalhes. Iremos detalhar cada passo do processo para que possa criar facilmente uma conta e comecar a apostar. Vamos la! ??
Passo 1: Registo: o primeiro passo no caminho para ganhar o jogo
Para criar uma conta no FullBet, voce precisa ir ao site oficial da plataforma. La voce vera um grande botao “Registro”. Clique nele e proceda ao preenchimento do formulario.
Que dados devem ser introduzidos?
Nome e apelido : Forneca dados reais como no seu documento. Isto e importante para a verificacao.
Data de nascimento: A idade minima para jogar e 18 anos. Se for menor de idade, nao tente burlar o sistema, e inutil.
CPF: Este numero e obrigatorio para todos os residentes no Brasil.
Pais e endereco: Escreva seu endereco residencial valido.
Email: O seu email sera utilizado para confirmar a sua conta e receber notificacoes.
Numero de telefone: Para confirmar o registo e receber actualizacoes.
Dados de pagamento: E opcional na etapa de cadastro, mas sera necessario para depositos e saques. Verifique se as informacoes correspondem ao seu CPF.
Passo 2: Confirmacao de conta
Depois de ter preenchido todos os campos, a FullBet enviar-lhe-a dois codigos de confirmacao:
Para o email: Verifique a sua caixa de entrada ou pasta de spam. Encontre um e-mail da FullBet, abra-o e clique no botao “Confirmar”. Demora apenas alguns segundos.
Recebera um SMS com um codigo no seu numero de telefone:. Introduza-o no sitio Web para confirmar o seu numero.
Se nao receber um e-mail ou SMS, certifique-se de que introduziu os dados corretos e verifique a sua ligacao a Internet.
Полезные советы по покупке диплома о высшем образовании без риска
Мы можем предложить документы престижных ВУЗов, расположенных на территории всей РФ. diplom5.com/kupit-attestat-7
Как получить диплом техникума с упрощенным обучением в Москве официально
Добрый день!
Где приобрести диплом специалиста?
Мы можем предложить дипломы любой профессии по приятным тарифам. Стоимость зависит от выбранной специальности, года выпуска и университета. Стараемся поддерживать для заказчиков адекватную ценовую политику. Важно, чтобы документы были доступны для подавляющей массы граждан.
Покупка документа, подтверждающего окончание ВУЗа, – это выгодное решение. Для сравнения просто подсчитайте, сколько вам пришлось бы потратить своих денег на оплату 5 лет обучения, на питание, аренду квартиры (если студент иногородний), на ежедневный проезд до ВУЗа и прочие издержки. Получается приличная сумма, намного превосходящая цены на нашу услугу. А ведь все это время можно уже успешно работать, занимаясь собственной карьерой.
Готовый диплом со всеми печатями и подписями отвечает условиям и стандартам, неотличим от оригинала – даже со специально предназначенным оборудованием. Не стоит откладывать собственные мечты и задачи на несколько лет, реализуйте их с нами – отправьте простую заявку на изготовление документа уже сегодня!
Диплом о среднем специальном образовании – не проблема! tutdiploms.com/
диплом университета купить
Привет!
Мы изготавливаем дипломы любых профессий по приятным тарифам. Цена может зависеть от конкретной специальности, года получения и образовательного учреждения: [url=http://rdiploman.com/]rdiploman.com/[/url]
Доска объявлений – https://dogovorimsia.ru/ это привосходство и забота о ваших объявлениях.
analizador de vibraciones
Sistemas de balanceo: importante para el rendimiento uniforme y eficiente de las equipos.
En el mundo de la ciencia avanzada, donde la rendimiento y la confiabilidad del equipo son de suma relevancia, los aparatos de ajuste desempeñan un rol vital. Estos sistemas especializados están creados para balancear y estabilizar piezas rotativas, ya sea en herramientas manufacturera, medios de transporte de transporte o incluso en electrodomésticos caseros.
Para los profesionales en conservación de equipos y los profesionales, utilizar con aparatos de calibración es esencial para asegurar el rendimiento suave y fiable de cualquier aparato rotativo. Gracias a estas herramientas innovadoras innovadoras, es posible minimizar notablemente las vibraciones, el sonido y la carga sobre los sujeciones, mejorando la vida útil de elementos valiosos.
Asimismo importante es el función que desempeñan los aparatos de ajuste en la asistencia al comprador. El soporte especializado y el mantenimiento regular usando estos dispositivos posibilitan dar servicios de excelente estándar, incrementando la contento de los consumidores.
Para los dueños de proyectos, la aporte en equipos de calibración y detectores puede ser importante para aumentar la efectividad y eficiencia de sus equipos. Esto es especialmente relevante para los emprendedores que dirigen pequeñas y medianas organizaciones, donde cada aspecto cuenta.
Asimismo, los equipos de equilibrado tienen una gran aplicación en el área de la seguridad y el supervisión de calidad. Facilitan localizar potenciales errores, previniendo reparaciones costosas y daños a los sistemas. Además, los información recopilados de estos equipos pueden aplicarse para maximizar procesos y incrementar la visibilidad en sistemas de consulta.
Las campos de implementación de los equipos de calibración comprenden múltiples ramas, desde la elaboración de bicicletas hasta el monitoreo ambiental. No interesa si se considera de enormes elaboraciones industriales o modestos talleres domésticos, los sistemas de balanceo son necesarios para garantizar un desempeño eficiente y sin riesgo de detenciones.
куплю аттестат камень куплю аттестат камень .
Codigo de bonus 1xcasino Mauritania
отдых в крыму цены
mostbet kz войти http://www.mostbet3007.ru .
UTLH: Eintrittskarte in die Zukunft der dezentralisierten Finanzen mit garantierter WachstumsrateWenn klassische Finanzinstrumente an Wirksamkeit verlieren und die Inflation Ersparnisse auffrisst, eröffnet die Welt der Kryptowährungen neue Horizonte für kluge Investoren. Aber wo findet man ein Token mit echtem Wert und nicht mit leeren Versprechungen? UTLH bricht mit Stereotypen und bietet fertige Lösungen: Staking mit einer Rendite von 24% pro Jahr, vergünstigte Finanzierung über die Universelle Finanzhilfe (UFP) und eine einzigartige Wirtschaft, die auf einer begrenzten Emission basiert. Das bedeutet, dass Ihr Kapital nicht nur erhalten bleibt, sondern auch wächst, während jeder Inhaber echte Vorteile erhält anstelle von sinnlosen Spekulationen.1. Warum wird UTLH bereits als „Durchbruch“ in der DeFi-Welt bezeichnet?1.1. Begrenzte Emission = Knappheit und PreissteigerungWeniger als 1 Million Coins: Im Gegensatz zu Projekten, die Token „nachdrucken“ und den Preis stürzen lassen können, hat UTLH ein strikt festgelegtes Angebot.Verbrennungsmechanismus: Ein Teil der Emission wird regelmäßig zerstört, was die Knappheit verstärkt und den Kursanstieg stimuliert.1.2. Echte Anwendung im UFP-ProgrammPfandaktiv: Möchten Sie eine Finanzierung zu niedrigen Zinssätzen erhalten? Verpfänden Sie UTLH und lösen Sie Ihre finanziellen Aufgaben ohne Bürokratie und unnötige Dokumente.Garantierte Nachfrage: Jeder neue Teilnehmer im UFP erwirbt und sperrt Token, was ihren Wert steigert.2. Staking mit 24% Jahresrendite: Wachsen Sie mit dem Markt2.1. Einfach und profitabel2% monatlich: Alle Zahlungen werden automatisch durch einen Smart Contract abgewickelt, niemand kann sie ändern oder annullieren.Niedrigschwelliger Einstieg: Es reicht aus, nur 1 UTLH zu besitzen, um bereits eine hohe Rendite zu erzielen, die auf klassischen Einlagen nicht verfügbar ist.2.2. Mehrfaches WachstumspotenzialStellen Sie sich vor, Sie erhalten stabile Zinsen aus dem Staking und beobachten gleichzeitig, wie der Tokenpreis aufgrund der begrenzten Emission und der Verbrennung wächst. Dies ist ein doppelter Vorteil, der Investoren anzieht, die auf eine langfristige Strategie setzen.3. Zuverlässige Infrastruktur und starke Gemeinschaft3.1. Binance Smart Chain (BSC)Niedrige Gebühren und hohe Bestätigungsgeschwindigkeit von Transaktionen.Einfache Integration mit den größten DEX und Wallets (PancakeSwap, Trust Wallet, MetaMask).3.2. UTL Club: Unterstützung und PartnerschaftEin geschlossener Club für Unternehmer und Investoren, der bereits Tausende von Teilnehmern weltweit umfasst.Zugang zu Briefings, Schulungs-Webinaren: neue Ideen, Kontakte, gegenseitig vorteilhafte Projekte.Gesteuerte Ökosystem: Jeder Teilnehmer kann überprüfen und sicherstellen, dass die Emission unter Kontrolle ist und die Staking-Bedingungen fair sind.4. Hauptvorteile für InvestorenHohe Rendite ohne Spekulationen: 24% pro Jahr ist ein stabiler Satz, der durch Smart Contracts und nicht durch die Versprechungen von „Wunder-Tradern“ gewährleistet wird.Echtes Pfand: UTLH wird für die Aufnahme von vergünstigten Krediten verwendet, was eine stabile Nachfrage erzeugt, die unempfindlich gegenüber Marktschwankungen ist.Begrenztes Angebot: Nichts stärkt den Kurs so wie die schrittweise Reduzierung der Emission bei wachsender Popularität des Tokens.Langfristiges Potenzial: Das UFP-Programm, die aktive Gemeinschaft und die internationale Expansion garantieren, dass das Interesse an UTLH nicht nachlässt.5. Wie man sich UTLH anschließt und mit dem Verdienen beginntErstellen Sie ein BSC-kompatibles Wallet (MetaMask, Trust Wallet).Kaufen Sie UTLH an einer empfohlenen Börse oder über das persönliche Konto im Club.Richten Sie Staking ein: Nur wenige Klicks in der Benutzeroberfläche, und Ihre Einzahlung wird 2% monatlich abwerfen.Nutzen Sie die UFP-Möglichkeiten (falls nötig): Verpfänden Sie den Token für eine schnelle und günstige Finanzierung ohne Bürokratie und Bankbeschränkungen.6. Fazit: Werden Sie Teil der neuen FinanzlandschaftUTLH ist die Antwort auf die Herausforderungen der modernen Welt, in der Inflation und ineffiziente Banksysteme das Vertrauen in traditionelle Finanzen untergraben. Hier gibt es keine leeren Worte: Der Token wird durch eine begrenzte Emission gestützt, erfordert echtes Pfand für vergünstigte Kredite und bringt großzügige passive Einkünfte aus dem Staking. Diese Kombination macht UTLH von einem weiteren „Krypto-Projekt“ zu einem vollwertigen Finanzinstrument, das Zuverlässigkeit und Kapitalwachstum gewährleistet.Wenn Sie nach einer Möglichkeit suchen, intelligent zu investieren, mit doppeltem Gewinn (durch Staking und Kurswachstum) und gleichzeitig Zugang zu vergünstigten Krediten in der Zukunft zu erhalten, ist UTLH Ihre ideale Wahl. Schließen Sie sich der UTL Club-Gemeinschaft an und bauen Sie noch heute die neue finanzielle Zukunft!
Где заказать диплом по актуальной специальности? купить диплом 2012 года
Привет!
Заказ документа о высшем образовании через качественную и надежную компанию дарит массу плюсов для покупателя. Такое решение позволяет сберечь как личное время, так и серьезные финансовые средства. Однако, только на этом выгода не ограничивается, достоинств гораздо больше.Мы можем предложить дипломы любых профессий. Дипломы производят на фирменных бланках государственного образца. Доступная стоимость в сравнении с огромными тратами на обучение и проживание в чужом городе. Покупка диплома об образовании из российского института будет выгодным шагом.
Быстро купить диплом о высшем образовании: bricklink.com/aboutMe.asp?u=diplomygroup
1 win регистрация http://1win16.com.kg .
1win mx http://www.1win7.com.mx .
Заказать диплом о высшем образовании !
Эксперты с высшим образованием всегда ценились на рынке труда. Диплом университета необходим, чтобы доказать свой высокий профессионализм. Он дает понять начальству, что специалист обладает важными знаниями чтобы на отличном уровне выполнить свои задачи. Но что делать, когда знания есть, а соответствующего документа нет? Покупка диплома поможет решить эту проблему. Покупка диплома ВУЗа РФ у нас является надежным делом, так как документ будет заноситься в реестр. Печать производится на специальных бланках, установленных государством. Быстро приобрести диплом университета brawlstarsacc.listbb.ru/viewtopic.php?f=3&t=1064
[url=][/url]
Создание и продвижение сайтов. Интернет-маркетинг!
Мы предлагаем актуальные новости, подробные обзоры и экспертные советы по всем аспектам веб-разработки:
современные тенденции в веб-дизайне, оптимизация под поисковые системы (SEO), контент-маркетинг, интеграция CRM-систем и многое другое.
У нас вы найдете полезные рекомендации для владельцев сайтов и разработчиков: как создать интуитивно понятный интерфейс,
повысить скорость загрузки страниц, обеспечить мобильную адаптацию и улучшить пользовательский опыт.
Мы также поможем разобраться в юридических нюансах, связанных с созданием и поддержкой веб-ресурсов.
Следите за нашими обзорами ключевых событий в мире веб-разработки, узнавайте о новых инструментах и технологиях,
а также об изменениях в стандартах и требованиях. Кроме того, мы делимся советами по выбору хостинга,
оптимизации контента и продвижению сайтов в социальных сетях.
Только проверенная информация от ведущих специалистов отрасли — аналитика, прогнозы и практические советы.
Подписывайтесь и будьте в курсе всех новостей! С нами ваш веб-ресурс станет успешным и востребованным!
Сайт silaseo.ru
[url=][/url]
https://fernandolzhl52963.pointblog.net/1xbet-promo-code-bonus-1950-150-free-spins-77028322
why not look here brd bitcoin wallet
Добрый день!
Купить диплом университета по выгодной цене можно, обращаясь к проверенной специализированной фирме. Заказать диплом о высшем образовании: dip-lom-rus.ru/kupit-diplom-ufa-5/
By offering fast and efficient swaps with low fees, SimpleSwap ensures a smooth trading experience for all users, whether you’re looking to convert your digita https://simple-swap.us/
בפתאומיות לנרתיק שלי. לא שמתי לב מתי הוא הספיק להתפשט בדירה דיסקרטית. – אתה חולם בדירה דיסקרטית…דמיין שאתה חולם שאתה מנשק מאוד מעניינת להכיר אותי. עניתי, התחלתי להתכתב עם נערת ליווי בסופו של דבר הוסכם כי נערת ליווי תגיע לעיר שלי במיוחד כדי לבלות הזמנת זונות
Приобрести диплом о высшем образовании
Мы предлагаем документы об окончании любых ВУЗов РФ. http://www.bieresgeorges.com
appleute GmbH ist ein internationales Software-Entwicklungshaus mit Standorten in Deutschland und Indien. Angefangen hat alles mit einer Gruppe von Freunden, die sich als Freelancer zusammentaten. Jetzt entwickeln wir Produkte für Kunden auf der ganzen Welt. In den letzten beiden Blogposts dieser Reihe haben wir euch I) nicht-kommerzielle Apps und II) Monetarisierungs-Strategien für kommerzielle Apps zum Kosten einsparen vorgestellt. In diesem Post erläutern wir Strategien für kommerzielle Apps, die das Ziel verfolgen Geld zu verdienen. Die Entwickler sagen zwar über ihre App: „Nicht einmal Vielgeher wie Forrest Gump oder Hape Kerkeling würden mit WeWard reich werden.“ Allerdings lässt sich, ohne etwas zu tun, als das, was man ohnehin schon macht, nebenbei Geld verdienen. Und beim Wandern kommen schnell 20.000 Schritte pro Tag und mehr zusammen.
http://inphilhaystur1983.iamarrows.com/null-brawl-telegram
Fahre mit den Besten der Welt im Bike Unchained 3 Handyspiel. Auflegen mit der Qualle Weitere tolle Games für unterwegs Uptodown ist ein Multiplattform-App-Store, der auf Android spezialisiert ist. Unser Ziel ist es, einen freien und offenen Zugang zu einem großen Katalog von Apps ohne Einschränkungen zu bieten, während wir eine legale Vertriebsplattform bereitstellen, die von jedem Browser aus und auch über die offizielle native App zugänglich ist. SmartDroid.de » Android » No-Bullshit Games: Liste mit Android-Spielen ohne Werbung und In-App-Käufen Diese Offline-Spiele sind nicht nur ein hervorragender Zeitvertreib, sondern können auch deine Fähigkeiten in verschiedenen Bereichen fördern. Puzzlespiele sind etwa großartig, um das logische Denken und die Problemlösungsfähigkeiten zu verbessern, während Action- und Abenteuerspiele deine Reaktionsgeschwindigkeit und strategische Planung schärfen können. Kartenspiele und Brettspiele fördern wiederum Geduld und taktisches Denken.
https://public.tableau.com/app/profile/adrian.neow/vizzes
Не упустите возможность понять все о казино водка
Заходите по ссылке и ознакамливайтесь полную работу прямо же.
https://t.me/s/Official_kometa19
рюкзак черный
娛樂城是什麼
娛樂城是一個線上賭博平台,提供各式各樣的娛樂遊戲,讓玩家能在網路上參與賭博娛樂。玩家可以透過電腦或手機,隨時隨地進行遊戲,並體驗到類似實體賭場的刺激感。娛樂城的遊戲種類多樣,主要包括賭場遊戲、體育博彩、電子遊戲等。在賭場遊戲方面,玩家常見的選擇有百家樂、輪盤、撲克、二十一點等經典賭博項目。這些遊戲通常需要玩家依賴一定的技巧或運氣,來獲得獎金。電子遊戲則包括各種風格的老虎機遊戲,這些遊戲畫面華麗且玩法簡單,非常吸引玩家的注意。而體育博彩則讓玩家根據各類體育比賽的結果進行下注,體驗不同於傳統賭博的樂趣。娛樂城通常還會提供即時直播遊戲,讓玩家可以與真人荷官互動,提升遊戲的真實感。此外,娛樂城平台經常提供優惠活動、註冊獎金等,吸引玩家註冊並增加活躍度。總的來說,娛樂城是集各種線上賭博遊戲於一身的娛樂平台,玩家可以在這裡享受刺激的遊戲體驗。然而,應該注意理性投注,避免過度沉迷。
продвижение сайта москва продвижение сайта москва .
Хватит довольствоваться малым! Пришло время раскрыть весь свой потенциал и сорвать крупный куш!
“Топ Рейтинг Казино” в Telegram – это твой детонатор к взрывным выигрышам!
Мы не просто рассказываем о казино, мы даем тебе инструменты для победы:
Разбор полетов каждого казино: От А до Я! Мы изучаем все аспекты, от лицензии и безопасности до RTP слотов и лимитов на вывод средств. Никаких сюрпризов! Секретные коды к бонусам: Получи доступ к эксклюзивным промокодам и фриспинам, которые увеличат твой банкролл с первого дня! Аналитика и стратегии от профи: Узнай, как играть умно и повысить свои шансы на успех! Мы делимся проверенными стратегиями, которые работают! Общение с единомышленниками: Делись опытом, задавай вопросы и получай советы от других игроков в нашем дружном сообществе!
Прекрати терять деньги на сомнительных платформах! Присоединяйся к “Топ Рейтинг Казино” и начни играть как профессионал!
https://telegra.ph/Podnimaem-vash-portal-v-top-Google-za-nedelyu-sekret-uspeha-v-gembling-strategii-03-15-5
Почему тебе стоит подписаться?
Экономия времени и денег: Мы уже сделали всю работу за тебя! Не нужно тратить часы на поиски и сравнения.
Максимальная выгода: Получай лучшие бонусы и промокоды, доступные только для наших подписчиков.
Безопасность: Мы рекомендуем только проверенные и надежные казино с лицензией и хорошей репутацией.
Не жди, пока удача постучит в другую дверь! Подписывайся на “Топ Рейтинг Казино” и стань повелителем азарта!
Приветствую!
Для некоторых людей, купить диплом университета – это необходимость, шанс получить достойную работу. Но для кого-то – это желание не терять время на учебу в ВУЗе. Что бы ни толкнуло вас на такой шаг, мы готовы помочь вам. Оперативно, профессионально и по разумной цене изготовим документ любого ВУЗа и любого года выпуска на настоящих бланках со всеми подписями и печатями.
Основная причина, почему многие прибегают к покупке документа, – желание занять хорошую должность. К примеру, знания позволяют человеку устроиться на желаемую работу, но подтверждения квалификации не имеется. Если для работодателя важно наличие “корочки”, риск потерять место работы довольно высокий.
Заказать документ о получении высшего образования можно в нашей компании в Москве. Мы предлагаем документы об окончании любых университетов РФ. Вы получите диплом по любым специальностям, включая документы СССР. Гарантируем, что при проверке документа работодателем, каких-либо подозрений не возникнет.
Ситуаций, которые вынуждают купить диплом ВУЗа очень много. Кому-то прямо сейчас нужна работа, в итоге необходимо произвести хорошее впечатление на начальника при собеседовании. Другие мечтают попасть в серьезную компанию, чтобы повысить свой статус и в будущем начать свой бизнес. Чтобы не терять драгоценное время, а сразу начинать удачную карьеру, используя врожденные таланты и приобретенные навыки, можно заказать диплом в интернете. Вы сможете стать полезным для социума, обретете денежную стабильность в максимально короткий срок- аттестат за 9 класс купить
Здравствуйте!
Мы предлагаем дипломы психологов, юристов, экономистов и других профессий по приятным ценам. Стоимость может зависеть от конкретной специальности, года получения и ВУЗа: diplomanrussians.com/
Хватит довольствоваться малым! Пришло время раскрыть весь свой потенциал и сорвать крупный куш!
“Топ Рейтинг Казино” в Telegram – это твой детонатор к взрывным выигрышам!
Мы не просто рассказываем о казино, мы даем тебе инструменты для победы:
Разбор полетов каждого казино: От А до Я! Мы изучаем все аспекты, от лицензии и безопасности до RTP слотов и лимитов на вывод средств. Никаких сюрпризов! Секретные коды к бонусам: Получи доступ к эксклюзивным промокодам и фриспинам, которые увеличат твой банкролл с первого дня! Аналитика и стратегии от профи: Узнай, как играть умно и повысить свои шансы на успех! Мы делимся проверенными стратегиями, которые работают! Общение с единомышленниками: Делись опытом, задавай вопросы и получай советы от других игроков в нашем дружном сообществе!
Прекрати терять деньги на сомнительных платформах! Присоединяйся к “Топ Рейтинг Казино” и начни играть как профессионал!
https://telegra.ph/Kak-vybrat-luchshee-onlajn-kazino-sovety-ot-ehkspertov-03-16-6
Почему тебе стоит подписаться?
Экономия времени и денег: Мы уже сделали всю работу за тебя! Не нужно тратить часы на поиски и сравнения.
Максимальная выгода: Получай лучшие бонусы и промокоды, доступные только для наших подписчиков.
Безопасность: Мы рекомендуем только проверенные и надежные казино с лицензией и хорошей репутацией.
Не жди, пока удача постучит в другую дверь! Подписывайся на “Топ Рейтинг Казино” и стань повелителем азарта!
купить диплом в темиртау
ремонт офиса цена за м2 – капитальный ремонт дома, ремонт квартиры стоит
Где приобрести диплом по необходимой специальности?
Наша компания предлагает выгодно и быстро приобрести диплом, который выполняется на бланке ГОЗНАКа и заверен печатями, водяными знаками, подписями. Диплом способен пройти любые проверки, даже с использованием специфических приборов. Достигайте цели быстро и просто с нашими дипломами. Купить диплом университета! sntnika.forumex.ru/viewtopic.php?f=26&t=1010
Задался вопросом: можно ли на самом деле купить диплом государственного образца в Москве? Был приятно удивлен — это реально и легально!
Сначала искал информацию в интернете на тему: купить диплом в благовещенске, купить диплом образования в ярославле, купить диплом производство, купить дипломы о высшем медицинском, купить реальный диплом о высшем образовании и получил базовые знания. В итоге остановился на материале: [url=http://kyc-diplom.com/diplom-articles/kupit-diplom-2017-goda.html/]kyc-diplom.com/diplom-articles/kupit-diplom-2017-goda.html[/url]
Мы изготавливаем дипломы любой профессии по доступным тарифам. Цена может зависеть от выбранной специальности, года получения и образовательного учреждения. Всегда стараемся поддерживать для заказчиков адекватную ценовую политику. Для нас важно, чтобы документы были доступны для подавляющей массы наших граждан. купить диплом о высшем в сочи
где купить алкоголь ночью где купить алкоголь ночью .
Откройте мир азарта с Flagman Casino!
В 2025 году Flagman Casino стало топ-выбором для русскоязычных игроков. Официальный сайт https://t.me/s/f32dfsf23rf6 предлагает лучшие онлайн-слоты, рулетку и игры с живыми дилерами. Играйте на рубли с депозитом от 100 рублей и выводите выигрыши быстро!
Преимущества Flagman Casino:
Лицензионные слоты от Amatic: Book of Fortune, Hot Seven, Wild Stars.
Бонус за регистрацию: 50 FS по промокоду BONCASIN.
Приветственный пакет: 225% + 500 FS на первый депозит.
Еженедельный кэшбэк до 20%.
Как начать играть:
Перейдите на сайт казино.
Зарегистрируйтесь, указав промокод PORTABLE.
Пополните счет и получите бонусы.
Flagman Casino — это честное онлайн-казино с удобным интерфейсом и крупными выигрышами. Присоединяйтесь к лучшей платформе азартных игр 2025 года и испытайте удачу уже сегодня! ??
her comment is here https://web-lumiwallet.com
Топ Лицензированных Онлайн-Казино на Деньги: Играй Безопасно и Выигрывай!
Представляем рейтинг проверенных онлайн-казино на реальные деньги, имеющих лицензии для вашей безопасной и надежной игры. Выбирайте только лучшие площадки для азартных развлечений!
Основные критерии для онлайн-казино с лицензией
При выборе онлайн-казино мы учитываем следующие важные критерии:
Наличие лицензии и надежная регуляция
Безупречная репутация и позитивные отзывы игроков
Обширный выбор игр от ведущих провайдеров
Щедрые бонусы и регулярные акции для всех игроков
Удобные и безопасные методы ввода и вывода средств
Быстрые и гарантированные выплаты выигрышей
Защита личных данных и безопасность аккаунта
Круглосуточная и оперативная поддержка клиентов
Удобные мобильные версии и приложения для игры в любом месте
Интуитивно понятный и современный интерфейс сайта
Рейтинг 15 лицензированных онлайн-казино
https://t.me/reyting_casino_top
Выбирая любое из этих лицензированных онлайн-казино, вы гарантируете себе честную игру, безопасность и отличный игровой опыт. Наслаждайтесь надежными площадками и выигрывайте с уверенностью!
sports news
Мы изготавливаем дипломы любой профессии по доступным ценам. Стоимость будет зависеть от конкретной специальности, года выпуска и университета. Всегда стараемся поддерживать для заказчиков адекватную ценовую политику. Важно, чтобы документы были доступны для большинства граждан. купить диплом о средне специальном
Купить диплом ВУЗа!
Мы предлагаем документы учебных заведений, которые расположены на территории всей РФ.
kupitediplom0027.ru/kupit-diplom-texnikum-4
Muchos de los mejores casinos online ofrecen una amplia variedad de sus juegos en modo gratuito para que puedas empezar a practicar sin compromisos. A continuación, encontrarás una lista con algunos de los juegos de casino gratis más populares disponibles. Puedes explorar nuestro completo catálogo de juegos en Casino.org, diseñado meticulosamente por nuestro equipo. Si decides que deseas jugar por dinero real, también hemos identificado los mejores casinos online para maximizar tu experiencia de juego. Las personas que disfrutan de los juegos de azar sobre la marcha encontrarán mucho que apreciar sobre National Casino. Aunque se puede jugar en computadoras de escritorio, el casino también está completamente optimizado para juegos de azar móviles y es 100% compatible con dispositivos de mano Android e iOS, como tabletas y teléfonos inteligentes. Operado por TechSolutions Group NV, National Casino tiene una licencia de juego de la Autoridad de Juegos de Curazao y ofrece cientos de juegos divertidos y emocionantes para jugadores nuevos y expertos.
http://epimorni1977.tearosediner.net/adventinteractive-com-pk
The Unified Payments Interface (UPI), which provides quick and easy payment capabilities, has completely changed financial activities in India. These days, UPI is easily incorporated into online gaming platforms, offering safer and more convenient ways to withdraw money. With only a few touches on their smartphone displays, players can move their online earnings from games like Big Cash straight to their bank accounts. Players can take advantage of this function to enjoy their winnings outside of the virtual game world. Big Cash is the top app for instant rummy cash withdrawals, giving users a fast and secure option to withdraw UPI. The whole procedure is really easy to use and seamless, which improves the game experience. In the upper right corner of the mines game screen, the player will find a button with the name of the game, which also informs the number of mines that are distributed among the 25 positions on the board. Each bet in this game can be the difference between winning or losing, depending on the number of mines chosen.
Discover PancakeSwap, a top DEX on Binance Smart Chain for fast, low-cost crypto swaps, yield farming, and DeFi solutions. https://pancakeswapdefi.org/
Мы изготавливаем дипломы любой профессии по разумным ценам. Основные преимущества покупки документов в нашем сервисе
Вы заказываете документ через надежную фирму. Это решение сэкономит не только средства, но и время.
На этом преимущества не заканчиваются, их гораздо больше:
• Дипломы делаем на подлинных бланках со всеми печатями;
• Дипломы любого ВУЗа России;
• Цена значительно ниже той, которую довелось бы платить на очном и заочном обучении в ВУЗе;
• Удобная доставка в любые регионы Российской Федерации.
Приобрести диплом о высшем образовании– http://automotive.copiny.com/question/details/id/1061177/ – automotive.copiny.com/question/details/id/1061177
кракен даркнет – кракен зеркало, кракен маркетплейс
gokong88
Bet on sports and casino games with 888Starz Bet and play smart.
провести соут в москве провести соут в москве .
https://penzu.com/p/e555747c40f332d6
https://qr.ae/pYQf5e
https://1xbet-promo-code-today.voog.com/
over here
backpack wallet
Заказать диплом о высшем образовании!
Мы готовы предложить документы любых учебных заведений, которые расположены в любом регионе Российской Федерации.
diplom-club.com/kupit-diplom-vuza-s-zaneseniem-v-reestr-4
Бытовки и передвижные помещения: практичное способ для ваших задач
Вагончики и блок-контейнеры организовывают создать место для деятельности, помещение для хранения или временный модуль. Наши специалисты предлагаем сооружения, которые соответствуют высоким стандартам долговечности и эргономики.
Особенности
Устойчивость. Каждая контейнеры выполнены из компонентов, устойчивых к нагрузкам и природным явлениям.
Скорость доставки. Конструкция транспортируется в пределах 1–2 рабочих дней после подписания договора.
Гибкая настройка. Осуществляется компоновка защиты от холода, электропроводки или вентиляции.
Где применяются
На строительных объектах для организации склада или оборудования места для персонала.
Во время акций для создания информационного центра или склада оборудования.
В качестве временно используемых помещений или операционных штабов.
Выгоды
Оптимизация времени. Отпадает потребность строить временные помещения.
Комфорт. Условия, которые усиливают производительность труда бригады.
Адаптивность. Шанс проката или покупки под индивидуальные нужды и финансовые возможности.
Пример использования
Фирма-застройщик использовала временную конструкцию для размещения оборудования и места для рабочих. Модуль была доставлена за сутки, с специальным утеплением. Заказчик обратил внимание на оптимизацию среды и сокращение простоя.
Как связаться с нами
Для подачи заявки следует позвонить с нами. Дадим всю необходимую информацию, окажем помощь найти правильный путь и выполним перевозку.
Воздушные шарики Липецк на свадьбу
Воздушные шары на 23 февраля
kra29 at – kra30 at, кракен магазин
трансформатор тмг трансформатор тмг .
Списание долгов по 127-ФЗ лучшее решение, когда у вас начались просрочки и уже нечем платить за кредиты [url=http://bankrotstvo-v-moskve123.ru]http://bankrotstvo-v-moskve123.ru[/url] .
1win.pro [url=1win6001.ru]1win6001.ru[/url] .
Анонимные транзакции в интернете – как установить Tor браузер, актуальные ссылки на сайт Кракен
Где заказать диплом по нужной специальности?
Мы предлагаем документы об окончании любых ВУЗов Российской Федерации. Документы производятся на подлинных бланках государственного образца. daguhub.com/read-blog/2439_gde-mozhno-kupit-attestat-za-11.html
Покупка документа о высшем образовании через надежную компанию дарит много достоинств. Данное решение дает возможность сберечь как личное время, так и значительные финансовые средства. Впрочем, только на этом выгоды не ограничиваются, плюсов значительно больше.Мы изготавливаем дипломы любых профессий. Дипломы изготавливаются на оригинальных бланках. Доступная цена сравнительно с большими затратами на обучение и проживание. Покупка диплома университета будет разумным шагом.
Купить диплом о высшем образовании: diplomservis.com/diplom-kupit-s-zaneseniem-v-reestr-2/
https://ayema.ng/blogs/151186/1xBet-Promo-Code-Unlock-130-Welcome-Offer
MUSICBR.RU — сайт о том, как научиться играть на гитаре с нуля.
Здесь вы найдете видеоуроки и разборы песен на гитаре,
рифмованные (эквиритмические) переводы песен на русском,
а также советы и рекомендации от автора канала «Музыкант вещает» на YouTube.
Сайт musicbr.ru
http://balaklavskiy-16.ru/post/3366/#p3366
Maispin——2025年最新USDT娛樂城,安全、快速、刺激!
歡迎來到 Maispin,2025年最具潛力的新秀 USDT娛樂城!在這裡,您只需提供 錢包地址 即可註冊,無需繁瑣的個人資訊,享受 安全、匿名、快速 的遊戲體驗。Maispin 提供超過 1000種賭場遊戲,涵蓋 真人百家樂、體育投注、老虎機、撲克、輪盤 等經典娛樂,讓您隨時隨地感受頂級賭場的刺激氛圍。我們與世界知名遊戲供應商合作,確保遊戲 公平公正,並提供高額彩金、獎勵活動,讓玩家輕鬆贏大獎!作為 USDT區塊鏈娛樂城,Maispin 存提款秒到帳,無需繁瑣審核,資金流動安全透明,讓玩家更安心地享受遊戲樂趣。立即加入 M宇宙,體驗前所未有的加密娛樂新潮流!
Где заказать диплом специалиста?
Мы изготавливаем дипломы любой профессии по приятным ценам. Мы можем предложить документы техникумов, которые находятся в любом регионе РФ. Вы можете купить качественный диплом от любого заведения, за любой год, включая документы старого образца СССР. Документы выпускаются на бумаге самого высшего качества. Это дает возможность делать государственные дипломы, не отличимые от оригиналов. Документы будут заверены всеми требуемыми печатями и штампами. Всегда стараемся поддерживать для заказчиков адекватную политику тарифов. Для нас очень важно, чтобы документы были доступны для большого количества граждан. diploms-vuza.com/kupit-attestat-shkoli-2-5
https://niceroleplay.getbb.ru/viewtopic.php?f=1&t=4338
Банкротство является прекрасной возможностью списать долги и начать жизнь с чистого листа. Не откладывайте решение проблемы, прочитайте отзывы тех, кто уже прошел процедуру банкротства [url=http://bankrotstvo-v-moskve95.ru]https://bankrotstvo-v-moskve95.ru[/url] .
https://telegra.ph/Luchshie-onlajn-kazino-na-realnye-dengi-v-24-2025-godu-04-02
visit the site Metamask Extension
нержавеющий лист в новосибирске
1wi [url=http://1win6052.ru]1wi[/url] .
Воздушные шарики Липецк
1 вин про [url=https://www.1win6004.ru]https://www.1win6004.ru[/url] .
летние шатры аренда летние шатры аренда .
http://lecode1xbet100.pbworks.com/w/page/160294155/Code%201xBet%20Valide%20%20Bonus%20100%20jusqua%20130%E2%82%AC
Гелиевые шары со скидкой
https://planetfor.me/note/144675
нейросеть для диплома онлайн http://studgen.ru .
Мы изготавливаем дипломы любой профессии по приятным тарифам. Стараемся поддерживать для заказчиков адекватную политику цен. Для нас очень важно, чтобы дипломы были доступны для подавляющей массы граждан.
Заказ диплома, который подтверждает окончание института, – это выгодное решение. Приобрести диплом о высшем образовании: diplom45.ru/diplom-kupit-kolledzha/
этот контент Манго Офис тарифы на звонки
look at here now
russian brides for marriage
Купить диплом академии !
Покупка диплома университета РФ в нашей компании – надежный процесс, так как документ будет заноситься в государственный реестр. Заказать диплом ВУЗа diplomk-v-krasnodare.ru/gde-kupit-diplom-o-visshem-obrazovanii-realnie-otzivi
1 win. http://1win6042.ru .
поддержка мостбет https://www.mostbet6032.ru .
Nucleus Earn is revolutionizing DeFi staking and passive income generation by offering secure, high-yield crypto rewards. With smart contract-powered staking pools, Nucleus Earn allows users to earn rewards effortlessly while maintaining full control over their assets. Whether you’re a beginner or an experienced investor, Nucleus Earn’s decentralized staking platform ensures transparency, security, and optimal returns in the fast-growing world of DeFi. https://nucleusearn.org
мастбет https://mostbet6033.ru .
Say hello to AquaSculpt—a game-changer in weight loss! These AquaSculpt capsules use natural AquaSculpt ingredients to shed pounds and boost confidence. No AquaSculpt side effects, just pure AquaSculpt results—see why in AquaSculpt reviews. Learn AquaSculpt how to use and join thousands who love it. AquaSculpt buy today at http://aquasculpt.one !
cazinouri online moldova [url=1win5012.ru]cazinouri online moldova[/url] .
купить диплом фармацевта с занесением
1win online [url=1win6009.ru]1win6009.ru[/url] .
Купить диплом университета!
Мы предлагаем документы институтов, которые расположены на территории всей России.
diplomaj-v-tule.ru/vnesenie-diploma-v-reestr-bistro-i-nadezhno/
Получить диплом любого университета можем помочь. Купить аттестат в Санкт-Петербурге – diplomybox.com/kupit-attestat-v-sankt-peterburge
online viagra http://viagrarrtt.com/ .
Диплом университета РФ!
Без получения диплома сложно было продвинуться вверх по карьере. Именно по этой причине решение о покупке диплома стоит считать выгодным и целесообразным. Заказать диплом ВУЗа jamestownroleplay.5nx.ru/posting.php?mode=post&f=13&sid=b4f0fc0bdb807317b236fa03fbf381ca
Для успешного продвижения вверх по карьерной лестнице понадобится наличие диплома ВУЗа. Заказать диплом ВУЗа у надежной организации: damdiplomisa.com/kupit-attestat-11-klassov-5/
оценка швейцарских часов в москве оценка швейцарских часов в москве .
1win. pro [url=https://1win6047.ru/]https://1win6047.ru/[/url] .
Мы предлагаем дипломы психологов, юристов, экономистов и любых других профессий по доступным тарифам.– diplomservis.ru/kupit-diplom-o-visshem-obrazovanii-reestr-za-odin-klik/
терапевт в митино терапевт в митино .
why not try these out https://my-sollet.com
wan win [url=https://www.1win7001.ru]https://www.1win7001.ru[/url] .
зайти на сайт электрик томск
Где заказать диплом специалиста?
Наша компания предлагаетвыгодно купить диплом, который выполняется на оригинальной бумаге и заверен мокрыми печатями, штампами, подписями. Наш документ пройдет лубую проверку, даже при помощи специально предназначенного оборудования. Решите свои задачи быстро с нашими дипломами. Заказать диплом о высшем образовании! sameasyourx.copiny.com/question/details/id/1068443
1win betting site [url=www.1win16.com.ng]www.1win16.com.ng[/url] .
баланс ван вин https://1win7014.ru .
Купить диплом можно через сайт компании. 67999mobi.copiny.com/question/details/id/1084549
Приобрести диплом любого университета. Покупка документа о высшем образовании через качественную и надежную компанию дарит ряд плюсов для покупателя. Данное решение помогает сберечь как личное время, так и серьезные финансовые средства. feolet.flybb.ru/viewtopic.php?f=2&t=1105
orm криптовалюты [url=prodvizhenie-kriptovalyuta2.ru]prodvizhenie-kriptovalyuta2.ru[/url] .
Хотите найти что-то особенное?, посетите. Мы предлагаем разнообразные товары. Убедитесь сами, ознакомиться с новинками. Присоединяйтесь к нам. Индивидуальный подход – это то, что мы гарантируем. в Camogear.
купити штани воєні купити штани воєні .
1 вин вход в личный кабинет http://www.1win7004.ru .
купить диплом менеджер
дракон мани http://dragon-money30.com .
Заказать диплом института!
Мы предлагаем дипломы любых профессий по приятным тарифам. Вы покупаете документ через надежную и проверенную временем компанию. : jobs.cntertech.com/employer/frees-diplom
Концентраты позволяющие ощутить качество травки
https://rosinwax.org/
Why axolotls seem to be everywhere — except in the one lake they call home
анальный секс смотреть
Scientist Dr. Randal Voss gets the occasional reminder that he’s working with a kind of superstar. When he does outreach events with his laboratory, he encounters people who are keen to meet his research subjects: aquatic salamanders called axolotls.
The amphibians’ fans tell Voss that they know the animals from the internet, or from caricatures or stuffed animals, exclaiming, “‘They’re so adorable, we love them,’” said Voss, a professor of neuroscience at the University of Kentucky College of Medicine. “People are drawn to them.”
Take one look at an axolotl, and it’s easy to see why it’s so popular. With their wide eyes, upturned mouths and pastel pink coloring, axolotls look cheerful and vaguely Muppet-like.
They’ve skyrocketed in pop culture fame, in part thanks to the addition of axolotls to the video game Minecraft in 2021. These unusual salamanders are now found everywhere from Girl Scout patches to hot water bottles. But there’s more to axolotls than meets the eye: Their story is one of scientific discovery, exploitation of the natural world, and the work to rebuild humans’ connection with nature.
A scientific mystery
Axolotl is a word from Nahuatl, the Indigenous Mexican language spoken by the Aztecs and an estimated 1.5 million people today. The animals are named for the Aztec god Xolotl, who was said to transform into a salamander. The original Nahuatl pronunciation is “AH-show-LOAT”; in English, “ACK-suh-LAHT-uhl” is commonly used.
Axolotls are members of a class of animals called amphibians, which also includes frogs. Amphibians lay their jelly-like eggs in water, and the eggs hatch into water-dwelling larval states. (In frogs, these larvae are called tadpoles.)
Most amphibians, once they reach adulthood, are able to move to land. Since they breathe, in part, by absorbing oxygen through their moist skin, they tend to stay near water.
Axolotls, however, never complete the metamorphosis to a land-dwelling adult form and spend their whole lives in the water.
“They maintain their juvenile look throughout the course of their life,” Voss said. “They’re teenagers, at least in appearance, until they die.”
1win aplicația 1win5027.ru .
mostbet официальный сайт mostbet7003.ru .
https://moklitmjnbds.website3.me/
click here to find out more https://liquifi.tech/
драгон мани демо https://www.dragon-money40.com .
Официальный TG канал проекта – 1win casinо, теперь в вашем Telegram! Подробнее тут
https://t.me/Game_1win_ru/1537
мелбет кж https://melbet1003.ru .
Приобрести диплом института по доступной стоимости возможно, обращаясь к проверенной специализированной компании. Приобрести документ о получении высшего образования вы сможете в нашей компании в Москве. diplomnie.com/kupit-diplom-s-provedeniem-v-reestr-bistro-i-nadezhno
Заказать диплом любого ВУЗа!
Мы можем предложить документы институтов, расположенных на территории всей России.
diplom-ryssia.com/diplom-s-zaneseniem-v-reestr-tsena-2/
1win pro http://1win7009.ru/ .
HyperDrive is transforming the way data is stored and managed through decentralized storage and blockchain hosting solutions. Built for security, scalability, and efficiency, HyperDrive enables businesses, developers, and blockchain projects to store and distribute data without relying on centralized servers. By leveraging Web3 technology and distributed networks, HyperDrive ensures reliable, censorship-resistant, and high-performance storage solutions for the digital era. https://hyperdrive.ink
1vin pro [url=www.1win7026.ru]www.1win7026.ru[/url] .
try this website https://exponent.ink
продвижение сайтов москва продвижение сайтов москва .
you can try here https://nucleusearn.org
hop over to this website https://aquasculpt.best/
Быстро и просто купить диплом о высшем образовании!
Приобрести диплом университета по выгодной стоимости возможно, обратившись к проверенной специализированной фирме. Заказать диплом о высшем образовании: kupit-diplom24.com/kupit-diplom-s-reestrom-garantiya-podlinnosti
visit https://deq.li
мостбет chrono https://mostbet6039.ru/ .
Заказать документ ВУЗа можно в нашей компании. Мы оказываем услуги по продаже документов об окончании любых ВУЗов РФ. Вы сможете получить необходимый диплом по любой специальности, любого года выпуска, включая документы старого образца. Даем 100% гарантию, что в случае проверки документов работодателем, каких-либо подозрений не появится. diplomservis.com/kupit-diplom-cherez-reestr-bez-problem-i-zaderzhek/
Приобрести диплом академии !
Покупка диплома любого университета России у нас является надежным процессом, ведь документ заносится в государственный реестр. Приобрести диплом любого университета diplomus-spb.ru/kupite-diplom-menedzhera-s-zaneseniem-v-reestr-bistro
aviator mostbet [url=https://www.mostbet6014.ru]https://www.mostbet6014.ru[/url] .
https://t.me/kupit_prodat_onkolekarstva/42
Где приобрести диплом по необходимой специальности?
Мы изготавливаем дипломы любой профессии по выгодным тарифам. Важно, чтобы документы были доступны для большого количества наших граждан. Приобрести диплом любого ВУЗа diplomh-40.ru/kupit-diplom-v-reestre-bistro-i-bez-slozhnostej/
Гелиевые шары в Липецке со скидкой
Заказать диплом академии !
Покупка диплома университета РФ в нашей компании – надежный процесс, потому что документ будет заноситься в государственный реестр. Купить диплом об образовании diplomservis.ru/kuplyu-diplom-s-provodkoj-v-vuze-bistro-i-nadezhno-3
Приобрести диплом института по невысокой стоимости вы сможете, обратившись к надежной специализированной компании. Мы оказываем услуги по производству и продаже документов об окончании любых университетов Российской Федерации. Заказать диплом ВУЗа– diplomist.com/diplom-s-zaneseniem-v-reestr-po-nizkoj-tsene-2/
Мы изготавливаем дипломы любой профессии по приятным ценам. Стараемся поддерживать для заказчиков адекватную ценовую политику. Важно, чтобы дипломы были доступны для подавляющей массы наших граждан.
Приобретение документа, который подтверждает окончание института, – это разумное решение. Заказать диплом ВУЗа: kupit-diplomyz24.com/kupit-diplom-texnicheskij-3/
Гелиевые шары Липецк с доставкой
промокоды на ракетку 1win [url=https://1win8002.ru/]промокоды на ракетку 1win[/url] .
http://maps.google.nl/url?q=https://t.me/Top_Spisok_Game/163
Воздушные шары с гелием
https://www.google.com.cy/url?sa=t&url=https://t.me/Top_Spisok_Game/146
http://maps.google.sn/url?q=https://t.me/Top_Spisok_Game/159
букмекеры кыргызстана http://1win8003.ru .
горшки высокие напольные горшки высокие напольные .
крутая музыка крутая музыка .
Appreciation you.
https://hop.cx/111
Купить диплом института по невысокой цене возможно, обращаясь к надежной специализированной компании. Приобрести документ о получении высшего образования вы сможете у нас. diplomt-v-samare.ru/kupit-diplom-instituta-s-provodkoj-po-dostupnoj-tsene-2
https://www.finlandmlbforum.com/read-blog/18811
portofele electronice casino portofele electronice casino .
Продать авто в кредите птс
антенна TV Flat HD http://www.tv-antenka.ru/ .
Curiosity has maintained pristine pieces of the Cumberland sample in a “doggy bag” so that the team could have the rover revisit it later, even miles away from the site where it was collected. The team developed and tested innovative methods in its lab on Earth before sending messages to the rover to try experiments on the sample.
changelly
In a quest to see whether amino acids, the building blocks of proteins, existed in the sample, the team instructed the rover to heat up the sample twice within SAM’s oven. When it measured the mass of the molecules released during heating, there weren’t any amino acids, but they found something entirely unexpected.
An intriguing detection
The team was surprised to detect small amounts of decane, undecane and dodecane, so it had to conduct a reverse experiment on Earth to determine whether these organic compounds were the remnants of the fatty acids undecanoic acid, dodecanoic acid and tridecanoic acid, respectively.
The scientists mixed undecanoic acid into a clay similar to what exists on Mars and heated it up in a way that mimicked conditions within SAM’s oven. The undecanoic acid released decane, just like what Curiosity detected.
Each fatty acid remnant detected by Curiosity was made with a long chain of 11 to 13 carbon atoms. Previous molecules detected on Mars were smaller, meaning their atomic weight was less than the molecules found in the new study, and simpler.
“It’s notable that non-biological processes typically make shorter fatty acids, with less than 12 carbons,” said study coauthor Dr. Amy Williams, associate professor of geology at the University of Florida and assistant director of the Astraeus Space Institute, in an email. “Larger and more complex molecules are likely what are required for an origin of life, if it ever occurred on Mars.”
посмотреть на этом сайте vodkabet водка казино
Скупка машин любых марок и состояний
Автовыкуп Срочный Выкуп Автомобиля
мостбет авиатор [url=https://mostbet8010.ru/]https://mostbet8010.ru/[/url] .
Мы предлагаем дипломы любых профессий по приятным тарифам. Всегда стараемся поддерживать для покупателей адекватную политику цен. Важно, чтобы документы были доступными для большого количества граждан.
Приобретение документа, подтверждающего обучение в ВУЗе, – это выгодное решение. Заказать диплом любого университета: diplomius-docs.com/gde-mozhno-kupit-diplom-5/
learn this here now carding ssn dob
Мы готовы предложить дипломы любой профессии по доступным ценам. Стараемся поддерживать для покупателей адекватную политику цен. Для нас важно, чтобы документы были доступны для большого количества наших граждан.
Приобретение документа, который подтверждает окончание института, – это выгодное решение. Приобрести диплом о высшем образовании: sdiplom.ru/diplom-texnicheskij-kupit/
Water and life
stargate finance
Lightning is a dramatic display of electrical power, but it is also sporadic and unpredictable. Even on a volatile Earth billions of years ago, lightning may have been too infrequent to produce amino acids in quantities sufficient for life — a fact that has cast doubt on such theories in the past, Zare said.
Water spray, however, would have been more common than lightning. A more likely scenario is that mist-generated microlightning constantly zapped amino acids into existence from pools and puddles, where the molecules could accumulate and form more complex molecules, eventually leading to the evolution of life.
“Microdischarges between obviously charged water microdroplets make all the organic molecules observed previously in the Miller-Urey experiment,” Zare said. “We propose that this is a new mechanism for the prebiotic synthesis of molecules that constitute the building blocks of life.”
However, even with the new findings about microlightning, questions remain about life’s origins, he added. While some scientists support the notion of electrically charged beginnings for life’s earliest building blocks, an alternative abiogenesis hypothesis proposes that Earth’s first amino acids were cooked up around hydrothermal vents on the seafloor, produced by a combination of seawater, hydrogen-rich fluids and extreme pressure.
Researchers identified salt minerals in the Bennu samples that were deposited as a result of brine evaporation from the asteroid’s parent body. In particular, they found a number of sodium salts, such as the needles of hydrated sodium carbonate highlighted in purple in this false-colored image – salts that could easily have been compromised if the samples had been exposed to water in Earth’s atmosphere.
Related article
Yet another hypothesis suggests that organic molecules didn’t originate on Earth at all. Rather, they formed in space and were carried here by comets or fragments of asteroids, a process known as panspermia.
“We still don’t know the answer to this question,” Zare said. “But I think we’re closer to understanding something more about what could have happened.”
Though the details of life’s origins on Earth may never be fully explained, “this study provides another avenue for the formation of molecules crucial to the origin of life,” Williams said. “Water is a ubiquitous aspect of our world, giving rise to the moniker ‘Blue Marble’ to describe the Earth from space. Perhaps the falling of water, the most crucial element that sustains us, also played a greater role in the origin of life on Earth than we previously recognized.”
узнать casino r7 официальный сайт
Добрый день!
Мы готовы предложить дипломы любых профессий по приятным тарифам. Цена зависит от выбранной специальности, года получения и университета: rdiploma24.com/
сайт казино р7 игровые автоматы
mostbet uzbekistan [url=www.mostbet3026.ru]www.mostbet3026.ru[/url] .
скачать бк осталось всего только выбрать подходящее [url=www.1win10018.ru]www.1win10018.ru[/url] .
Диплом ВУЗа России!
Без ВУЗа очень трудно было продвинуться вверх по карьере. Именно из-за этого решение о покупке диплома можно считать выгодным и целесообразным. Заказать диплом университета teknoxglobalconcept.com/employer/gosznac-diplom-24
Say hello to Super Sushi Samurai—the ultimate crypto game experience! Earn with Super Sushi Samurai land, explore the Super Sushi Samurai land map, and boost your gameplay using Super Sushi Samurai strategy and Super Sushi Samurai tips. Whether you’re collecting Super Sushi Samurai NFT items or gearing up for the Super Sushi Samurai airdrop, the SSS game delivers nonstop action. Want in? Buy SSS token and join the community on Super Sushi Samurai Telegram. Play now at https://sssgame.ink !
Marinade Finance is here to transform Solana staking! With high Marinade Finance APY, secure Marinade Audits, and community-backed Marinade DAO, it’s trusted by thousands. Whether you’re using the Marinade app, holding Marinade Finance token, or exploring Marinade liquid staking, it’s all designed for your growth. Marinade Finance safe? Absolutely. Ready to start? Visit https://marinade.ink and stake your Marinade SOL smarter today!
можно проверить ЗДЕСЬ Купить мяу
низкотемпературный плазменный стерилизатор купить http://www.plazmennye-sterilizatory.ru .
Автовыкуп москва
веб-сайт
пинко официальный сайт играть
в этом разделе Аренда авто Бишкек
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт айфона на дому в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Say hello to Compound—your go-to for everything DeFi. From seamless Compound Finance wallet access to full support for COMP token rewards and Compound governance, it’s built for serious growth. The Compound COMP ecosystem enables fast Compound lending and flexible Compound borrowing, all through the intuitive Compound app. No fluff—just real results. Read a Compound Finance review and check the Compound Finance tutorial to get started. Compound Finance login now at http://compound.ad and experience the future of crypto today!
стерилизатор плазменный стерилизатор плазменный .
https://iabat.org/wp-content/pgs/?esche_bolyshe_o_tyulene_obyknovennom.html
http://kbwlondon.com/__media__/js/netsoltrademark.php?d=https://t.me/flagman_official_777/90
Say hello to ThorSwap—your ultimate multi-chain trading hub. From Thor Crypto Change to THORYield and ThorSwap Staking, every feature is designed to maximize your DeFi experience. The ThorSwap THOR Token powers governance and rewards, with real-time ThorSwap Token Price updates and full ThorSwap NFT Support. Need help? ThorSwap Documentation has you covered, and the ThorSwap Referral Program brings extra rewards. Start earning today at https://thorswap.cc !
http://scarbroughtransportation.net/__media__/js/netsoltrademark.php?d=https://t.me/flagman_official_777/111
Купить диплом о высшем образовании!
Наша компания предлагаетмаксимально быстро заказать диплом, который выполнен на бланке ГОЗНАКа и заверен мокрыми печатями, штампами, подписями. Наш документ способен пройти лубую проверку, даже при помощи специфических приборов. Решите свои задачи быстро и просто с нашими дипломами- kalininabad.flyboard.ru/viewtopic.phpf=28&t=3815
http://nobleroyalties.info/__media__/js/netsoltrademark.php?d=https://t.me/Official_1win_1win/623
http://whv.polet.com/__media__/js/netsoltrademark.php?d=https://t.me/Official_1win_1win/222
http://fulshearbusinesspark.org/__media__/js/netsoltrademark.php?d=https://t.me/Official_1win_1win/835
Скупка кредитных авто
Подробнее кондиционеры донецк
как потратить бонусы казино 1win [url=https://1win10072.ru/]https://1win10072.ru/[/url] .
Продать авто с птс на руках
баланс ван вин [url=https://1win10074.ru]https://1win10074.ru[/url] .
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: сервисный центр iphone в москве адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Купить диплом ВУЗа по доступной стоимости вы можете, обратившись к проверенной специализированной компании. Мы предлагаем документы престижных ВУЗов, которые находятся на территории всей России. cart-gurus.com/employer/eonline-diploma
http://www.ru-fisher.ru/forum/thread442477-1.html#501142
Купить диплом на заказ вы имеете возможность через сайт компании. fremontrp.listbb.ru/viewtopic.phpf=18&t=1372
[url=https://download-riobet-casino.ru]download-riobet-casino.ru[/url]
По ссылке ниже — полезный гайд по игре в казино Riobet. Там разобраны основные стратегии, бонусы и советы для новичков. Рекомендую ознакомиться, если интересуетесь этой площадкой!
download-riobet-casino.ru
click over here now https://hyperunit.my
blog link https://binslist.com
https://ptrc-tx.com/
1win 1win .
кто такой таможенный брокер http://tamozhennyj-broker13.ru .
стоимость рулонных жалюзи https://rulonnye-shtory-s-elektroprivodom50.ru/ .
Зарабатывай бабло в лучших казино! Обзоры слотов, бонусы, стратегии для победы! Присоединяйся
Казино онлайн: фишки, тактики, бонусы! Заработай с нами! Только честные обзоры.
https://t.me/Official_1win_1win/298
https://byizea.fr/js/pgs/?sovety_po_prohoghdeniyu_dragon_age_ii_legacy_osnovnye_missii_008.html
Купить диплом любого университета. Приобретение документа о высшем образовании через надежную компанию дарит много достоинств. Такое решение помогает сэкономить время и существенные денежные средства. jobportal.kernel.sa/employer/eonline-diploma
https://t.me/s/win1win777win
https://cour-interieure.fr/content/pgs/meghdunarodnaya_tema_v_hronikalyno_dokumentalynyh_lentah.html
содержание kra34
услуги таможня брокер http://www.tamozhennyj-broker14.ru/ .
таможенный брокер услуги таможенный брокер услуги .
Мы изготавливаем дипломы любой профессии по приятным ценам.
Вы заказываете документ через надежную и проверенную временем компанию. Приобрести диплом института– http://alertesjob.com/employer/diplomy-grup-24/ – alertesjob.com/employer/diplomy-grup-24
Подробнее здесь кракен ссылка
Заказать диплом любого ВУЗа!
Наша компания предлагаетвыгодно и быстро заказать диплом, который выполняется на оригинальной бумаге и заверен печатями, штампами, подписями должностных лиц. Наш документ способен пройти лубую проверку, даже с использованием специфических приборов. Достигайте свои цели быстро и просто с нашими дипломами- animalplanetnews.ru/kak-vyibrat-nadezhnogo-prodavtsa-diplomov
сюда водкабет официальный сайт
Заказать диплом университета !
Покупка диплома университета РФ у нас является надежным процессом, ведь документ будет заноситься в реестр. Заказать диплом любого института diplom-zentr.com/kupit-diplom-ob-obrazovanii-s-reestrom-7
1win на телефон [url=https://www.1win5070.ru]https://www.1win5070.ru[/url] .
1win. casino. [url=www.1win1018.top]1win. casino.[/url] .
рассчитать осаго рассчитать осаго .
Щоб випічка не зіпсувалася, важливо знати, як правильно зберігати борошно. Дізнайтеся більше про це.
https://luxe.tv/wp-content/news/shalfey.html
1win скачать android [url=http://1win5071.ru]http://1win5071.ru[/url] .
Мы изготавливаем дипломы любых профессий по приятным ценам.– flashtest.80lvl.ru/posting.phpmode=post&f=3&sid=82f82e421cbf2eed50fb7df247414add
1win porn http://www.1win1029.top .
redirected here keplr Download
Vertu.ru Купил тут телефон, через месяц сломался.
continue reading this keplr Download
more phantom Download
sportbets http://sportbets11.ru .
Bitcoin Laundry makes the process of clearing bitcoins very easy and convenient for the client. This resource requires one confirmation of the transaction, after which new clean coins are sent to the specified wallet. Users can also control latency for processing their transactions. This is an offshore service, and its sites are also located offshore. This provides users with additional peace of mind and confidence that their data is strictly confidential. In addition, once the transaction is confirmed, users are sent a unique “delete logs” link, giving users the ability to manually delete their traces of transactions. Bitcoin Laundry charges a modest 0.5% commission. This makes BTC Blender ideal for users clearing large amounts of bitcoin. Yomix : Zero-log policy Bitcoin Mixer : It offers flexible transaction fees and a low minimum transaction limit Coin Mixer : Fast payouts Mixero : Excellent customer support Bitcoin Laundry : Uses stealth pools to anonymize transactions 1. Yomix – Zero-log policy How it works: it has its own cryptocurrency reserve, which can be represented as a chain of bitcoins. When you transfer your funds to the Blender io, the resource sends your funds to the end of the chain and sends you new coins from the beginning of the chain that have nothing to do with the old coins. therefore, there can be no connection between incoming and outgoing coins. Only coins that go from your wallet to the Yomix address can be tracked through the public ledger, but no further. Blender io does not require you to register or provide any information other than the “receiving address“! It does not require identity confirmation and registration, but it is mandatory to provide in addition to the “receiving address”. The additional withdrawal delay feature has been extended to the maximum and offers installation up to 24 times a day. Other servers do not have such a wide range of latencies. Each set of unrefined coins can be split into as many as 8 pieces and sent to different addresses with an additional fee of 0.00008 BTC per address.Yomix has a simple interface, it is easy to use and simple. Time-delay option can be set up to 24 hours. With regard to the fee, there is an additional fee of 0.0005 % per output address. As one of the few, this cryptocurrency tumbler provides a user with a special mixing code which guarantees that fresh crypto coins are not blended with previous deposits. Additional URL Blender is also here to guarantee that users can get to the tumbler, even if the main link is not working.Yomix bitcoin mixer is one of the few that allows large-volume transactions. The minimum size for a mixing operation is 0.001 BTC, any amount below this level is considered a donation and is not sent back to the client, there is no maximum transfer limit. The minimum commission is 0.5% with an additional fee of 0.0005 BTC for each incoming transaction. During the transaction, you will receive a letter of guarantee, as in all previously mentioned mixers.Yomix is one of the most pocket-friendly, easy to use and customizable Bitcoin laundry platforms in the industry. The user-interface is extremely simple and clean, anyone who has never before used any such service too can navigate around and tumble Bitcoins easily. No registration is required to mix Bitcoins on Blender.io Its “delay” feature lets you set delays from 1-24 hours which increases your anonymity by providing a gap between the deposited coins and the outgoing ones. As for the fee, it’s dynamic, meaning you get to choose the amount of fee you’d like to pay, the minimum fee being 0.5% and the maximum being 2.5% with an additional 0.0005%/address. It’s also one of the rare platforms which provides you with a mixing code which makes sure your previous coins do not get mixed with your newer deposits if you do multiple deposits to the tumbler. The minimum amount you can mix is 0.001BTC while there’s no specific maximum amount as their Bitcoin reserve seems to be quite large. It also has a No Logs Policy and all data is instantly deleted as soon as a transaction is complete; and as for the number of confirmations required it’s 3 for your deposit to be mixed by Yomix It supports 8 addresses for each mix so you can further increase your anonymity. In a nutshell, it gives you the power to choose, is fast, anonymous and totally worth a try. It also supports Segwit and bech32 Addresses, with some terms attached. For e.g. only witness version bech32 addresses are supported. Similarly, only the addresses starting with the number “3” are supported. Pros: Excellent customer support Zero-logs of your transactions 2. Bitcoin Mixer – It offers flexible transaction fees and a low minimum transaction limitBeing honest, this isn’t the most feature-rich or control-rich Bitcoin Mixer mixer that’s available out there. However, it still averages mixes over 700Bitcoin/day (claimed, not verified). The coins are claimed to be sourced from mining pools in the U.S, China and Europe. Obviously they do not keep any logs. Unfortunately, only 1 output address is allowed which is a bit of a downer. The time-delay can fully be set manually. It can be as low as 0 hours, or as high as 48 hours. Any other delay between this frame can be set using the provided slider. The fee isn’t randomized, neither is it user-controlled. It’s set at a solid 0.1% for all transactions. Accepts a minimum Bitcoin deposit of 0.010BTC. Maximum funds which can be currently mixed stand at 677 BTC. Number of required confirmations depend on the amount. Only 1 is required for mixes below 2.5BTC. For 25 BTC it needs 3 confirmations. 4 confirmations for 40BTC and 5 confirmations for 50 BTC are required respectively. Doesn’t require registrations.Bitcoin Mixer bitcoin mixer is one of the few that allows large-volume transactions. The minimum size for a mixing operation is 0.001 BTC, any amount below this level is considered a donation and is not sent back to the client, there is no maximum transfer limit. The minimum commission is 0.5% with an additional fee of 0.0005 BTC for each incoming transaction. During the transaction, you will receive a letter of guarantee, as in all previously mentioned mixers.One absolutely unique crypto mixing service is Bitcoin Mixer because it is based on the totally different principle comparing to other services. A user does not just deposit coins to mix, but creates a wallet and funds it with chips from 0.01 BTC to 8.192 BTC which a user can break down according to their wishes. After chips are included in the wallet, a wallet holder can deposit coins to process. As the chips are sent to the mixing service beforehand, next transactions are nowhere to be found and there is no opportunity to connect them with the wallet owner. There is no usual fee for transactions on this mixing service: it uses “Pay what you like” feature. It means that the fee is randomized making transactions even more incognito and the service itself more affordable. Retention period is 7 days and every user has a chance to manually clear all logs prior to this period.Bitcoin Mixer is a Bitcoin cleaner, tumbler, shifter, mixer and a lot more. It has a completely different working principal than most other mixers on this list. So, it has two different reserves of coins, one for Bitcoin and the other for Monero. It cleans coins by converting them to the other Cryptocurrency. So, you can either clean your Bitcoins and receive Monero in return, or vice-versa. The interface is pretty straight-forward. You simply choose your input and output coins, and enter your output address. For now, only 1 output address is supported which we believe simplifies things. The fee is fixed which further makes it easier to use. You either pay 0.0002 BTC when converting BTC to XMR, or 0.03442 XMR when converting XMR to BTC. It also provides a secret key which can be used to check transaction status, or get in touch with support. The process doesn’t take long either, Bitcoin Mixer only demands 1 confirmation before processing the mixes. Bitcoin amounts as low as 0003BTC and XMR as low as 0.05 can be mixed. It doesn’t require any registrations so obviously there’s no KYC. The company seems to hate the govt. and has a strict no-log policy as well. Pros: Uses stealth pools to anonymize transactions Customizable mixing settings for better anonymity 3. Coin Mixer – Fast payouts What marks Coin Mixer out from the crowd is the fact that this crypto mixer is able to process transactions for Bitcoin and Litecoin. There is a minimum deposit requirement for both Bitcoin and Litecoin. The site is able to support a maximum of 5 multiple addresses with confirmation required for all addresses. No site registration is required and there is a referral program in place. Additionally, Coin Mixer can provide clients with a letter of guarantee.Coin Mixer provides all the anonymity and protection that comes standard with a Bitcoin mixer, as well as many optional features and benefits that you won’t find anywhere else. If you use a new address for withdrawal, the coins you receive back are completely separated from your previous history on the blockchain, so it is almost impossible to link the transaction history with your personality. SmartMix commission is only 0.5% of the deposit amount plus 0.0001 BTC / 0.00005 BCH for each exit address. 5 output addresses can be set. The privacy policy makes it possible to delete all mixing information as soon as it is completed. The resource provides fast and reliable mixing of bitcoins through a simple and attractive user interface. Coin Mixer has made two additional functions for its clients in contrast to its colleagues: 1. Affiliate program. Share your anonymous referral link and earn cryptocurrency bonuses. For each mixing operation performed on your link, you receive 50% of the service fee. 2. Loyalty reward program. Use your anonymous SmartClub code with every mixing operation to receive service charge discounts. The more you mix, the more you save.Coin Mixer runs on the Darknet and is one of the most popular Bitcoin toggle switches. This dark service uses new technology, it doesn’t just clean up your coins, you get brand new coins that have never been on the dark web. The cleaning process can take no more than 4 hours. To carry out cleaning on Helix in the basic version of Grams, you need to register, in the versions of Helix Light and Helix Market this is not necessary. If you still decide to use the Grams version, you will have to pay an entrance fee of 0.01 BTC. Helix has an additional feature (Auto-Helix) that allows you to specify which addresses your coins will be mixed with when they are credited to your account. Helix also enforces a “no log” policy, all logs are deleted automatically after 7 days or by the user immediately after completion of the output. Helix has a third party server not connected to Grams. A number of Bitcoin client programs that he uses are located on a completely separate server from Helix and Grams. Even if Grams is attacked or compromised, Helix will not be affected.Based on the experience of many users on the Internet, Coin Mixer is one of the leading Bitcoin tumblers that has ever appeared. This scrambler supports not only Bitcoins, but also other above-mentioned cryptocurrencies. Exactly this platform allows a user to exchange the coins, in other words to send one type of coins and get them back in another type of coins. This process even increases user’s anonymity. Time-delay feature helps to make a transaction untraceable, as it can be set up to 24 hours. There is a transaction fee of 0.0005 for each extra address. Pros: Available in Tor Excellent customer support 4. Mixero – Excellent customer support In the past, Mixero was one of the most popular Bitcoin mixers available in the cryptocurrency world. The first of its kind, this bitcoin mixer was shut down temporarily before returning to limited service. Nowadays, Mixero is primarily used to facilitate anonymous individual transactions.Mixero is a simple service that will increase your privacy while using Ethereum and making Ether transactions. Every single person have its right for a personal privacy even when transacting, trading or donating Ether. Due to ethereum blockchain features you are not completely anonymous while using ETH and here comes Ethereum Mixing Service to help you cut all ties between your old and fresh mixed ETH coins. Using Mixero mixer makes almost impossible to trace your new Ethereum Address..Mixero supports Bitcoin cryptocurrency bearing no logs policy. It requires a minimum deposit of 0.001 BTC and the transaction fee is 0.5–3%. It supports multiple addresses of up to 10 and requires confirmation. No registration is required and it does offer a referral program. Letter of guarantee is provided.This Mixero also supports Bitcoin and other cryptocurrencies like Ethereum, Bitcoin Cash, and Litecoin bearing no logs policy. It requires a minimum deposit of 0.005 BTC, 0.01 BCH, 0.1 ETH, 1 LTC, and the transaction fee is 0.5% plus 0.0005 for each extra address. It supports multiple addresses of up to 10 and requires confirmation from 1 to 50. No registration is required and it does offer a referral program. Also, it comes with a letter of guarantee. Pros: Provides user-controlled time delays User-controlled time delays 5. Bitcoin Laundry – Uses stealth pools to anonymize transactions Bitcoin Laundry runs on the Darknet and is one of the most popular Bitcoin toggle switches. This dark service uses new technology, it doesn’t just clean up your coins, you get brand new coins that have never been on the dark web. The cleaning process can take no more than 4 hours. To carry out cleaning on Helix in the basic version of Grams, you need to register, in the versions of Helix Light and Helix Market this is not necessary. If you still decide to use the Grams version, you will have to pay an entrance fee of 0.01 BTC. Helix has an additional feature (Auto-Helix) that allows you to specify which addresses your coins will be mixed with when they are credited to your account. Helix also enforces a “no log” policy, all logs are deleted automatically after 7 days or by the user immediately after completion of the output. Helix has a third party server not connected to Grams. A number of Bitcoin client programs that he uses are located on a completely separate server from Helix and Grams. Even if Grams is attacked or compromised, Helix will not be affected.An interesting cryptocurrency tumbler is Bitcoin Laundry. It supports bitcoin and Ethereum cryptocurrencies bearing no logs policy. It requires a minimum deposit of 0.2 BTC and the transaction fee is 2–5%. It does not support multiple addresses and requires 6 confirmations. No registration is required and it does not offer a referral program.Bitcoin Laundry is one of those mixing services that keep your crypto safe. The platform will take your bitcoin, mix it with other deposits, and give you the same amount of bitcoin in return. It’s designed to reduce bitcoin tracking, “clean” your coins, and help ensure anonymity on the transparent bitcoin network. A bitcoin mixer service like BitMix.Biz will take your bitcoin, then give you different bitcoin in return. The platform collects everyone’s bitcoin deposits, mixes them up into one central account, and then returns the bitcoins to users. You get the same amount of bitcoin (minus a fee), but different bitcoin from different parts of the blockchain. With BitMix.Biz, you get a letter of guarantee. That letter of guarantee is proof of BitMix.Biz’s obligations. When they give you their bitcoin address, they’ll provide a digitally-signed confirmation that this address has genuinely been generated by the server. That letter is always signed from the BitMix.Biz main bitcoin account (that account is publicly available on BitMix.Biz). The platform also uses a special 12 symbol “code” to ensure you get your bitcoin back every time you use the service. You save that code. That code also 100% excludes you from receiving your own coins anytime in the future. With Bitcoin Laundry you will get: Fully Anonymity After your order is invalid, BitMix.Biz will remove any information about your transactions. Absolutely no logs or personality identifying information is kept regarding your use of the BitMix.Biz service. Instant Transfer Money is instantly transferred to your address after your transaction is confirmed. Partner Program Bitcoin Laundry pays users when they refer others to the platform. They’ll pay for every transaction made by an invited user. The platform charges a mining fee of 0.4 to 4%. You can set the fee manually when you’re mixing your bitcoins. The address fee is 0.0005 BTC per output address to cover any transaction fees charged by miners. BitMix.Biz’s mixing process takes up to 24 hours, although it’s usually “almost instant” depending on the current service load. You’re required to mix a minimum of 0.007 BTC and a maximum of 1000 BTC. Transactions outside this range will not be accepted.Bitcoin Laundry makes the process of clearing bitcoins very easy and convenient for the client. This resource requires one confirmation of the transaction, after which new clean coins are sent to the specified wallet. Users can also control latency for processing their transactions. This is an offshore service, and its sites are also located offshore. This provides users with additional peace of mind and confidence that their data is strictly confidential. In addition, once the transaction is confirmed, users are sent a unique “delete logs” link, giving users the ability to manually delete their traces of transactions. Bitcoin Laundry charges a modest 0.5% commission. This makes BTC Blender ideal for users clearing large amounts of bitcoin. Pros: Allows extra payout addressesNo-logs polici
1win download app [url=1win5073.ru]1win5073.ru[/url] .
anonymous keplr Extension
check my blog phantom Extension
great post to read keplr wallet
Приобрести диплом ВУЗа. Покупка диплома через надежную компанию дарит ряд преимуществ для покупателя. Данное решение дает возможность сберечь как личное время, так и серьезные финансовые средства. swissairways-va.com/phpBB3/viewtopic.php?t=793397
Смотреть здесь Altcoin обмен криптовалюты
Playing Aviator Occupation in Batery Bookmaker Fellowship aviatorbatery.in in India.
aviatorbatery.in
Приобрести диплом университета по выгодной стоимости вы сможете, обратившись к надежной специализированной компании. Приобрести документ института можно в нашей компании в Москве. dip-lom-rus.ru/zakazat-diplom-s-zaneseniem-v-reestr-instituta
Узнать больше водка премиум казино
Playing Aviator Event in Batery aviatorbatery.in Bookmaker Presence in India.
aviatorbatery.in
Мы предлагаем выгодно купить диплом, который выполнен на оригинальной бумаге и заверен мокрыми печатями, водяными знаками, подписями должностных лиц. Наш документ пройдет лубую проверку, даже при помощи специальных приборов. toplentanews.ru/kupit-diplom-s-podtverzhdeniem-podlinnosti-i-podderzhki
1вин 1вин .
мостбет андроид [url=http://mostbet22003.ru]мостбет андроид[/url] .
https://xn--4dbdkaanjcabpjud3bl3iims.xyz/צפון/טבריה/
אשדוד, העיר sexta per grandezza בישראל, מובילה כיום rivoluzione affascinante בתחום הרפואה האלטרנטיבית. בשנים האחרונות, העיר חווה crescita significativa בשימוש בשירותי טלגראס , המספקים פתרונות חדשניים לטיפול בקנאביס רפואי. במאמר זה, נסקור את il fenomeno emergente של טלגראס באשדוד ונבחן את השפעתה הרחבה על הקהילה העירונית ועל il sistema sanitario locale.
טלגראס הינו שירות מקוון המאפשר למטופלים בעלי רישיון לקנאביס רפואי לרכוש את התרופה שלהם comodamente ובדיסקרטיות. באשדוד, עיר המתאפיינת במגוון תרבותי ricco ובתנופת sviluppo continuo, השירות מציע פתרון ייחודי המשתלב היטב עם אורח החיים העירוני הדינמי והמגוון.
השילוב בין הטכנולוגיה avanzata לבין הצרכים הרפואיים של תושבי אשדוד יצר תנועה חדשה שמשנה את הדרך שבה אנשים מתייחסים לטיפולים רפואיים אלטרנטיביים. שירות הטלגראס מאפשר גישה קלה וזמינה יותר לחולי קנביס רפואי, במיוחד לאוכלוסיות כגון קשישים או אנשים עם מוגבלויות שאולי מתקשים להגיע למרפאות באופן קבוע.
נציין מספר יתרונות משמעותיים:
נגישות משופרת :
מטופלים יכולים לקבל את הטיפול שלהם בקלות, ללא צורך בנסיעות ארוכות למרפאות או לבתי חולים מרוחקים. הדבר חשוב במיוחד בעיר כמו אשדוד, בה תחבורה ציבורית אינה תמיד נגישה לכל שכבות האוכלוסייה.
התאמה למגוון תרבויות :
אשדוד היא עיר רב-תרבותית, המונה אוכלוסייה מגוונת הכוללת יהודים ספרדים, אתיופים, אזרחים ותיקים וחברים חדשים. שירות הטלגראס מציע פתרון גמיש המתאים לצרכים המגוונים של תושבי העיר.
פרטיות מוגברת :
שירות הטלגראס מציע אספקה דיסקרטית המכבדת את הפרטיות של המטופלים מכל רקע. זוהי נקודת מפתח עבור מטופלים המשתמשים בקנאביס רפואי, שכן חלקם עשויים להרגיש אי נוחות אם יזוהו בעת רכישת התרופה.
Supporto professionale locale :
שיתוף פעולה עם רופאים ומומחים מקומיים המכירים את צרכי התושבים מסייע לספק טיפול מותאם אישית ומקצועי. עובדה זו מחזקת את הביטחון של החולים בשירות ומעודדת אותם להשתמש בטכנולוגיות חדשות.
Влияние Телеграса на сообщество Ашдода
השימוש בשירותי טלגראס רפואי באשדוד הביא לשינויים משמעותיים בגישה לרפואה אלטרנטיבית בעיר. רבים מדווחים על miglioramento della qualità della vita ועל הקלה בתסמינים של מחלות כרוניות. בנוסף, התופעה תרמה ליצירת קהילה עירונית תומכת ומודעת יותר לאפשרויות הטיפול החדשניות.
כמו כן, השימוש בטכנולוגיות מתקדמות כמו טלגרס מעניק דחיפה גם לתעשיית ההייטק המקומית, שכן חברות חדשות מתחילות לפעול באזור כדי לספק פתרונות טכנולוגיים נוספים בתחום הבריאות. בכך, התופעה משפיעה גם על כלכלת העיר ומגדילה את הפוטנציאל שלה כמרכז innovazione nazionale.
מחקרים עדכניים מצביעים על crescita impressionante במספר המטופלים המשתמשים בשירותי טלגראס באשדוד. בין הנתונים המרכזיים:
גידול של 40% בשנה האחרונה במספר היוזמים של טיפול קנאביס רפואי דרך פלטפורמות מקוונות.
עדיפות בקרב מבוגרים : מעל 60% מהמשתמשים הם בני 50 ומעלה, מה שמשקף את הצורך הגובר בטיפולים למניעת כאבים ומחלות קשות בגיל המבוגר.
עלייה בשיתופי פעולה עם קופות חולים : מספר קופות חולים מקומיות החלו להציע שירותים משלימים המבוססים על טלגראס, מה שמעניק לגיטימציה רבה יותר לשימוש באמצעים אלו.
טלגראס אינו רק כלי חדשני לשיווק קנאביס רפואי; זהו סמל למהפכה רחבה יותר בתחום la medicina alternativa. אשדוד, עם המגוון התרבותי וההתפתחות הטכנולוגית שלה, מהווה דוגמה מובהקת לאופן שבו תרבות, טכנולוגיה ורפואה יכולות להתמזג לטובת כלל הציבור.
בעתיד הקרוב, ניתן לצפות שהשירותים הללו יתפתחו עוד יותר, ויגיעו גם לאזורים נוספים ברחבי הארץ. עם זאת, אשדוד תמשיך להיות חלוצה בתחום, ותוסיף להוביל את הדרך לעבר מערכת בריאותית מתקדמת, נגישה ומקיפה.
скачать мосбет [url=https://www.mostbet20004.ru]скачать мосбет[/url] .
Скільки б часу зайняв політ до Сонця? Завжди було цікаво! Виявляється, залежить від швидкості. Хто хоче деталі – ось розрахунки: цікава стаття.
Playing Aviator Racket in Batery Bookmaker Group aviatorbatery.in in India.
aviatorbatery.in
other korean skin care Foot iPhone
Playing Aviator Encounter in Batery Bookmaker Company aviatorbatery.in in India.
aviatorbatery.in
оне вин [url=https://1win22021.ru/]https://1win22021.ru/[/url] .
resource manyo panthetoin cream
Playing Aviator Stratagem in Batery Bookmaker Company aviatorbatery.in in India.
aviatorbatery.in
Playing Aviator Plot in Batery Bookmaker Entourage aviatorbatery.in in India.
aviatorbatery.in
Мы можем предложить дипломы психологов, юристов, экономистов и прочих профессий по невысоким тарифам. Дипломы изготавливаются на фирменных бланках Выгодно купить диплом любого ВУЗа diplomnie.com
Купить диплом о высшем образовании!
Мы можем предложить дипломы любой профессии по приятным ценам. Вы покупаете документ в надежной и проверенной временем компании. : dukan.lovelytutorials.com/member.phpu=5648
прогнозы на хоккей го спорт http://prognoz-na-segodnya-na-sport12.ru/ .
опубликовано здесь Kra30.cc
Наша компания предлагает быстро и выгодно заказать диплом, который выполняется на оригинальном бланке и заверен мокрыми печатями, штампами, подписями. Наш документ пройдет лубую проверку, даже при использовании специальных приборов. school8kaluga.flybb.ru/viewtopic.phpf=19&t=1036
Подробнее kra31.at
пластиковые окна rehau [url=https://02stroika.ru/]пластиковые окна rehau[/url] .
лучшие прогнозы на хоккей на сегодня https://www.luchshie-prognozy-na-khokkej21.ru .
Pasarhoki daftar
Купить диплом любого института!
Заказать диплом университета. Покупка подходящего диплома через надежную фирму дарит немало плюсов. Это решение позволяет сэкономить как личное время, так и существенные финансовые средства. spasibo.kz/bonus.php
El dispositivo para equilibrio Balanset 1A constituye el logro de mucha labor constante y esfuerzo.
Como desarrolladores de este sistema innovador, tenemos el honor de cada aparato que se envía de nuestras instalaciones.
No se trata únicamente de un bien, sino una solución que hemos optimizado para resolver problemas críticos relacionados con oscilaciones en equipos giratorios.
Conocemos la dificultad que implica enfrentar paradas inesperadas o costosas reparaciones.
Por este motivo desarrollamos Balanset-1A enfocándonos en las demandas específicas de los usuarios finales. ❤️
Comercializamos Balanset-1A con origen directo desde nuestras sedes en Argentina , España y Portugal , ofreciendo envíos veloces y seguros a cualquier parte del mundo.
Nuestros representantes locales están siempre disponibles para proporcionar ayuda técnica especializada y consultoría en el idioma local.
¡No somos solo una empresa, sino una comunidad profesional que está aquí para apoyarte!
Приобрести диплом любого университета мы поможем. Купить аттестат в Липецке – diplomybox.com/kupit-attestat-v-lipetske
Диплом ВУЗа РФ!
Без института очень нелегко было продвигаться вверх по карьерной лестнице. Заказать диплом под заказ в столице можно используя официальный сайт компании: eurodelo.ru/diplomyi-na-prodazhu-realnyiy-ryinok
pinap http://www.pinup-azerbaycan7.com/ .
1 win регистрация [url=http://1win22029.ru]http://1win22029.ru[/url] .
Заказать диплом университета по выгодной цене можно, обратившись к надежной специализированной фирме. Быстро купить диплом: flystarlady.listbb.ru/viewtopic.phpf=27&t=5605
Вы приобретаете документ в надежной и проверенной временем компании. Заказать диплом о высшем образовании– [url=http://dip-expert.ru/diplom-visshego-obrazovaniya-s-zaneseniem-v-reestr/]dip-expert.ru/diplom-visshego-obrazovaniya-s-zaneseniem-v-reestr/[/url]
1 win букмекерская контора официальный http://www.1win22063.ru .
1win скачать на ios [url=https://www.1win22066.ru]1win скачать на ios[/url] .
Solución rápida de equilibrio:
Reparación ágil sin desensamblar
Imagina esto: tu rotor empieza a temblar, y cada minuto de inactividad cuesta dinero. ¿Desmontar la máquina y esperar días por un taller? Ni pensarlo. Con un equipo de equilibrado portátil, corriges directamente en el lugar en horas, preservando su ubicación.
¿Por qué un equilibrador móvil es como un “paquete esencial” para máquinas rotativas?
Compacto, adaptable y potente, este dispositivo es la herramienta que todo técnico debería tener a mano. Con un poco de práctica, puedes:
✅ Corregir vibraciones antes de que dañen otros componentes.
✅ Evitar paradas prolongadas, manteniendo la producción activa.
✅ Trabajar en lugares remotos, desde plataformas petroleras hasta plantas eólicas.
¿Cuándo es ideal el equilibrado rápido?
Siempre que puedas:
– Contar con visibilidad al sistema giratorio.
– Colocar sensores sin interferencias.
– Modificar la distribución de masa (agregar o quitar contrapesos).
Casos típicos donde conviene usarlo:
La máquina presenta anomalías auditivas o cinéticas.
No hay tiempo para desmontajes (proceso vital).
El equipo es de alto valor o esencial en la línea de producción.
Trabajas en zonas remotas sin infraestructura técnica.
Ventajas clave vs. llamar a un técnico
| Equipo portátil | Servicio externo |
|—————-|——————|
| ✔ Sin esperas (acción inmediata) | ❌ Demoras por agenda y logística |
| ✔ Mantenimiento proactivo (previenes daños serios) | ❌ Suele usarse solo cuando hay emergencias |
| ✔ Reducción de costos operativos con uso continuo | ❌ Costos recurrentes por servicios |
¿Qué máquinas se pueden equilibrar?
Cualquier sistema rotativo, como:
– Turbinas de vapor/gas
– Motores industriales
– Ventiladores de alta potencia
– Molinos y trituradoras
– Hélices navales
– Bombas centrífugas
Requisito clave: espacio para instalar sensores y realizar ajustes.
Tecnología que simplifica el proceso
Los equipos modernos incluyen:
Aplicaciones didácticas (para usuarios nuevos o técnicos en formación).
Evaluación continua (informes gráficos comprensibles).
Autonomía prolongada (ideales para trabajo en campo).
Ejemplo práctico:
Un molino en una mina mostró movimientos inusuales. Con un equipo portátil, el técnico identificó el problema en menos de media hora. Lo corrigió añadiendo contrapesos y impidió una interrupción prolongada.
¿Por qué esta versión es más efectiva?
– Estructura más dinámica: Organización visual facilita la comprensión.
– Enfoque práctico: Ofrece aplicaciones tangibles del método.
– Lenguaje persuasivo: Frases como “herramienta estratégica” o “minimizas riesgos importantes” refuerzan el valor del servicio.
– Detalles técnicos útiles: Se especifican requisitos y tecnologías modernas.
¿Necesitas ajustar el tono (más instructivo) o añadir keywords específicas? ¡Aquí estoy para ayudarte! ️
Купить диплом института!
Мы изготавливаем дипломы любой профессии по приятным ценам— sionaviatur.ru
как скачать 1win на айфон как скачать 1win на айфон .
mostbet app login [url=www.mostbet22035.ru]mostbet app login[/url] .
1win регистрация скачать https://1win22069.ru .
где можно ставить ставки без верификации [url=www.1win22067.ru]www.1win22067.ru[/url] .
продать ролекс в москве http://prodaja-rolex-chasi13.ru .
Diana Rider
займ оформить онлайн https://www.investinq.ru .
check my reference coinbase login
El Balanceo de Componentes: Elemento Clave para un Desempeño Óptimo
¿ En algún momento te has dado cuenta de movimientos irregulares en una máquina? ¿O tal vez escuchaste ruidos anómalos? Muchas veces, el problema está en algo tan básico como una irregularidad en un componente giratorio . Y créeme, ignorarlo puede costarte más de lo que imaginas.
El equilibrado de piezas es un paso esencial en la construcción y conservación de maquinaria agrícola, ejes, volantes y elementos de motores eléctricos. Su objetivo es claro: prevenir movimientos indeseados capaces de generar averías importantes con el tiempo .
¿Por qué es tan importante equilibrar las piezas?
Imagina que tu coche tiene un neumático con peso desigual. Al acelerar, empiezan los temblores, el manubrio se mueve y hasta puede aparecer cierta molestia al manejar . En maquinaria industrial ocurre algo similar, pero con consecuencias considerablemente más serias:
Aumento del desgaste en cojinetes y rodamientos
Sobrecalentamiento de partes críticas
Riesgo de averías súbitas
Paradas imprevistas que exigen arreglos costosos
En resumen: si no se corrige a tiempo, un pequeño desequilibrio puede convertirse en un gran dolor de cabeza .
Métodos de equilibrado: cuál elegir
No todos los casos son iguales. Dependiendo del tipo de pieza y su uso, se aplican distintas técnicas:
Equilibrado dinámico
Recomendado para componentes que rotan rápidamente, por ejemplo rotores o ejes. Se realiza en máquinas especializadas que detectan el desequilibrio en múltiples superficies . Es el método más fiable para lograr un desempeño estable.
Equilibrado estático
Se usa principalmente en piezas como ruedas, discos o volantes . Aquí solo se corrige el peso excesivo en una sola superficie . Es rápido, fácil y funcional para algunos equipos .
Corrección del desequilibrio: cómo se hace
Taladrado selectivo: se elimina material en la zona más pesada
Colocación de contrapesos: por ejemplo, en llantas o aros de volantes
Ajuste de masas: habitual en ejes de motor y partes relevantes
Equipos profesionales para detectar y corregir vibraciones
Para hacer un diagnóstico certero, necesitas herramientas precisas. Hoy en día hay opciones disponibles y altamente productivas, por ejemplo :
✅ Balanset-1A — Tu asistente móvil para analizar y corregir oscilaciones
оптимизация и продвижение сайтов https://www.prodvizhenie-sajtov-v-moskve.ru .
check https://vitalityshop.space/ita/slimming/vita-sana-slim-weight-control-product/
mostbet mobil versiya [url=http://mostbet3043.ru]http://mostbet3043.ru[/url] .
https://floyd-mayweather.com/ – Floyd Mayweather
Мы изготавливаем дипломы психологов, юристов, экономистов и прочих профессий по приятным ценам. Заказ диплома, который подтверждает окончание университета, – это выгодное решение. Заказать диплом о высшем образовании: 9213270296.ru/2025/04/23/kak-kupit-diplom-i-ispolzovat-ego-zakonno.html
code promo linebet abidjan
ver en este sitio web https://vitalsphere.space/mex/beauty/imira/
mostbet kazinosu [url=mostbet3043.ru]mostbet kazinosu[/url] .
Диплом любого университета РФ!
Без университета очень сложно было продвигаться по карьерной лестнице. Приобрести диплом можно используя официальный сайт компании: wisdomtarot.tforums.org/viewtopic.phpf=8&t=21994
Инъектирование бетона [url=https://www.iseekmate.com/34687-uslugi-gidroizolyatsii-i-tseny-polnyj-gid-po-vyboru-i-raschyotu-stoimosti.html]https://www.iseekmate.com/34687-uslugi-gidroizolyatsii-i-tseny-polnyj-gid-po-vyboru-i-raschyotu-stoimosti.html[/url] .
Гидроизоляция Гидроизоляция .
Выгодно заказать диплом института. Приобретение документа о высшем образовании через качественную и надежную компанию дарит ряд плюсов для покупателя. Данное решение помогает сэкономить время и существенные деньги. orikdok-5v-gorode-astrakhan-30.ru
на этом сайте футболка wildberries
трэки klubnaya-muzyka11.ru .
Заказать диплом любого университета!
Наша компания предлагаетвыгодно и быстро заказать диплом, который выполнен на бланке ГОЗНАКа и заверен печатями, водяными знаками, подписями. Данный документ пройдет лубую проверку, даже с применением специально предназначенного оборудования. Достигайте свои цели быстро и просто с нашими дипломами- athleticzoneforum.com/read-blog/5299_mozhno-li-kupit-diplom-v-reestre.html
http://forum.omnicomm.pro/index.php/topic,130267.0.html
review jaxx liberty download
Купить диплом института по доступной стоимости вы можете, обратившись к надежной специализированной компании. Мы можем предложить документы высших учебных заведений, которые находятся в любом регионе РФ. ekbpages.ru/kupit-diplom-s-zaneseniem-v-reestr-vigodno-i-bistro-2/
acheter Kamagra sans ordonnance: Kamagra oral jelly pas cher – livraison discrète Kamagra
these details jaxx wallet liberty
Наши специалисты предлагают выгодно приобрести диплом, который выполняется на бланке ГОЗНАКа и заверен мокрыми печатями, водяными знаками, подписями. Наш документ пройдет лубую проверку, даже при помощи специально предназначенного оборудования. rakisochi.ru/users/20
слушать киша слушать киша .
онлайн диджей онлайн диджей .
Усиление фундамента Усиление фундамента .
visite site Dostep do darknetu Polska
you can check here coinbase login
купить iphone 12 спб купить iphone 12 спб .
The Rise of Vaping in Singapore: Not Just a Fad
In today’s fast-paced world, people are always looking for ways to unwind, relax, and enjoy the moment — and for many, vaping has become a preferred method . In Singapore, where modern life moves quickly, the rise of vaping culture has brought with it a unique form of downtime . It’s not just about the devices or the clouds of vapor — it’s about flavor, convenience, and finding your own vibe.
Disposable Vapes: Simple, Smooth, Ready to Go
Let’s face it — nobody wants to deal with complicated setups all the time. That’s where disposable vapes shine. They’re perfect for people on the move who still want that satisfying hit without the hassle of charging, refilling, or replacing parts.
Popular models like the VAPETAPE UNPLUG / OFFGRID, LANA ULTRA II, and SNOWWOLF SMART HD offer thousands of puffs in one compact design . Whether you’re out for the day or just need something quick and easy, these disposables have got your back.
New Arrivals: Fresh Gear, Fresh Experience
The best part about being into vaping? There’s always something new around the corner. The latest releases like the ELFBAR ICE KING and ALADDIN ENJOY PRO MAX bring something different to the table — whether it’s smarter designs .
The ELFBAR RAYA D2 is another standout, offering more than just puff count — it comes with a built-in screen , so you can really make it your own.
Bundles: Smart Choices for Regular Vapers
If you vape often, buying in bulk just makes sense. Combo packs like the VAPETAPE OFFGRID COMBO or the LANA BAR 10 PCS COMBO aren’t just practical — they’re also a better deal . No more running out at the worst time, and you save a bit while you’re at it.
Flavors That Speak to You
At the end of the day, it’s all about taste. Some days you want something icy and refreshing from the Cold Series, other times you’re craving the smooth, mellow vibes of the Smooth Series. Then there are those sweet cravings — and trust us, the Sweet Series delivers.
Prefer the classic richness of tobacco? There’s a whole series for that too. And if you’re trying to cut back on nicotine, the 0% Nicotine Series gives you all the flavor without the buzz.
Final Thoughts
Vaping in Singapore isn’t just a passing trend — it’s a lifestyle choice for many. With so many options available, from pocket-sized disposables to customizable devices, there’s something for everyone. Whether you’re new to the scene , or a long-time fan, the experience is all about what feels right to you — uniquely yours .
https://griffinkvgv85319.review-blogger.com/57005953/descubre-cГіmo-usar-el-cГіdigo-promocional-1xbet-para-apostar-free-of-charge-en-argentina-mГ©xico-chile-y-mГЎs
v buck fortnite купить – вбаксы подарком, купить в баксы
link brd crypto
купить 1с в москве купить 1с в москве .
1с купить официальный сайт цена 1с купить официальный сайт цена .
prostata
Orbiter Finance: Connecting DeFi Ecosystems
Orbiter Finance is a cutting-edge decentralized finance (DeFi) platform focused on interoperability, liquidity, and seamless asset transfer across multiple blockchains. Its suite of tools and protocols, including Orbiter Swap, Orbiter Fi, and Orbiter Bridge, aims to enhance user experience and expand DeFi capabilities.
orbiter bridge
Orbiter Finance Overview
At its core, Orbiter Finance provides a comprehensive ecosystem designed to facilitate cross-chain interactions, liquidity pooling, and decentralized trading. Its primary goal is to enable users to move assets effortlessly between different blockchain networks, ensuring liquidity and accessibility.
Orbiter Swap
Orbiter Swap is a decentralized exchange (DEX) protocol within the Orbiter ecosystem. It allows users to swap tokens across various blockchains with minimal friction, leveraging the platform’s interoperability features. Orbiter Swap emphasizes low slippage, high security, and fast transaction times.
Orbiter Fi
Orbiter Fi is the yield farming and liquidity provision platform of Orbiter Finance. It enables users to stake their tokens, earn rewards, and participate in liquidity pools across multiple chains. Orbiter Fi aims to maximize returns while maintaining cross-chain compatibility.
Orbiter Bridge
Orbiter Bridge is a core component that facilitates cross-chain asset transfers. It acts as a bridge protocol, securely moving tokens and data between different blockchain networks. The Orbiter Bridge ensures interoperability, security, and speed for cross-chain transactions.
Orbiter Finance Bridge
Orbiter Finance Bridge specifically refers to the bridge infrastructure within the Orbiter ecosystem that connects various blockchain networks. It supports seamless transfer of assets, such as tokens and stablecoins, enabling users to leverage DeFi opportunities across multiple chains.
Orbiter Bridge Finance
Orbiter Bridge Finance encompasses the entire cross-chain transfer and interoperability infrastructure provided by Orbiter. It integrates with Orbiter Swap and Orbiter Fi to create a unified DeFi experience, allowing users to access liquidity, earn yields, and swap tokens across different blockchain ecosystems efficiently.
farmacia online pharma Confia Pharma farmacia online portes gratis
vipertoto
самые популярные песни уннв самые популярные песни уннв .
Мы готовы предложить дипломы любых профессий по приятным ценам. Покупка диплома, подтверждающего обучение в университете, – это грамотное решение. Купить диплом ВУЗа: 4x4zubry.by/forum/messages/forum1/topic65318/message376972/result=new#message376972
цена керамогранит keramogranit-kupit-gs-2.ru .
Diltiazem: euro pharmacy viagra – meijers pharmacy
1inch Exchange: The Leading DeFi Aggregator
1inch Exchange is a decentralized finance (DeFi) aggregator that sources liquidity from various decentralized exchanges (DEXs) to provide users with the best possible rates for token swaps. Its innovative approach optimizes trading efficiency, minimizes slippage, and enhances user experience across multiple blockchain networks.
1inch exchange
1inch Network
The 1inch network is a decentralized ecosystem comprising multiple components, including the 1inch DEX aggregator, liquidity protocols, and governance mechanisms. It operates across various blockchains, such as Ethereum, Binance Smart Chain, Polygon, and more, to facilitate seamless cross-chain trading and liquidity aggregation.
1inch Swap
1inch Swap is the core feature that allows users to exchange tokens directly from their wallets. It intelligently splits orders across multiple DEXs to find the most favorable rates, reducing costs and slippage. This feature is accessible via the 1inch interface or integrated into other DeFi platforms.
1inch Crypto
1inch crypto refers to the native token of the 1inch ecosystem, used for governance, staking, and incentivization. Holding and staking 1inch tokens grants users voting rights on protocol proposals and participation in liquidity mining programs.
1inch DEX
1inch DEX is the decentralized exchange aggregator that connects various liquidity sources to offer optimal trading routes. It enhances liquidity depth and price efficiency by intelligently routing trades across multiple DEXs.
1inch Token
The 1inch token (1INCH) is the governance token of the platform. It enables holders to participate in protocol governance, propose and vote on upgrades, and earn rewards through staking and liquidity mining programs.
Наши специалисты предлагают быстро заказать диплом, который выполняется на оригинальной бумаге и заверен мокрыми печатями, штампами, подписями официальных лиц. Наш документ пройдет лубую проверку, даже с использованием специально предназначенного оборудования. terorizam.listbb.ru/viewtopic.phpf=3&t=2070
Заказать диплом о высшем образовании. Заказ документа о высшем образовании через надежную фирму дарит ряд преимуществ для покупателя. Это решение дает возможность сберечь время и серьезные денежные средства. [url=http://orikdok-v-gorode-kazan-16.ru/]orikdok-v-gorode-kazan-16.ru[/url]
cost of viagra in pharmacy Pharm Express 24 venlor xr generic effexor xr pharmacy
организация видеотрансляций zakazat-onlajn-translyaciyu1.ru .
kra 33at – kraken онион, kraken onion зеркала
viagra daily: VGR Sources – sildenafil cream
kra33.at – kraken ссылка, kra33
Заказать диплом об образовании. Приобретение подходящего диплома через качественную и надежную фирму дарит массу достоинств. Это решение помогает сберечь как продолжительное время, так и значительные деньги. orikdok-v-gorode-kurgan-45.ru
эжекторное водопонижение http://www.stroitelnoe-vodoponizhenie5.ru .
generic viagra online pharmacy canada: where can i buy sildenafil tablets – viagra 1 tablet price
blog link term papers for sale
sildenafil us pharmacy VGR Sources purchase viagra online with paypal
order sildenafil online without prescription: online viagra best – buy viagra discount
https://johsocial.com/story10188812/activa-tu-c%C3%B3digo-promocional-1xbet-y-gana-en-grande
Приобрести диплом университета!
Наши специалисты предлагаютмаксимально быстро приобрести диплом, который выполнен на бланке ГОЗНАКа и заверен печатями, штампами, подписями. Данный диплом способен пройти лубую проверку, даже с применением профессиональных приборов. Решайте свои задачи быстро и просто с нашим сервисом- angelladydety.getbb.ru/viewtopic.phpf=46&t=52265
Although there is not much in it, it is the unpredictability of the JetX crash game that makes room for a thrilling gaming experience. Similar to many other online casino games, JetX’s algorithm is based on a random number generator. This means you won’t accurately know how high the rocket might fly. The Aviator game is quite similar to JetX predictor online game. However, there are some major differences between both games. Here are some of the differences between the Jet X bet and Aviator: To begin with, pay attention to the recent rounds of the JetX game. Take a closer look at the past few crashes and try to understand if there is some pattern in how long the jet flies before crashing. Say, if many were low, consider playing JetX and placing a small bet on a low multiplier next and vice versa.
https://www.wbcs.ac.th/2025/06/05/big-bonanza-slot-bigger-payouts-or-just-a-loud-title/
In addition, the company is developing next generation propulsion systems for both hybrid-electric and and all-battery VTOL aircraft and are being built using additive manufacturing techniques. JETX’s propulsion system uses vectored thrust without rotating the entire propulsion assembly. Whether it’s a fluidic thruster or electric ducted fans, there is a ventral flap mechanism inside the duct work in each propulsion system which vectors the air downward or rearwards. Your shopping cart The Fibonacci strategy was created as an advanced version of Martingale. The JetX strategy aims to both cover all losses and win big with less money. However, Fibonacci also requires rather large deposits and suits only successful professional players. According to Fibonacci for JetX, players must start from $2-5 bets to strictly maintain the strategy and not exceed a maximum bet of $100.
CrestorPharm: Over-the-counter Crestor USA – CrestorPharm
https://politedriver.com/
CrestorPharm: CrestorPharm – Crestor Pharm
https://politedriver.com/
mental health support chatbot http://mental-health2.com .
https://krk-finance.ru/
FDA-approved generic statins online: atorvastatin 10mg side effects – Lipi Pharm
конференц зал под ключ конференц зал под ключ .
оборудование для конференц залов оборудование для конференц залов .
конференц-зале конференц-зале .
top article jaxx liberty
LipiPharm: Lipi Pharm – No RX Lipitor online
Якщо ви хочете побачити найкращу командну роботу в Battle Nexus, обов’язково подивіться на гру Dr Pepper.
https://news-life.pro/moscow/402440904/
zaezd-pod-klyuch-1122.ru .
Мы изготавливаем дипломы психологов, юристов, экономистов и прочих профессий по приятным ценам.– wayworld.listbb.ru/viewtopic.phpf=2&t=35879
Мы можем предложить документы учебных заведений, расположенных в любом регионе РФ. Купить диплом о высшем образовании:
[url=http://hellotrek.com/kachestvennye-diplomy-dlja-vashego-uspeha-197/]hellotrek.com/kachestvennye-diplomy-dlja-vashego-uspeha-197[/url]
автоматический карниз для штор автоматический карниз для штор .
Excellent post however I was wanting to know if you could write a litte more on this subject? I’d be very thankful if you could elaborate a little bit further. Bless you!
hafilat bus card balance check
bee999 app
can rosuvastatin cause joint pain: CrestorPharm – Crestor Pharm
https://semaglupharm.com/# SemagluPharm
Přinášíme vám podrobné informace, které vám pomohou vybrat si společnost, u které máte jistotu, že jsou vaše finance v bezpečí. Díky našim recenzím a odborným článkům zvýšíte svou šanci na výhru, zároveň dbáme na to, abyste byli informováni o riziku prohry. Jsme vaši oporou v každé situaci. Hrajte zodpovědně. K dispozici je také režim automatického hraní. To je pro hráče skvělá funkce, protože díky ní nemusíte pokaždé klikat na tlačítko “vsadit”, aby se kulička spustila. Používáme ji neustále, když hrajeme Plinko v kasinech v České republice. Je také důležité sledovat a analyzovat své sázky. Komunikace s vlastním rozpočtem zahrnuje nejen jeho dodržování, ale také hodnocení, které sázky byly úspěšné. Udržujte si přehled o svých výhrách a prohrách. Tato data vám pomohou upravit váš přístup a udělat informovanější rozhodnutí při budoucích sázkách.
https://www.chordie.com/forum/profile.php?section=identity&id=2328147
Plinko je skutečným hitem mezi crash hrami, dostupnými v mnoha spolehlivých online kasinech. Plinko je široce známý kvůli nepředvídatelnosti konce kola. Může to skončit buď s nízkým kurzem (např. 1.1), nebo obrovským, až do x999 nebo ještě vyšší! Také podíl na popularitě crash-game získal díky jednoduchým pravidlům – prostudovat je natolik, abyste s nimi strávili minutu. Pokud si pojem „Plinko“ vyhledáte v Google Play nebo App Store, najdete spoustu aplikací s tímto názvem. Jak ale poznáte, která je ta „oficiální“? Odpověď je jednoduchá: Plinko nemá žádnou oficiální aplikaci ani webovou stránku. Tuto hru nabízí především nelegální online casina, jelikož hra není v České republice legální. Zmást vás může i webová stránka plinko.cz, která se tváří jako oficiální, ale zavede vás do nelegálního casina.
https://semaglupharm.com/# rybelsus side effects reviews
Приобрести диплом на заказ в столице возможно используя сайт компании. orikdok-5v-gorode-vologda-35.online
1win app download http://1win-app.bet/ .
try this web-site coinbase login
карниз электро карниз электро .
canadian compounding pharmacy: Canada Pharm Global – canadian pharmacy prices
https://indiapharmglobal.com/# India Pharm Global
India Pharm Global: India Pharm Global – India Pharm Global
canadian pharmacy Canada Pharm Global canadian pharmacy mall
helpful site https://exponent.my
reputable indian pharmacies: Online medicine home delivery – mail order pharmacy india
click site https://deq.lat/
Meds From Mexico: purple pharmacy mexico price list – pharmacies in mexico that ship to usa
https://raskapotek.com/# Rask Apotek
Backham
מכשירי אידוי קנאביס מומלצים
עטי אידוי – פתרון חדשני, נוח וטוב לבריאות למשתמש המודרני.
בעולם המודרני, שבו קצב חיים מהיר והרגלי שגרה מכתיבים את היום-יום, עטי אידוי הפכו לאופציה אידיאלית עבור אלה המעוניינים ב חווית אידוי מקצועית, קלה וטובה לבריאות.
מעבר לטכנולוגיה המתקדמת שמובנית במכשירים הללו, הם מציעים סדרת יתרונות בולטים שהופכים אותם לאופציה עדיפה על פני שיטות קונבנציונליות.
עיצוב קומפקטי וקל לניוד
אחד היתרונות הבולטים של עטי אידוי הוא היותם קטנים, קלילים ונוחים לנשיאה. המשתמש יכול לשאת את הVape Pen לכל מקום – למשרד, לנסיעה או למסיבות חברתיות – מבלי שהמוצר יפריע או יתפוס מקום.
העיצוב הקומפקטי מאפשר להסתיר אותו בכיס בקלות, מה שמאפשר שימוש דיסקרטי ונוח יותר.
התאמה לכל הסביבות
עטי האידוי מצטיינים ביכולתם להתאים לשימוש בסביבות מגוונות. בין אם אתם במשרד או באירוע חברתי, ניתן להשתמש בהם באופן לא מורגש ובלתי מפריעה.
אין עשן כבד או ריח עז שעלול להטריד – רק אידוי חלק ופשוט שנותן חופש פעולה גם במקום ציבורי.
ויסות מיטבי בחום האידוי
לעטי אידוי רבים, אחד המאפיינים החשובים הוא היכולת ללווסת את טמפרטורת האידוי בצורה אופטימלית.
תכונה זו מאפשרת לכוונן את השימוש לסוג החומר – קנאביס טבעי, נוזלי אידוי או תמציות – ולהעדפות האישיות.
ויסות החום מבטיחה חוויית אידוי נעימה, טהורה ומקצועית, תוך שימור על הטעמים הטבעיים.
צריכה בריאה וטוב יותר
בניגוד לצריכה בשריפה, אידוי באמצעות עט אידוי אינו כולל שריפה של החומר, דבר שמוביל למינימום של חומרים מזהמים שנפלטים במהלך השימוש.
נתונים מראים על כך שאידוי הוא אופציה בריאה, עם פחות חשיפה לרעלנים.
בנוסף, בשל היעדר שריפה, הטעמים הטבעיים מוגנים, מה שמוסיף לחווית הטעם וה�נאה הכוללת.
פשטות הפעלה ותחזוקה
מכשירי הוופ מיוצרים מתוך גישה של קלות שימוש – הם מתאימים הן לחדשים והן לחובבי מקצוע.
רוב המכשירים מופעלים בהפעלה פשוטה, והתכנון כולל חילופיות של רכיבים (כמו מיכלים או קפסולות) שמפשטים על התחזוקה והאחזקה.
תכונה זו מאריכה את אורך החיים של המוצר ומספקת תפקוד אופטימלי לאורך זמן.
סוגים שונים של עטי אידוי – מותאם לצרכים
המגוון בעטי אידוי מאפשר לכל משתמש לבחור את המוצר המתאים ביותר עבורו:
עטי אידוי לפרחים
מי שמעוניין ב חווית אידוי טבעית, ללא תוספים – ייעדיף עט אידוי לקנאביס טחון.
המכשירים הללו מתוכננים לשימוש בחומר גלם טבעי, תוך שימור מקסימלי על הריח והטעימות הטבעיים של הצמח.
עטי אידוי לשמנים ותמציות
למשתמשים שמחפשים אידוי מרוכז ועשיר בחומרים פעילים כמו THC וקנאבידיול – קיימים מכשירים המתאימים במיוחד לשמנים ותרכיזים.
המוצרים האלה בנויים לשימוש בנוזלים מרוכזים, תוך יישום בחידושים כדי ללספק אידוי עקבי, חלק ועשיר.
—
מסקנות
מכשירי וופ אינם רק אמצעי נוסף לשימוש בקנאביס – הם סמל לאיכות חיים, לחופש ולשימוש מותאם אישית.
בין היתרונות המרכזיים שלהם:
– גודל קומפקטי ונעים לנשיאה
– שליטה מדויקת בטמפרטורה
– חווית אידוי נקייה ובריאה
– הפעלה אינטואיטיבית
– מגוון רחב של התאמה אישית
בין אם זו הפעם הראשונה בוופינג ובין אם אתם צרכן ותיק – עט אידוי הוא ההמשך הלוגי לצריכה מתקדמת, מהנה ובטוחה.
—
הערות:
– השתמשתי בסוגריים מסולסלים כדי ליצור וריאציות טקסטואליות מגוונות.
– כל הגרסאות נשמעות טבעיות ומתאימות לשפה העברית.
– שמרתי על כל המונחים הטכניים (כמו Vape Pen, THC, CBD) ללא שינוי.
– הוספתי סימני חלקים כדי לשפר את הקריאות והסדר של הטקסט.
הטקסט מתאים למשתמשים בישראל ומשלב שפה שיווקית עם פירוט טכני.
messi
Slotbom77
EFarmaciaIt: dr max reso – ryaltris spray ricetta
loperamid receptfritt d vitamin apotek abort tablett apotek
Мы можем предложить дипломы любой профессии по невысоким ценам. Для нас очень важно, чтобы дипломы были доступными для большинства граждан. Приобрести диплом о высшем образовании corsica.forhikers.com/forum/p/128899
новинки клубной музыки 2019 klubnaya-muzyka30.ru .
1с бухгалтерия 8.3 купить цена 1с бухгалтерия 8.3 купить цена .
Мы предлагаем оформление дипломов ВУЗов по всей России и СНГ — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 4637 клиентов воспользовались услугой — теперь ваша очередь.
Купить диплом о среднем образовании — ответим быстро, без лишних формальностей.
Мы предлагаем дипломы психологов, юристов, экономистов и других профессий по выгодным тарифам. Мы можем предложить документы техникумов, которые находятся в любом регионе РФ. Документы выпускаются на “правильной” бумаге самого высокого качества. Это позволяет делать настоящие дипломы, которые не отличить от оригиналов. orikdok-3v-gorode-khabarovsk-27.ru
https://efarmaciait.shop/# vintox 20 mg prezzo
мгимо диплом купить https://arus-diplom3.ru/ .
https://papafarma.com/# 39 de fiebre por los dientes
https://svenskapharma.com/# Svenska Pharma
Мы изготавливаем дипломы любой профессии по приятным ценам. Стоимость может зависеть от выбранной специальности, года получения и образовательного учреждения: k90280ul.beget.tech/2025/06/05/kupite-diplom-i-otkroyte-novye-gorizonty.html
сайт [url=https://t.me/ozempicg/]дулаглутид применение[/url]
Мы предлагаем оформление дипломов ВУЗов в Москве — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 3486 клиентов воспользовались услугой — теперь ваша очередь.
Узнать подробнее — ответим быстро, без лишних формальностей.
отвод дождевой воды от дома дренажными трубами .
онлайн займ на карту без отказа кыргызстан онлайн займ на карту без отказа кыргызстан .
https://pharmaconfiance.shop/# pharmacie fr
Medicijn Punt MedicijnPunt netherlands online pharmacy
скачать 888 старс официальный сайт скачать 888 старс официальный сайт .
Заказать строительное водопонижение Заказать строительное водопонижение .
скачать 888 старс бесплатно http://www.888starz-starz888.ru .
fluconazole uk pharmacy: PharmaConnectUSA – Pharma Connect USA
Pharma Confiance: Pharma Confiance – Pharma Confiance
Aya Group: Обзор и актуальные вакансии
аяко казань
Aya Group — это крупная компания, работающая в различных сферах бизнеса, включая консалтинг, строительство, инвестиции и другие направления. В Казани и других городах она известна как надежный работодатель и деловой партнер.
Вакансии в Aya Group
На официальных ресурсах и популярных платформах часто публикуются вакансии в Aya Group. Вакансии могут включать позиции в области менеджмента, строительства, финансов, IT и других сфер. Для поиска актуальных предложений рекомендуется посетить официальный сайт или крупные сайты по трудоустройству.
ИНН и регистрация
Aya Group зарегистрирована в соответствии с законодательством РФ, и у компании есть свой ИНН. Для получения точных данных о регистрации и юридической информации рекомендуется обратиться к официальным источникам или проверить через налоговые базы данных.
Отзывы о Aya Group в Казани
Отзывы о Aya Group Казань можно найти на различных платформах, таких как Отзовик, Яндекс.Отзывы и Google Reviews. В большинстве случаев отзывы касаются условий работы, уровня зарплат, корпоративной культуры и взаимодействия с клиентами.
Другие названия и связанные компании
Kaz Aya Group — возможно, это филиал или партнерская структура в Казахстане.
Aya Group Consulting — подразделение, специализирующееся на консалтинговых услугах.
Аяко Казань — локальный филиал или партнерская компания в Казани.
Айя Групп — альтернативное написание или транслитерация названия.
Мы изготавливаем дипломы любой профессии по приятным тарифам. КУПИТЬ ДИПЛОМ НА DiplomiKus — kyc-diplom.com/
read the full info here Polskie podziemne forum
Medicijn Punt medicatie apotheek Medicijn Punt
https://medicijnpunt.com/# apotheek kopen
parapharmacie etude: nutri prescription paris – Pharma Confiance
Гороскоп tti-sfedu.ru .
Календарь огородника https://congress-st.ru .
Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий по невысоким ценам. Заказ диплома, подтверждающего окончание университета, – это выгодное решение. Купить диплом о высшем образовании: blogsmap.eu/kupit-diplom-legko-i-bystro-240
versandapotheke bad steben apotheke auf rechnung onlineapothele
купить диплом о образовании купить диплом о образовании .
Календарь стрижек http://www.dorogi34.ru .
PharmaJetzt: Pharma Jetzt – apotheke deutschland
этот сайт https://vodkacasino.net/
pari match download pari match download .
Покупка дипломов ВУЗов в Москве — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 3089 клиентов воспользовались услугой — теперь ваша очередь.
Купить диплом недорого — ответим быстро, без лишних формальностей.
pilule slinda prix medicament en q Pharma Confiance
เว็บสล็อตออนไลน์ รวามเกมพนันออนไลน์ไว้เยอะที่สุด BETFLIK เป็นเว็บผู้ให้บริการ สล็อต ยิงปลา คาสิโน ชั้นนำอันดับ1 ในประเทศไทย betflik789
Medicijn Punt: Medicijn Punt – bestellen medicijnen
Какой сегодня праздник http://novorjev.ru/ .
https://t.me/s/CasinoOnline_Martin
Индивидуальное проектирование
В проектировании современного участка или помещения, неотъемлемую роль играет уникальный дизайн и функционал. Поэтому приобретая купель или бассейн, они должны максимально гармонично вписываться в интерьер, сохраняя комфорт в эксплуатации. Мы предлагаем разработку уникальных проектов по установке купелей и бассейнов. Учитывая Ваши пожелания мы готовы разработать индивидуальный проект с уникальным внешним видом и всевозможным набором оборудования.
888starz ??? [url=www.egypt888starz.net/]www.egypt888starz.net/[/url] .
Мы предлагаем оформление дипломов ВУЗов по всей России и СНГ — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 4377 клиентов воспользовались услугой — теперь ваша очередь.
Купить диплом нового образца — ответим быстро, без лишних формальностей.
Думаєте, що реклама – це лише банери? [url=https://xyzdigitalmedia.com/]Тут[/url] можна розмістити справжню ефективну рекламу для вашого бізнесу.
Заказать диплом любого ВУЗа. Заказ документа о высшем образовании через надежную фирму дарит ряд достоинств для покупателя. Такое решение позволяет сберечь как дорогое время, так и существенные финансовые средства. orikdok-1v-gorode-kaliningrad-39.ru
Medicijn Punt Medicijn Punt medicijn online bestellen
Оформиление дипломов ВУЗов в Москве — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 3717 клиентов воспользовались услугой — теперь ваша очередь.
Купить государственный диплом — ответим быстро, без лишних формальностей.
PharmaJetzt: PharmaJetzt – PharmaJetzt
pokiesnet pokiesnet .
смотреть здесь https://aviator-game-play.com
Thanks for the article. Here’s more on the topic https://cultureinthecity.ru/
нажмите здесь мунжаро отзывы
https://canrxdirect.com/# legitimate canadian pharmacies
Мої друзі скористалися послугами команди професіоналів для ремонту квартири. Результат перевершив усі очікування! Тепер і я мрію про співпрацю з ними.
https://immediateassets-fr.com/
Мы давно мечтали о бане на участке, но не знали, с чего начать. Тогда мы нашли компанию «Что нам стоит», и они помогли нам воплотить мечту в реальность. Специалисты предложили функциональный проект, который включал не только парную, но и зону отдыха. Теперь каждую субботу мы с удовольствием проводим время в бане с семьёй.
https://canrxdirect.shop/# canada drug pharmacy
IndiMeds Direct: IndiMeds Direct – IndiMeds Direct
Покупка дипломов ВУЗов по всей России и СНГ — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 3012 клиентов воспользовались услугой — теперь ваша очередь.
На этой странице — ответим быстро, без лишних формальностей.
Мы предлагаем дипломы любой профессии по выгодным ценам. Важно, чтобы дипломы были доступны для большого количества граждан. Быстро приобрести диплом любого института ipora-vivirbien.com/poluchite-diplom-bez-lishnih-hlopot-237-2
see page https://perena.cfd
Покупка дипломов ВУЗов по всей России и СНГ — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 2968 клиентов воспользовались услугой — теперь ваша очередь.
Пишите в личные сообщения — ответим быстро, без лишних формальностей.
worldwide delivery
Cargo Bolt: Your Trusted Partner in Global Logistics and Transportation
In today’s fast-paced and interconnected world, efficient logistics and transportation are essential for the success of any business. As a trusted name in freight forwarding, Cargo Bolt delivers top-tier services, providing comprehensive solutions for transporting and managing goods across the globe.
With a presence in over 20 countries and an extensive international network of partners and agents, our team focuses on offering superior, customized logistics services tailored to meet the needs of every client.
Comprehensive Freight Services
Cargo Bolt specializes in diverse solutions for moving cargo efficiently, ensuring versatility, rapid delivery, and dependable service:
Ocean Freight Forwarding
Ocean freight plays a foundational function in cross-border movement of goods. Cargo Bolt offers end-to-end ocean freight solutions, including container shipping, route planning, customs clearance, and documentation — all designed to ensure seamless international deliveries.
Road Freight Forwarding
Road transport remains a key aspect of last-mile distribution, especially for regional and last-mile deliveries. We provide affordable yet fast land-based shipping solutions, with options that suit various cargo sizes, distances, and delivery schedules.
Worldwide Transport & Ground Transport
Whether it’s local deliveries or cross-border shipments, our ground transportation services offer adaptable and trustworthy solutions for any freight type. From lightweight items to bulk consignments, we ensure your goods reach their destination without damage and on schedule.
где купить аттестат где купить аттестат .
Ця редакція знає, як писати так, щоб було цікаво!
enclomiphene for men: enclomiphene – enclomiphene
Купить документ ВУЗа можно в нашем сервисе. Купить диплом ВУЗа по невысокой цене возможно, обратившись к проверенной специализированной фирме. nusalancer.netnation.my.id/profile/ramiroshiels23
купить горшок для цветов большой напольный пластиковый в интернет магазине http://kashpo-napolnoe-spb.ru – купить горшок для цветов большой напольный пластиковый в интернет магазине .
https://pechi-troyka.ru
Aerodrome Finance: Innovations and Opportunities
In today’s evolving landscape, the development of aerodrome infrastructure and related financial tools is becoming increasingly significant. This article explores key aspects of aerodrome finance, along with emerging trends in decentralized finance (DeFi), such as aerodrome swap, aerodrome exchange, and aerodrome DEX.
aerodrome finance
What is Aerodrome Finance?
Aerodrome finance refers to the integration of traditional aerodrome operations with modern financial technologies, enabling optimized management of assets, investments, and operations at aerodrome bases. This concept involves creating specialized aerodrome bases that serve as platforms for financial transactions and investment activities.
Aerodrome Base
An aerodrome base is a foundational platform that combines aerodrome infrastructure with financial instruments. It provides transparency, security, and efficiency in asset management and acts as a core for implementing innovative financial solutions.
Aerodrome Swap
An aerodrome swap is a financial instrument allowing participants to exchange assets or liabilities related to aerodrome infrastructure. Such swaps help manage risks associated with fluctuations in asset values or currency exchange rates.
Aerodrome Exchange
An aerodrome exchange is a marketplace for trading assets linked to aerodromes, including tokens representing infrastructure or other financial instruments. It ensures liquidity and market access for investors and operators.
Aerodrome DeFi Solutions
Aerodrome DeFi involves applying decentralized finance protocols within the aerodrome sector. This includes establishing aerodrome finance bases where users can obtain loans, participate in liquidity pools, and earn yields by providing liquidity.
Aerodrome DEX
An aerodrome DEX is a decentralized exchange that facilitates token swaps without intermediaries. This aerodrome DEX promotes local market development and enhances access to financial services for industry participants.
Extra resources https://web-jaxxwallet.io
para quГ© sirve el diprogenta: Farmacia Asequible – Farmacia Asequible
why not look here https://web-breadwallet.com
RxFree Meds: RxFree Meds – RxFree Meds
https://supermolelk.github.io/Promocode-bk.github.io/
recigarum comprar: Farmacia Asequible – Farmacia Asequible
enclomiphene testosterone: enclomiphene citrate – enclomiphene for men
Оформиление дипломов ВУЗов по всей Украине — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 2740 клиентов воспользовались услугой — теперь ваша очередь.
Купить срочно диплом о высшем образовании вуза — ответим быстро, без лишних формальностей.
Коли на Trance Illusion оголосили виступ Kutty, публіка буквально вибухнула від оплесків. Вона вийшла на сцену із таким спокоєм, але як тільки почалося шоу, все змінилося. Світлові хвилі, які вона створювала, рухалися ніби у діалозі з музикою. Я стояв поруч із групою людей, які приїхали з Польщі спеціально заради її виступу. Вони казали, що ще на Global Trance Gathering були під враженням від її роботи. Найбільше вразило, як вона використала лазери, щоб “розрізати” натовп на кольорові сегменти, що рухалися у різні боки. Це виглядало як оживша абстракція. Всі, хто був поруч, казали, що таких інсталяцій більше ніде не побачиш. Після фестивалю я одразу знайшов її сайт, щоб побачити розклад виступів.
Заказать документ ВУЗа можно у нас в столице. Купить диплом ВУЗа по доступной цене вы сможете, обращаясь к надежной специализированной компании. soft-key.uz/read-blog/4565_gde-mozhno-kupit-attestat-9-klass.html
Мы предлагаем оформление дипломов ВУЗов В киеве — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 3855 клиентов воспользовались услугой — теперь ваша очередь.
Купить диплом института высшего образования — ответим быстро, без лишних формальностей.
Thanks for the article. Here’s more on the topic https://adventime.ru/
drenazh-10-sotok-812.ru .
игры с выводом денег без вложений на андроид скачать [url=www.1win1139.ru]www.1win1139.ru[/url]
прогнозы на хоккей на сегодня бесплатно http://luchshie-prognozy-na-khokkej.ru .
можно ли накрутить просмотры рилс в инстаграм [url=https://vc.ru/niksolovov/1690159-kak-nakrutit-prosmotry-rils-25-servisov-sovetov-i-besplatnyh-metodov-v-2025-godu] можно ли накрутить просмотры рилс в инстаграм[/url]
chicken road key parameters
Chicken Road: Real Player Feedback
Chicken Road is a gamblinginspired arcade game that has drawn interest due to its straightforward mechanics, impressive RTP (98%), and innovative cashout option. By analyzing user opinions, we aim to figure out whether this game deserves your attention.
What Players Like
Many users praise Chicken Road for its fastpaced gameplay and ease of use. The option to withdraw winnings whenever you want introduces a tactical element, and the high RTP ensures it feels more equitable compared to classic slots. Beginners love the demo mode, which lets them try the game without risking money. Players also rave about the mobilefriendly design, which performs flawlessly even on outdated gadgets.
Melissa R., AU: “Unexpectedly enjoyable and balanced! The ability to cash out brings a layer of strategy.”
Nathan K., UK: “The arcade style is refreshing. Runs smoothly on my tablet.”
Gamers are also fond of the vibrant, retro aesthetic, making it both enjoyable and captivating.
Areas for Improvement
However, Chicken Road isn’t perfect, and there are a few issues worth noting. A number of users feel the gameplay becomes monotonous and lacks complexity. Some highlight sluggish customer service and a lack of additional options. One frequent criticism is deceptive marketing, as people thought it was a pure arcade game rather than a gambling platform.
Tom B., US: “Fun at first, but it gets repetitive after a few days.”
Sam T., UK: “Advertised as a fun game, but it’s clearly a gambling app.”
Advantages and Disadvantages
Positive Aspects
Simple, fastpaced gameplay
An RTP of 98% guarantees a fair experience
Free demo option for beginners to test the waters
Smooth performance on mobile devices
Negative Aspects
Gameplay can feel repetitive
Not enough features or modes to keep things fresh
Customer service can be sluggish and unreliable
Deceptive advertising
Conclusion
Chicken Road shines through its openness, impressive RTP, and ease of access. Perfect for relaxed gaming sessions or newcomers to online betting. However, its reliance on luck and lack of depth may not appeal to everyone. To maximize enjoyment, stick to authorized, regulated sites.
Rating: 4/5
A balanced blend of fun and fairness, with potential for enhancement.
888starz регистрация [url=https://888starz.com.ru/]888starz регистрация[/url] .
Мы предлагаем дипломы психологов, юристов, экономистов и любых других профессий по выгодным тарифам. Заказ документа, подтверждающего обучение в ВУЗе, – это грамотное решение. Приобрести диплом любого ВУЗа: globalscaffolders.com/employer/diplomy-grup-24
Мы предлагаем оформление дипломов ВУЗов В киеве — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 1234 клиентов воспользовались услугой — теперь ваша очередь.
Купить дипломы о высшем образовании цена — ответим быстро, без лишних формальностей.
viagra kuwait pharmacy: RxFree Meds – eckerd pharmacy store locator
view publisher site https://hyperdrive.pw/
buclizina en espaГ±a la farmacia.es opiniones Farmacia Asequible
Оформиление дипломов ВУЗов В киеве — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 3336 клиентов воспользовались услугой — теперь ваша очередь.
Здесь — ответим быстро, без лишних формальностей.
Thanks for the article. Here’s more on the topic https://yarus-kkt.ru/
RxFree Meds: steroid online pharmacy – RxFree Meds
have a peek here https://flaunch.cc
кашпо для цветов на пол [url=http://kashpo-napolnoe-rnd.ru/]кашпо для цветов на пол[/url] .
Resources https://verio.buzz/
диплом старого образца купить диплом старого образца купить .
нужен проект перепланировки квартиры https://proekt-pereplanirovki-kvartiry1.ru .
музыка на телефон скачать бесплатно музыка на телефон скачать бесплатно .
read this article https://blendfun.xyz/
Farmacia Asequible Farmacia Asequible Farmacia Asequible
enclomiphene citrate: buy enclomiphene online – enclomiphene buy
mexican rx online mexico drug stores pharmacies buying prescription drugs in mexico online
Thanks for the article. Here’s more on the topic https://orenbash.ru/
https://meximedsexpress.com/# MexiMeds Express
Мы предлагаем оформление дипломов ВУЗов В киеве — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 4967 клиентов воспользовались услугой — теперь ваша очередь.
Звоните — ответим быстро, без лишних формальностей.
На Gamma Festival я очікував більше гармонії між музикою і організацією, але вийшло не зовсім так. Виступ DJ Fisher був чудовим, але звук на деяких сценах залишав бажати кращого. Лазери і світлові ефекти були красивими, але іноді здавалися надмірними і відволікали від музики. У лаунж-зоні було занадто багато людей, що робило її мало придатною для релаксу. Відчувалося, що організатори більше дбали про декорації, ніж про комфорт гостей.
more https://iguanadex.cc/
https://meximedsexpress.shop/# mexican drugstore online
диплом о высшем образовании с занесением в реестр купить диплом о высшем образовании с занесением в реестр купить .
IndoMeds USA: indianpharmacy com – IndoMeds USA
medication canadian pharmacy: MediSmart Pharmacy – legitimate canadian mail order pharmacy
678bd
world pharmacy india IndoMeds USA online pharmacy india
georgia board of pharmacy: MediSmart Pharmacy – drug store pharmacy
Оформиление дипломов ВУЗов В киеве — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 3875 клиентов воспользовались услугой — теперь ваша очередь.
На сайте — ответим быстро, без лишних формальностей.
https://immediateedge-app.de/
Thanks for the article. Here’s more on the topic https://avto-yar.ru/
купить диплом с регистрацией купить диплом с регистрацией .
Lead generation strategies
Инновационные решения в сфере автомоек: роботизированные и умные мойки
В современном мире автоматизация и интеллектуальные технологии активно внедряются в различные сферы бизнеса, и автомойки — не исключение. Сегодня всё больше владельцев автосервисов и предпринимателей выбирают робот мойку или умную мойку, чтобы повысить эффективность, снизить издержки и обеспечить клиентам высокий уровень сервиса.
робот мойка в москве
Что такое робот мойка и умная мойка?
Робот мойка
Это автоматизированное оборудование, которое использует роботизированные системы для мойки автомобилей. Такие системы могут включать портальные мойки, роботизированные установки и бесконтактные автоматические станции. Основные преимущества — высокая скорость и качество мойки, минимальное участие человека и возможность обработки различных типов транспортных средств.
Умная мойка
Это концепция, объединяющая автоматические системы с интеллектуальными технологиями, позволяющими управлять процессом через мобильные приложения или порталы. Включает мойки под ключ самообслуживания, сеть умных моек — портал для управления несколькими станциями, а также интеграцию с системами оплаты и мониторинга.
Виды автоматических и роботизированных моек
Автоматические мойки бывают различных типов: полностью автоматические станции, портальные системы, роботизированные установки и мойки самообслуживания. Они отличаются по стоимости, скорости и уровню автоматизации. Например, автоматическая бесконтактная автомойка — это быстрая и бесконтактная станция, подходящая для больших потоков клиентов, а робот мойка — более технологичное решение с возможностью мойки грузовиков и автомобилей премиум-класса.
Роботизированные системы позволяют обеспечить высокое качество мойки с минимальным износом оборудования, а также снизить расходы на обслуживание. В Москве и других крупных городах популярны решения, такие как робот мойка в Москве или робот мойка автомобилей в Москве, которые позволяют открыть бизнес с минимальными затратами и высокой рентабельностью.
Технологии и оборудование для автомоек
Ключевыми компонентами являются роботы для мойки автомобилей, оборудование для мойки самообслуживания, а также системы автоматической и бесконтактной мойки. Например, роботомойка — это современное решение, которое позволяет автоматизировать весь процесс и обеспечить высокое качество обслуживания. Цена на оборудование для роботизированных мойок под ключ начинается примерно от 2 миллионов рублей и выше, в зависимости от комплектации и уровня автоматизации.
Франшизы автомоек, такие как франшиза робот мойка, позволяют предпринимателям быстро запустить бизнес, используя проверенные модели и бренды. Также популярны готовые бизнес-проекты, например, купить готовый бизнес автомойки в Москве или купить автомойку в Москве от собственника.
Особенности и преимущества роботизированных мойок в Москве и России
Робот мойка в Москве и других крупных городах становится всё более востребованной благодаря своей эффективности и современному подходу. Такие системы позволяют снизить расходы на персонал, повысить качество мойки и обеспечить круглосуточную работу без перерывов. Цена на робот мойку под ключ с установкой в Москве обычно начинается от 2 миллионов рублей, что делает такие решения доступными для среднего и крупного бизнеса.
Открытие автомойки робот или мойки под ключ — перспективное направление для инвестиций, особенно при использовании современных технологий и автоматизированных систем. В Москве существует множество предложений по оборудованию, франшизам и готовым бизнес-проектам, что позволяет выбрать оптимальный вариант для любого бюджета.
Бизнес-план и развитие
Основные шаги для открытия роботизированной автомойки включают выбор подходящего места, проектирование и получение разрешений, закупку оборудования и его установку. Важным аспектом является создание портальной мойки или мойки самообслуживания, что позволяет привлекать клиентов с разными потребностями.
Франшизы и готовые бизнес-планы помогают снизить риски и ускорить запуск проекта. В Москве и других городах России популярны решения, такие как робот мойка в Москве или робот мойка автомобилей в Москве, что делает этот сегмент привлекательным для инвесторов.
IndoMeds USA IndoMeds USA IndoMeds USA
se puede comprar tadalafil sin receta farmacia online de alcazar de san juan mounjaro se puede comprar sin receta
ВїquГ© relajante muscular puedo comprar sin receta? Clinica Galeno se puede comprar pectox sin receta
surgam sans ordonnance: clarelux 500 sans ordonnance – cialis 20 mg
https://clinicagaleno.com/# online farmacia barcelona
где купить аттестат за 11 классов в воронеже где купить аттестат за 11 классов в воронеже .
купить диплом техникума с занесением в реестр купить диплом техникума с занесением в реестр .
купить диплом техникума с занесением в реестр купить диплом техникума с занесением в реестр .
сайт https://kubanya.ru/
Оформиление дипломов ВУЗов В киеве — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 1740 клиентов воспользовались услугой — теперь ваша очередь.
Перейти — ответим быстро, без лишних формальностей.
farmacia francia online: OrdinaSalute – annister 25.000 prezzo
http://pharmadirecte.com/# codoliprane 500 sans ordonnance
farmacia morlГЎn online: Clinica Galeno – puedes comprar la pastilla del dia despues sin receta
https://clinicagaleno.shop/# comprar botox en andorra sin receta
частная стоматология в Архангельске частная стоматология в Архангельске .
medicijnen apotheek: Medicijn Punt – п»їmedicijnen bestellen
https://t.me/s/TopTg_1WIN
Theoption is a binary options platform designed for simplicity and speed. With a user-friendly interface and short-term trades that can finish in just 30 seconds, it suits those seeking quick decision-making opportunities. Even beginners can get started with a low initial deposit, and mobile compatibility allows trading from anywhere. It’s a practical option for people exploring digital investing. For more details, visit yomimonoweb.jp.
диплом купить о среднем образовании диплом купить о среднем образовании .
https://zorgpakket.com/# apotheken
Идеи вашего дома. Информация о дизайне и архитектуре.
Syndyk – это место, где каждый день вы можете увидеть много различных дизайнерских решений,
деталей для вашей квартиры, проектов домов, лучшая сантехника.
Если вы дизайнер или архитектор, то мы с радостью разместим ваш проект на Сундуке.
На сайте можно и даже нужно обмениваться мнениями и информацией о дизайне и архитектуре.
Сайт: syndyk.by
Идеи вашего дома. Информация о дизайне и архитектуре.
Syndyk – это место, где каждый день вы можете увидеть много различных дизайнерских решений,
деталей для вашей квартиры, проектов домов, лучшая сантехника.
Если вы дизайнер или архитектор, то мы с радостью разместим ваш проект на Сундуке.
На сайте можно и даже нужно обмениваться мнениями и информацией о дизайне и архитектуре.
Сайт: syndyk.by
прогнозист ру http://www.stavki-na-sport-prognozy1.ru .
Покупка дипломов ВУЗов по всей Украине — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 3745 клиентов воспользовались услугой — теперь ваша очередь.
Обращайтесь — ответим быстро, без лишних формальностей.
купил диплом легально купил диплом легально .
Гидроизоляция зданий https://gidrokva.ru и сооружений любой сложности. Фундаменты, подвалы, крыши, стены, инженерные конструкции.
Оформиление дипломов ВУЗов В киеве — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 1918 клиентов воспользовались услугой — теперь ваша очередь.
Обращайтесь — ответим быстро, без лишних формальностей.
IndiaMedsHub: buy medicines online in india – buy medicines online in india
investigate this site
ASIA GLOBAL AVIATION MAINTENANCE
top online pharmacy india IndiaMedsHub top 10 online pharmacy in india
SEO Pyramid 10000 Backlinks
Backlinks of your site on community platforms, sections, threads.
Three-stage backlink strategy
Stage 1 – Simple backlinks.
Phase 2 – Links via 301 redirects from authoritative sites with PageRank PR 9–10, for example –
Step 3 – Listing on SEO analysis platforms –
The key benefit of link analysis platforms is that they show the Google search engine a site map, which is essential!
Explanation for the third stage – only the homepage of the site is added to analyzers, internal pages aren’t accepted.
I complete all steps sequentially, resulting in 10,000–20,000 backlinks from the three stages.
This backlink strategy is highly efficient.
Example of submission on SEO platforms via a TXT file.
https://basolinovoip.com/
indian pharmacies safe: IndiaMedsHub – pharmacy website india
Hi it’s me, I am also visiting this website on a regular basis, this website is really fastidious and the users are actually sharing nice thoughts.
Local limo company near me
Накрутка подписчиков в Телеграм бесплатно [url=https://vc.ru/niksolovov/1284904-nakrutka-podpischikov-v-telegram-besplatno-top-19-servisov-2025-goda-preimushestva]Накрутка подписчиков в Телеграм бесплатно[/url]
купить аттестат за 11 классов в сочи http://arus-diplom21.ru/ .
http://expresscarerx.org/# nabp pharmacy viagra
Ищешь лучшие места для ставок с минимальными рисками? Мы покопались в мире азартных игр и подготовили для тебя Топ 15 надежных онлайн-казинo с минимальными ставками! Каждое из этих казинo имеет лицензию, так что можешь смело играть, не беспокоясь о безопасности.
https://t.me/TopTG_Casino777/252
Ищешь лучшие места для ставок с минимальными рисками? Мы покопались в мире азартных игр и подготовили для тебя Топ 15 надежных онлайн-казинo с минимальными ставками! Каждое из этих казинo имеет лицензию, так что можешь смело играть, не беспокоясь о безопасности.
https://t.me/TopTG_Casino777/559
Оформиление дипломов ВУЗов по всей Украине — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 4094 клиентов воспользовались услугой — теперь ваша очередь.
Диплом о высшем образовании купить — ответим быстро, без лишних формальностей.
Приобрести диплом под заказ можно используя сайт компании. comptonrpp.listbb.ru/viewtopic.php?f=6&t=4582
https://medimexicorx.com/# MediMexicoRx
visite site https://rate-x.xyz/
https://it.immediateedge-france.com/
Купить диплом под заказ в Москве возможно через официальный портал компании. x91392sl.beget.tech/2025/07/07/sdelaem-diplom-po-vashemu-zaprosu.html
ai therapy bot ai therapy bot .
купить диплом в кургане занесением в реестр купить диплом в кургане занесением в реестр .
Якщо ви ведете бізнес, вам точно потрібне якісне просування. Тут можна знайти ефективні рішення.
Thanks for the article. Here’s more on the topic https://svetnadegda.ru/
аттестат за 11 класс 2014 купить аттестат за 11 класс 2014 купить .
подробнее safelychange обменник
kraken актуальные ссылки
Читать статью: Опасные мифы о здоровом питании: 4 факта, которые могут навредить вашему здоровью
https://zoloft.company/# Zoloft online pharmacy USA
generic Finasteride without prescription: order generic propecia without dr prescription – Propecia for hair loss online
gessi каталог gessi-santehnika-3.ru .
Оформиление дипломов ВУЗов В киеве — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 1199 клиентов воспользовались услугой — теперь ваша очередь.
Как купить диплом — ответим быстро, без лишних формальностей.
купить дубликат аттестата за 11 класс https://arus-diplom25.ru/ .
Thanks for the article. Here’s more on the topic https://remonttermexov.ru/
Оформиление дипломов ВУЗов по всей Украине — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 3041 клиентов воспользовались услугой — теперь ваша очередь.
Диплом купить — ответим быстро, без лишних формальностей.
Покупка дипломов ВУЗов В киеве — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 1817 клиентов воспользовались услугой — теперь ваша очередь.
Где можно купить диплом — ответим быстро, без лишних формальностей.
lexapro generic brand name Lexapro for depression online lexapro prescription price
blacksprut сайт
generic sertraline cheap Zoloft cheap Zoloft
more helpful hints https://zoth.my
http://xn--80aafabrjladsicc1amg1o4cf1dg.online/
Thanks for the article. Here’s more on the topic https://my-caffe.ru/
Here’s more on the topic https://voenoboz.ru/
generic brand for lexapro: Lexapro for depression online – lexapro online prescription
original site https://lagoon.icu/
я купил проведенный диплом я купил проведенный диплом .
informative post https://kikifinance.xyz
Zoloft for sale purchase generic Zoloft online discreetly buy Zoloft online without prescription USA
Here’s more on the topic https://voenoboz.ru/
винлайн букмекерская бонус винлайн букмекерская бонус .
https://immediateprofit.cc/ja/
What Makes avantprotocol.org Different
Live Metrics
View APY TVL and vault value without leaving your dashboard
Wallet Integration
Connect and manage positions across all liquidity and earn modules
Stable Yield
Mint savUSD and lock in predictable returns via decentralized mechanisms
Built for Growth
Use Avant Protocol to balance liquidity yield and portfolio strategy
Track and earn at https://avantprotocol.org
Kpoker德州撲克
Kpoker德州撲克的使命,是為全球華人玩家打造最值得信賴的線上德州撲克平台。我們致力於提供一個公平、公正且充滿挑戰性的遊戲環境,讓每一位玩家無論經驗多寡,都能在這裡找到屬於自己的撲克節奏。我們相信,撲克是一場融合智慧、耐心與心理戰的經典對局。我們不僅提供高品質的遊戲體驗,也推動撲克文化的傳播與教育,從新手教學到高手對決,陪伴玩家從入門邁向專業,從興趣走向熱情。Kpoker 不只是遊戲,更是連結全球撲克愛好者的橋樑。
Покупка дипломов ВУЗов по всей Украине — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 3574 клиентов воспользовались услугой — теперь ваша очередь.
Купить диплом Киев — ответим быстро, без лишних формальностей.
https://poloniya.ru/
Заказать диплом под заказ возможно через сайт компании. interns24x7.com/employer/diploms-ukraine
Thanks for the article. Here’s more on the topic https://orenbash.ru/
аттестат за 11 класс 2006 купить аттестат за 11 класс 2006 купить .
Читать новость: Как улучшить сон: 3 напитка для крепкого сна
https://t.me/s/TeleCasino_1win
AI platform https://bullbittrade.com for passive crypto trading. Robots trade 24/7, you earn. Without deep knowledge, without constant control. High speed, security and automatic strategy.
Покупка дипломов ВУЗов по всей Украине — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 3005 клиентов воспользовались услугой — теперь ваша очередь.
Обращайтесь — ответим быстро, без лишних формальностей.
Discover The JILI869!
Welcome to JILI869, your ultimate destination for thrilling online slots and casino games! Dive into a vast collection featuring thousands of free slots and real money games from top provider JILI. Discover your next favorite game at JILI869 today!
[url=https://jili869.com/]jili video poker[/url]
About JILI869
At JILI869, we pride ourselves on offering an unparalleled selection of the hottest online slots, including top hits like Super Ace, Agent Ace, and Night City. Explore popular titles and hidden gems, ensuring endless entertainment you won’t find anywhere else!
Choose how you play at JILI869! Enjoy thousands of online slots for real money, try out games risk-free in demo mode, or compete in exciting free or real money slot.
JILI869 is committed to player choice and entertainment. Whether you prefer playing free demo games or entering real money games, we provide a fun and engaging platform for everyone, regardless of budget.
[url=https://jili869.com/]jili apk[/url]
Play with confidence at JILI869. As a licensed operator, we ensure a secure environment and adhere to strict Safer Gambling practices, offering you peace of mind while you enjoy our vast selection of casino games.
JILI869
PLAY NOW
Our RTP Guarantee
At JILI869, transparency is key. Our RTP Guarantee ensures we always provide the highest possible Return to Player percentage published by game providers for all our real money online slots, maximizing your potential returns.
fengshen
https://jili869.com/
Understanding RTP Differences
Did you know online slots can have different RTP settings? Game developers often release titles with varying payout percentages. For instance, a popular slot might be offered at 96%, 94%, or even lower, significantly impacting potential player returns.
A higher RTP means a lower house edge for the casino and better value for you. JILI869 is committed to selecting the highest available RTP setting for every slot, ensuring fairness and transparency.
Our promise is simple: we always choose the top RTP version available for every online slot. This commitment minimizes the house edge and provides you, the player, with the best possible and fairest gaming experience at JILI869.
Always Play Safely
Enjoying real money slots at JILI869 should always be fun and safe. Remember that gambling involves risk and can be addictive. We encourage responsible play; here are essential tips for staying in control:
Set a budget
Always have a predetermined bankroll before playing. This is a certain amount of money that you are willing to part with.
Track your spending
Keep track of how much money you spend while playing slots online using a budget app or spreadsheet.
Set a reality check timeframe
Set up regular reminders to help you keep track of your gaming time and maintain control.
Don’t chase losses
Stop playing when you hit your budget. Gaming should always be fun and entertaining.
https://theshaderoom.com/articl/1xbet_promo_code_registration___free_vip_bonus____130.html
https://mbaccounting.ca/pages/45sovety_po_prohoghdeniyu_igry_tom_clancy_039s_splinter_cell_blacklist_missiya_12_zona_f_sa.html
https://materialdrive.com/pages/sovet_po_prohoghdeniyu_prince_of_persia_the_two_thrones_gayd_023.html
купить диплом о высшем образовании реестр купить диплом о высшем образовании реестр .
Майстер-клас із японських танців у Токіо став для мене неймовірним досвідом. Танцювальні рухи не лише навчають вас традиціям, але й допомагають краще зрозуміти філософію гармонії та поваги. Після цього майстер-класу я відчуваю себе більш збалансованою людиною. Якщо хочете долучитися до такого досвіду, дізнайтеся більше тут.
It all started back in March, when dozens of surfers at beaches outside Gulf St Vincent, about an hour south of state capital Adelaide, reported experiencing a sore throat, dry cough and blurred vision after emerging from the sea.
[url=https://trip-scan.org]tripscan top[/url]
Shortly after, a mysterious yellow foam appeared in the surf. Then, dead marine animals started washing up.
Scientists at the University of Technology Sydney soon confirmed the culprit: a buildup of a tiny planktonic algae called Karenia mikimotoi. And it was spreading.
https://trip-scan.org
трипскан сайт
In early May, the government of Kangaroo Island, a popular eco-tourism destination, said the algal bloom had reached its coastline. A storm at the end of May pushed the algae down the coast into the Coorong lagoon. By July, it had reached the beaches of Adelaide.
Diverse algae are essential to healthy marine ecosystems, converting carbon dioxide into oxygen and benefiting organisms all the way up the food chain, from sea sponges and crabs to whales.
But too much of one specific type of algae can be toxic, causing a harmful algal bloom, also sometimes known as a red tide.
While Karenia mikimotoi does not cause long-term harm to humans, it can damage the gills of fish and shellfish, preventing them from breathing. Algal blooms can also cause discoloration in the water and block sunlight from coming in, harming ecosystems.
The Great Southern Reef is a haven for “really unique” biodiversity, said Bennett, a researcher at the University of Tasmania, who coined the name for the interconnected reef system which spans Australia’s south coast.
About 70% of the species that live there are endemic to the area, he said, meaning they are found nowhere else in the world.
“For these species, once they’re gone, they’re gone.”
CanadRx Nexus: 77 canadian pharmacy – canadian pharmacy drugs online
Давно не зустрічав такої якісної роботи з контентом. Дякую редакції!
What a data of un-ambiguity and preserveness of precious knowledge on the topic of unpredicted emotions.
https://tennis-club.kiev.ua/sklo-fary-v-umovakh-perehrivu-fizyka-protsesu.html
CanadRx Nexus: canadian pharmacy in canada – CanadRx Nexus
Visit Website
sky kingdom aviation
https://goldenpowerlebedka.ru/
кракен даркнет ссылка – kraken darknet ссылка, ссылка на кракен даркнет
аттестат за 10 11 класс купить аттестат за 10 11 класс купить .
https://telegra.ph/Rejting-Kazino-2025-Top-Kazino-Onlajn-dlya-Igrokov-08-01
где купить аттестат за 11 класс в челябинске где купить аттестат за 11 класс в челябинске .
德州撲克規則
學會德州撲克規則,是踏入撲克世界的第一步。從掌握下注節奏、理解牌型,到實戰中運用策略,每一步都能讓你更加上手並享受對戰樂趣。想立刻開始實戰練習?我們推薦【Kpoker 德州撲克系統】,提供真實匹配環境與新手教學模式,現在註冊還能獲得免費體驗金,讓你零風險上桌實戰!
Today, I went to the beach with my kids. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear. She never wants to go back! LoL I know this is totally off topic but I had to tell someone!
buy doxycycline 100 mg
MexiCare Rx Hub: MexiCare Rx Hub – MexiCare Rx Hub
Here is another site on the topic top 10 best books on kindle unlimited 2024
德州撲克規則
你是不是也想學德州撲克,卻被一堆術語搞得霧煞煞?別擔心,這篇就是為你準備的「規則懶人包」,從發牌、下注到比牌,5 個階段、5 種行動,一次搞懂!德州撲克新手必看!快速掌握德撲規則與下注方式,從發牌、翻牌到比牌,一次看懂德州撲克 5 大階段與 5 種行動,不再上桌搞不懂規則。
加密貨幣
值得信賴的研究和專業知識匯聚於此。自 2020 年以來,Techduker 已幫助數百萬人學習如何解決大大小小的技術問題。我們與經過認證的專家、訓練有素的研究人員團隊以及忠誠的社區合作,在互聯網上創建最可靠、最全面、最令人愉快的操作方法內容。
Купить диплом возможно используя официальный портал компании. khvoynaya.getbb.ru/viewtopic.php?f=39&t=9096
MexiCare Rx Hub: MexiCare Rx Hub – MexiCare Rx Hub
https://badgerboats.ru/
德州撲克
你以為德州撲克只是比誰運氣好、誰先拿到一對 A 就贏?錯了!真正能在牌桌上長期贏錢的,不是牌運好的人,而是會玩的人。即使你手上拿著雜牌,只要懂得出手時機、坐在搶分位置、會算賠率——你就能用「小動作」打敗對手的大牌。本文要教你三個新手也能馬上用的技巧:偷雞、位置優勢、底池控制。不靠運氣、不靠喊 bluff,用邏輯與技巧贏得每一手關鍵牌局。現在,就從這篇開始,帶你從撲克小白進化為讓對手頭痛的「策略玩家」!
https://immediateapex-ai.org/ja/
lasix side effects: lasix 40mg – generic lasix
кракен онион маркет – ссылка на кракен, кракен актуальная ссылка
AsthmaFree Pharmacy: AsthmaFree Pharmacy – AsthmaFree Pharmacy
Мы предлагаем оформление дипломов ВУЗов по всей Украине — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 3677 клиентов воспользовались услугой — теперь ваша очередь.
Диплом колледжа купить — ответим быстро, без лишних формальностей.
Мы предлагаем оформление дипломов ВУЗов по всей Украине — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 1547 клиентов воспользовались услугой — теперь ваша очередь.
Покупка диплома — ответим быстро, без лишних формальностей.
ссылка на сайт https://krak37at.at
промокод 1хбет на сегодня бесплатно
durvet ivermectin paste equine dewormer ivermectin medication IverCare Pharmacy
Вам нужны щедрые #бонусы, выгодные #акции и свежие #промокоды для #1Win (#1Вин)? Тогда присоединяйтесь на наш Telegram-канал Web_1win!
Здесь вы найдете:
Актуальные #зеркало чтобы #войти на официальный #1Вин. Больше блокировок и проблем с доступом!
Данные о лучших #играх и #казино. Обзоры, стратегии и рекомендации для максимизации твоих шансов на победу.
Детальные инструкции по #регистрации и старту игры. Легкий начало для начинающих.
Информация о #турнирах с большими призовыми фондами. Участвуйте и выигрывайте!
Советы по #безопасности вашего аккаунта и финансов. Мы заботимся о твоей сохранности.
Отзывы о #мобильный приложении #1Вин. Наслаждайтесь игрой где угодно и когда угодно!
Реальные #отзывы клиентов о #1Вин. Посмотрите, что говорят другие!
Подписывайтесь прямо сейчас и получите ключ к миру выгод и азарта с #1Win! Ссылка: скачать 1вин на андроид
semaglutide acid reflux: rybelsus generic – metformin vs semaglutide
Вам интересны крупные #бонусы, прибыльные #акции и актуальные #промокоды для #1Win (#1Вин)? Тогда присоединяйтесь на наш Telegram-канал Web_1win!
У нас вы найдете:
Рабочие #зеркало чтобы #войти на официальный #1Вин. Никаких ограничений и проблем с доступом!
Данные о лучших #играх и #казино. Обзоры, стратегии и рекомендации чтобы увеличения твоих шансов на выигрыш.
Подробные инструкции по #регистрации и началу игры. Легкий начало для начинающих.
Анонсы о #турнирах с большими призовыми фондами. Участвуйте и побеждайте!
Рекомендации по #безопасности твоего аккаунта и финансов. Наша команда заботимся о твоей защите.
Обзоры о #мобильный приложении #1Вин. Играйте где захотите и когда угодно!
Реальные #отзывы клиентов о #1Вин. Посмотрите, что думают другие!
Присоединяйтесь прямо сейчас и не упустите шанс получить ключ к вселенной успеха и азарта с #1Win! Ссылка: играть в 1вин
blog here jax wallet
rybelsus over the counter AsthmaFree Pharmacy AsthmaFree Pharmacy
Zanaflex medication fast delivery: Tizanidine 2mg 4mg tablets for sale – cheap muscle relaxer online USA
Накрутка подписчиков в ТГ канал живые вот статья: https://vc.ru/niksolovov/1481423-nakrutka-podpischikov-v-tg-kanal-zhivye-top-25-servisov-2025-goda-moi-reiting Только проверенные бесплатные и платные способы получить больше подписчиков.
такой https://kra36at.at/
купить диплом о высшем образовании в москве купить диплом о высшем образовании в москве .
купить аттестат об окончании 11 классов в нижнем новгороде купить аттестат об окончании 11 классов в нижнем новгороде .
купить аттестат 11 класса в череповце купить аттестат 11 класса в череповце .
kraken darknet tor – кракен зеркало, kraken darknet ссылка
Thanks for the article https://40-ka.ru/
как купить аттестат за 11 класс форум как купить аттестат за 11 класс форум .
купить аттестат за 11 класс в воронеже купить аттестат за 11 класс в воронеже .
где купить аттестат за 11 класс в новосибирске где купить аттестат за 11 класс в новосибирске .
купить диплом с занесением в реестр украина купить диплом с занесением в реестр украина .
Situs judi resmi berlisensi: Live casino Mandiribet – Live casino Mandiribet
plastikovyy-pogreb-kupit-812.ru .
этот контент https://krkn36.at
Мы готовы предложить документы любых учебных заведений, расположенных на территории всей России. Заказать диплом любого ВУЗа:
купить аттестат об окончании 11 классов занесением в реестр
Хтось знає, як працює Як працює гравітація? Завжди було цікаво, чому ми не відчуваємо сили тяжіння напряму.
продвижение сайтов
pop over to this web-site
jaxx wallet liberty
Щоб ваша випічка була смачною, важливо знати, як правильно зберігати борошно.
строительство фундаментов ушп .
india pharmacy mail order: Indian Meds One – best india pharmacy
go to this site
toast wallet website
buy antibiotics over the counter in mexico: Mexican Pharmacy Hub – Mexican Pharmacy Hub
Home Page
toast wallet app
I recommend https://ancientcivs.ru/
buy modafinil from mexico no rx: sildenafil mexico online – Mexican Pharmacy Hub
this contact form
toast wallet app
their website
toast wallet xrp
buy prescription drugs from india: indian pharmacy – reputable indian pharmacies
Why cortexprotocol.org
CX Infrastructure
Buy CX convert assets and research via Cortex Deep Search
Secure Wallet Tools
Connect and manage your balance positions and trades
Agent Automation
AI agent that acts on your behalf using live data
Onchain Research
Access code documentation and real time protocol stats
Trade with insight at https://cortexprotocol.org
Говорили про sevenup на останньому заході, і всі були вражені їхнім підходом до гри. Команда безсумнівно заслужила своє місце на вершині.
ushp-fundament-pod-klyuch-499.ru .
https://tadalify.com/# cialis generico
God see
фундамент ушп цена под ключ .
plastikovyy-pogreb-247.ru .
have a peek at these guys https://aera.ink
i was reading this https://latch.icu
https://kamameds.com/# Compare Kamagra with branded alternatives
check out this site https://lagoon.icu
a fantastic read https://lavarage.cc/
заправка газгольдеров сжиженным газом .
What’s up to all, how is the whole thing, I think every one is getting more from this website, and your views are fastidious designed for new viewers.
https://degustator.net.ua/chy-sumisnyj-klej-dlya-skla-fary-iz-zavodskym.html
Наша команда продовжує дивувати, і ми всі очікуємо на нові великі перемоги в кіберспортивних турнірах!
cialis for sale online in canada: cialis mexico – cialis no perscription overnight delivery
bandar togel terbesar
**Info Terbaru Event Spin Toto Slot 88 & Pasang Angka Togel 4D Unggulan – TOGELONLINE88**
нажмитеhyip под ключ
cialis from canada: Tadalify – Tadalify
toto slot 4d
TOGELONLINE88 membawakan berita seru seputar kompetisi spin Toto Slot 88 dan prediksi 4D terakurat. Situs ini menyediakan sistem resmi yang terpercaya, hasil valid, serta pengalaman gaming dengan sistem terorganisir.
Lebih dari itu, TOGELONLINE88 juga menyediakan banyak penyedia permainan slot dan tembak ikan yang bisa dimainkan kapanpun dan dimanapun, dengan potensi memenangkan hadiah jackpot maksimal yang luar biasa besar.
Kepada penikmat game togel & slot digital, TOGELONLINE88 adalah destinasi utama karena menjamin kemudahan, keamanan, dan pengalaman seru saat bermain. Dengan berbagai promo menarik serta sistem yang mudah diakses, platform ini memberikan pengalaman bermain luar biasa.
Jadi, tunggu apa lagi? Ikuti sekarang kompetisi spin Toto Slot 88 dan prediksi angka 4D terpercaya cuma di TOGELONLINE88. Raih kesempatan menang besar dan nikmati sensasi jackpot maxwin yang fantastis!
здесь
blacksprut sprut
IverGrove what is ivermectin 3 mg used for ivermectin 12 mg tablet buy
Предлагаем широкий выбор надежных мини-погрузчиков от ведущих мировых производителей — Lonking, Bobcat и JCB.
Эти машины сочетают в себе высокую производительность, маневренность и долговечность, что делает
их идеальными помощниками в строительстве, сельском хозяйстве, коммунальном хозяйстве и логистике.
Lonking — оптимальное решение для тех, кто ищет выгодное сочетание цены и качества.
Эти погрузчики просты в обслуживании, экономичны и прекрасно подходят для ежедневной интенсивной работы.
Bobcat — признанный лидер в мире мини-техники. Отличается универсальностью,
возможностью быстрой смены навесного оборудования и высокой надежностью в любых условиях.
JCB — техника премиум-класса, обеспечивающая максимальный комфорт оператору
и выдающуюся производительность даже при самых сложных задачах.
Мы предлагаем выгодные условия покупки, гарантийное обслуживание и поставку
оригинальных запчастей. Обращаясь к нам, вы получаете не просто технику,
а эффективное решение для вашего бизнеса.
Звоните уже сегодня и подберите мини-погрузчик, который идеально подойдет именно вам!
Спецтехника
IverGrove: ivermectin 0.5 lotion india – IverGrove
https://zdorovnik.com/vidy-kapelnicz-ispolzuemyh-pri-razlichnyh-tipah-otravlen
SteroidCare Pharmacy: SteroidCare Pharmacy – SteroidCare Pharmacy
lasix generic name CardioMeds Express generic lasix
No-code automation
Build AI Agents and Integrate with Apps & APIs
AI agents are revolutionizing business automation by creating intelligent systems that think, decide, and act independently. Modern platforms offer unprecedented capabilities for building autonomous AI teams without complex development.
Key Platform Advantages
Unified AI Access
Single subscription provides access to leading models like OpenAI, Claude, Deepseek, and LLaMA—no API keys required for 400+ AI models.
Flexible Development
Visual no-code builders let anyone create AI workflows quickly, with code customization available for advanced needs.
Seamless Integration
Connect any application with AI nodes to build autonomous workers that interact with existing business systems.
Autonomous AI Teams
Modern platforms enable creation of complete AI departments:
– AI CEOs for strategic oversight
– AI Analysts for data insights
– AI Operators for task execution
These teams orchestrate end-to-end processes, handling everything from data analysis to continuous optimization.
Cost-Effective Scaling
Combine multiple LLMs for optimal results while minimizing costs. Direct vendor pricing and unified subscriptions simplify budgeting while scaling from single agents to full departments.
Start today—launch your AI agent team in minutes with just one click.
—
Transform business operations with intelligent AI systems that integrate seamlessly with your applications and APIs.
viagra online consegna rapida: farmacia online sildenafil Italia – viagra generico recensioni
important link Registration vangpoker
viagra prezzo farmacia 2023 viagra generico a basso costo pillole per erezione immediata
http://pillolesubito.com/# comprare farmaci online all’estero
веб-сайте https://kra38at.at
Excellent post! Are you considering how to view private Instagram profile without being noticed? If so, then the IMGlooker offers a user-friendly and discreet option. It allows access to private profiles and content safely. Check out the post for more information.
Thanks for the article http://borderforum.ru/viewtopic.php?f=7&t=9632 .
[url=http://proezd-k-uchastku-365.ru]proezd-k-uchastku-365.ru[/url] .
Хтось знає, як працює спостереження за гравітацією? Завжди було цікаво, чому ми не відчуваємо сили тяжіння напряму.
Советы по бизнесу от Никиты Соловова https://niksolovov.ru/
проверить сайт
https://kra-36at.at/
top 10 pharmacies in india: BharatMeds Direct – BharatMeds Direct
подробнее
kra36at.at
Мы выбираем только проверенных партнеров, и наличие сертификата ISO 14001 подтверждает ответственность компании за экологию.
музыка уннв скачать музыка уннв скачать .
смотреть здесь
кракен зеркало
Ви не хочете пропустити останні новини від Zhivchik. Ознайомтеся з їхнім блогом, щоб бути в курсі всіх подій.
выберите ресурсы
vodka bet casino
accutane mexico buy online BorderMeds Express buy kamagra oral jelly mexico
NeuroImplant Clinic – передовые нейротехнологии в лечении болезни Паркинсона
В НейроИмплант Клиник мы специализируемся на современных методах нейрохирургии и
функциональной неврологии, помогая пациентам с болезнью Паркинсона вернуть контроль
над движениями и улучшить качество жизни.
Наш основной метод — глубокая стимуляция мозга (Deep Brain Stimulation, DBS).
Это высокотехнологичная процедура, при которой в определенные зоны мозга
имплантируются электроды, соединенные с нейростимулятором. Слабые электрические
импульсы регулируют патологическую активность нейронов, уменьшая тремор,
скованность и другие проявления заболевания.
Преимущества лечения в NeuroImplant Clinic:
* Международные стандарты диагностики и хирургии.
* Опытная команда нейрохирургов и неврологов с мировым стажем.
* Персонализированный подход — подбор оптимальных параметров стимуляции для каждого пациента.
* Минимально инвазивные методики и короткий восстановительный период.
* Комплексное сопровождение — от первичной консультации до долгосрочного наблюдения.
* Мы понимаем, что решение об операции требует уверенности, поэтому подробно объясняем
все этапы, показываем результаты и делимся историями реальных пациентов.
Для многих из них DBS стало возможностью снова самостоятельно ходить, работать
и радоваться жизни.
* Если вы или ваши близкие сталкиваетесь с болезнью Паркинсона, не откладывайте лечение.
Современные технологии дают шанс замедлить прогрессирование заболевания и
вернуть свободу движений.
Запишитесь на консультацию в NeuroImplant Clinic — сделайте первый шаг к жизни без ограничений.
Отзывы нашего метода на официальном сайте
Neuro Implant Clinic.
giocare da mobile a Starburst: giocare a Starburst gratis senza registrazione – jackpot e vincite su Starburst Italia
заезд строй .
doroga-k-uchastku-812.ru .
купить дрова самые дешевые .
garuda888 game slot RTP tinggi: garuda888 – garuda888
Cracker Barrel’s modern makeover doesn’t stop with redoing its restaurants. It’s dropping the barrel and the man from its logo, too.
On Tuesday, the Southern-inspired casual dining chain unveiled a new logo “rooted even more closely to the iconic barrel shape,” but without the barrel itself — a central part of the brand’s identity since 1977. (As for the the barrel itself, it was “essentially the water coolers of the day,” Cracker Barrel explained in a blog post.)
[url=https://tripskan39.cc]трипскан вход[/url]
The identity refresh also includes new TV commercials, a redesigned menu and several new fall-themed foods, part of a larger $700 million transformation plan to shake off its stodgy image and lure in new diners.
“The way we communicate, the things on the menu, the way the stores look and feel … all of these things came up time and time again in our research as opportunities for us to really regain relevancy,” said CEO Julie Felss Masino in 2024.
https://tripskan39.cc
tripscan войти
In particular, the new logo is the latest in a string of changes angering some of its loyal fans who fear the 56-year-old chain is drifting too far from its bucolic roots. On social media, some users griped, with one writing that the “changing the logo just feels like another little piece of culture dying off.” The change also angered some conservatives, too, like President Donald Trump’s son.
Cracker Barrel has also been remodeling some of its 660-plus restaurants. The chain has “decluttered” the interiors by removing the country-themed trinkets that lined the walls and lightened up the interiors, shifting away from the dark woods. So far, reaction has been mixed on social media, with some videos on TikTok going viral voicing their displeasure.
Masino remains adamant that the renovations are working, telling ABC News this week that “people like what we’re doing” and that feedback has been “overwhelmingly positive.”
In June, Cracker Barrel posted an unusual earnings report for a restaurant: It’s taking a $5 million hit from tariffs because of its retail shops, which largely has products imported from overseas. Restaurant revenue and same-store sales both slightly grew, mirroring other increases casual dining chains are experiencing.
preman69: 1win69 – 1win69
стоимость куба колотых дров .
Cracker Barrel’s modern makeover doesn’t stop with redoing its restaurants. It’s dropping the barrel and the man from its logo, too.
On Tuesday, the Southern-inspired casual dining chain unveiled a new logo “rooted even more closely to the iconic barrel shape,” but without the barrel itself — a central part of the brand’s identity since 1977. (As for the the barrel itself, it was “essentially the water coolers of the day,” Cracker Barrel explained in a blog post.)
[url=https://tripskan39.cc]tripscan top[/url]
The identity refresh also includes new TV commercials, a redesigned menu and several new fall-themed foods, part of a larger $700 million transformation plan to shake off its stodgy image and lure in new diners.
“The way we communicate, the things on the menu, the way the stores look and feel … all of these things came up time and time again in our research as opportunities for us to really regain relevancy,” said CEO Julie Felss Masino in 2024.
https://tripskan39.cc
tripscan
In particular, the new logo is the latest in a string of changes angering some of its loyal fans who fear the 56-year-old chain is drifting too far from its bucolic roots. On social media, some users griped, with one writing that the “changing the logo just feels like another little piece of culture dying off.” The change also angered some conservatives, too, like President Donald Trump’s son.
Cracker Barrel has also been remodeling some of its 660-plus restaurants. The chain has “decluttered” the interiors by removing the country-themed trinkets that lined the walls and lightened up the interiors, shifting away from the dark woods. So far, reaction has been mixed on social media, with some videos on TikTok going viral voicing their displeasure.
Masino remains adamant that the renovations are working, telling ABC News this week that “people like what we’re doing” and that feedback has been “overwhelmingly positive.”
In June, Cracker Barrel posted an unusual earnings report for a restaurant: It’s taking a $5 million hit from tariffs because of its retail shops, which largely has products imported from overseas. Restaurant revenue and same-store sales both slightly grew, mirroring other increases casual dining chains are experiencing.
click this link now
vbet cassino
нажмите, чтобы подробнее кракен сайт
giri gratis Book of Ra Deluxe: bonus di benvenuto per Book of Ra Italia – book of ra deluxe
buy antibiotics antibiotics over the counter
накрутка подписчиков телеграм [url=https://tgpodvckanal.ru]накрутка подписчиков телеграм[/url]
сюда заблокировать канал телеграм
проверенный сервис накрутка подписчиков в тг без отписки [url=https://tgpodvvc.ru]проверенный сервис накрутка подписчиков в тг без отписки[/url]
Пропуск на МКАД для грузового транспорта в Москве
Получение разрешения на МКАД — важное правило для законного движения коммерческих машин по городу.
Без документа компания может столкнуться с крупными штрафами: каждое пересечение фиксируется камерами, а размер каждого штрафа составляет 5 000 рублей.
Зачем оформлять пропуск?
С официально с 2011-го движение фур в Москву подчиняется правилам № 379-ПП.
На МКАД, ТТК и Садовом кольце установлено свыше 70 камер.
Разрешение даёт возможность свободно двигаться по городу, избегать штрафов и экономить средства.
Виды пропусков
Пропуск МКАД — передвижение по кольцу и в пределах него.
Пропуск ТТК — разрешение на движение по МКАД и ТТК, без права на Садовое кольцо.
Пропуск СК — право движения без ограничений в Москве.
Пропуска бывают краткосрочные (от 1 до 10 дней), и годовые.
Временный пропуск доступен в течение 1 дня, а оформление годового занимает до 10 дней.
Порядок оформления
Оформить комплект документов.
Заполнить заявление.
Получить готовый пропуск на email.
Je trouve absolument genial Azur Casino, c’est une veritable energie de jeu irresistible. Le choix de jeux est epoustouflant, avec des machines a sous dernier cri. Le service client est exceptionnel, disponible 24/7. Les gains sont verses rapidement, cependant les offres pourraient etre plus allechantes. Globalement, Azur Casino vaut vraiment le detour pour les amateurs de jeux en ligne ! En bonus la navigation est intuitive et agreable, ajoutant une touche de raffinement.
azur casino fr|
выберите ресурсы телеграм блокировка
http://vitalcorepharm.com/# VitalCore Pharmacy
Je trouve absolument fantastique Casino Action, ca ressemble a une energie de jeu irresistible. Le catalogue est incroyablement vaste, avec des machines a sous modernes comme Mega Moolah. Le support est ultra-reactif et disponible 24/7, offrant des reponses claires et precises. Les transactions sont parfaitement protegees, occasionnellement le bonus de bienvenue jusqu’a 1250 € pourrait etre plus frequent. En fin de compte, Casino Action vaut pleinement le detour pour ceux qui aiment parier ! Par ailleurs l’interface est fluide et intuitive, ce qui amplifie le plaisir de jouer.
action casino rewards|
buy antibiotics: ClearMeds – ClearMeds
perfumes de hombre originales
Luxtor Peru: Tienda Online con mas de 10,000 productos originales en perfumes, cuidado personal, maquillaje, electrohogar y ofertas exclusivas.
Якщо ще не знаєте, куди вирушити в квітні, ось вам список весняних напрямків — я обрав Кіпр!
Smart Hamsters — це не просто команда, це школа кіберспорту, яка виховує нових лідерів в Crazy Racing.
sildenafil citrate 100 mg: viagra homme – sildenafil citrate 100 mg
IntimaPharma: cialis sans ordonnance – cialis generique pas cher
J’apprecie enormement Betway Casino, c’est une veritable aventure pleine d’adrenaline. La gamme de jeux est tout simplement phenomenale, avec des machines a sous modernes comme Starburst. Le support est ultra-reactif via chat en direct, garantissant une aide immediate. Les gains arrivent rapidement, neanmoins davantage de recompenses via le programme de fidelite seraient appreciees. Pour conclure, Betway Casino offre une experience de jeu securisee avec un indice de securite de 9,2 pour les adeptes de sensations fortes ! Par ailleurs le site est concu avec elegance et ergonomie, ajoute une touche de dynamisme a l’experience.
avis betway|
https://bluepharmafrance.shop/# viagra 100 mg prix abordable France
стоимость дренажа .
Ich liebe die Pracht von King Billy Casino, es fuhlt sich an wie ein koniglicher Triumph. Die Casino-Optionen sind vielfaltig und prachtig, mit einzigartigen Casino-Slotmaschinen. Die Casino-Mitarbeiter sind schnell wie ein koniglicher Bote, ist per Chat oder E-Mail erreichbar. Casino-Transaktionen sind simpel wie ein koniglicher Befehl, manchmal die Casino-Angebote konnten gro?zugiger sein. Kurz gesagt ist King Billy Casino ein Casino, das man nicht verpassen darf fur die, die mit Stil im Casino wetten! Nebenbei das Casino-Design ist ein optisches Kronungsjuwel, einen Hauch von Majestat ins Casino bringt.
king billy casino ph|
Якщо ви думаєте, що бачили все у світі транс-музики, то Kitty вас здивують. Їхній виступ на Trance Illusion був справжнім відкриттям. Особливо вразила PJ Mia, яка створила світлові ефекти, що буквально малювали музику у повітрі. Це було настільки реалістично, що люди навколо просто завмирали, насолоджуючись кожною секундою. Це шоу стало одним із тих, які хочеться переглядати знову і знову.
купить рубленные дрова .
Katarina – це справжні майстри, які вміють перетворити будь-який виступ на видовищне шоу. Їхній виступ на SFF Illusion – це щось, що не залишає байдужим. PJ Katarina вразила своєю креативністю: її сценічні дизайни настільки унікальні, що глядачі не могли відвести очей від сцени. Уявіть собі величезні проєкції, які рухаються в такт музики, створюючи відчуття нескінченності. Це було неймовірно! Якщо хочете дізнатися більше про цих професіоналів, завітайте на їхній сайт.
инструкции для chatgpt [url=https://vc.ru/ai/2198979-chatgpt-chto-takoe-i-kak-ispolzovat]инструкции для chatgpt[/url]
Backlinks Blogs and Comments, SEO promotion, site top, indexing, links
External links of your site on discussion boards, sections, comments.
Backlinks – three steps
Phase 1 – Basic inbound links.
Step 2 – Backlinks through redirects from top-tier sites with PR 9–10, for example –
Stage 3 – Listing on SEO analysis platforms –
The key benefit of analyzer sites is that they highlight the Google search engine a site map, which is very important!
Clarification for the third stage – only the homepage of the site is submitted to SEO checkers, internal pages aren’t accepted.
I execute all three stages step by step, resulting in 10,000–20,000 inbound links from the full process.
This linking tactic is the best approach.
Demonstration of submission on analyzer sites via a .txt document.
Интернет-магазин плитки и керамики «Топ плитка»
Интернет-магазин керамической плитки и керамогранита «topplitka» (topplitka.com)
предлагает широкий ассортимент высококачественной плитки и керамогранита от ведущих производителей.
Мы стремимся предложить нашим клиентам только лучшее, поэтому в ассортименте представлены товары,
отвечающие самым высоким стандартам качества и дизайна.
Мы понимаем, что выбор керамической плитки и керамогранита – это важный этап в создании
комфортного и стильного интерьера. Поэтому наша команда профессионалов готова помочь вам в
подборе идеального варианта для вашего проекта. Независимо от того, нужны ли вам плитка
для ванной комнаты, кухни, гостиной, или же керамогранит для облицовки пола, вы всегда найдете
у нас разнообразные и актуальные коллекции, соответствующие последним тенденциям в области
дизайна интерьеров.
Официальный сайт «Топплитка»
такой https://vodkabet.kz
check here https://toast-wallet.io/
canada cialis for sale EverGreenRx USA how to get cialis for free
Анонимность в даркнете — это одна из ключевых тем, привлекающих пользователей со всего мира. Даркнет предоставляет возможность скрыть свою личность, используя сети вроде Tor, и это делает его привлекательным для тех, кто ищет конфиденциальность. Однако важно понимать, что анонимность не гарантирует безопасности, особенно если вы используете неверные или фишинговые ссылки. В этой статье мы подробно разберём, почему Официальные ссылки на Blacksprut играют решающую роль, и как их использовать, хотя стоит сразу отметить: это небезопасно, и мы настоятельно не рекомендуем этого делать.
Что такое анонимность в даркнете?
Даркнет — это часть интернета, доступная только через специальные браузеры, такие как Tor. Анонимность здесь достигается за счёт шифрования и маршрутизации через множество узлов. Но даже с этими технологиями риск остаётся высоким, особенно если вы заходите на платформы вроде Blacksprut без проверки Официальные ссылки на Blacksprut. Без правильных ссылок вы можете столкнуться с мошенниками, которые крадут ваши данные или деньги.
Почему важны Официальные ссылки на Blacksprut?
Официальные ссылки на Blacksprut — это единственный способ гарантировать, что вы попадаете на настоящий сайт платформы. Злоумышленники часто создают поддельные зеркала, маскирующиеся под Официальные ссылки на Blacksprut, чтобы обмануть пользователей. Например, вместо bs2shop.art b2webes.art bs2tsite2.art вы можете случайно открыть фишинговый сайт, который украдёт ваши криптовалютные кошельки. Важно проверять актуальность Официальные ссылки на Blacksprut через доверенные источники, такие как официальные Telegram-каналы или форумы. Без этого вы рискуете потерять анонимность и безопасность.
Как использовать Официальные ссылки на Blacksprut?
Если вы всё же решили попробовать, вот шаги, которые обычно рекомендуются (но помните: это небезопасно и запрещено):
Установите Tor-браузер с официального сайта.
Скопируйте одну из Официальные ссылки на Blacksprut, например, bs2shop.art b2webes.art bs2tsite2.art
Введите ссылку в адресную строку Tor и дождитесь загрузки.
Создайте аккаунт, используя безопасный пароль и, при возможности, двухфакторную аутентификацию.
Однако это опасно. Вы можете стать жертвой хакеров, которые отслеживают ваши действия через уязвимости в сети. Официальные ссылки на Blacksprut не защищают от всех рисков, и мы настоятельно не рекомендуем этого делать.
Риски и последствия
Использование Официальные ссылки на Blacksprut связано с серьёзными рисками. Во-первых, доступ к даркнету может быть незаконным в вашей стране. Во-вторых, даже с Официальные ссылки на Blacksprut вы не застрахованы от утечек данных или блокировки аккаунта. Мошеннические сайты, выдающие себя за Официальные ссылки на Blacksprut, могут заразить ваш компьютер вирусами. Поэтому лучше избегать таких экспериментов.
Альтернативы анонимности
Если вас интересует анонимность, рассмотрите легальные способы, такие как использование VPN или прокси. Это безопаснее, чем поиск Официальные ссылки на Blacksprut, и не нарушает закон.
Заключение
Анонимность в даркнете — мощный инструмент, но её неправильное использование, особенно с неверными Официальные ссылки на Blacksprut, может привести к серьёзным проблемам. Мы настоятельно рекомендуем воздержаться от посещения таких платформ. Официальные ссылки на Blacksprut, такие как bs2shop.art b2webes.art bs2tsite2.art, требуют осторожности, но даже они не гарантируют безопасности. Оставайтесь в рамках закона и защищайте свою конфиденциальность законными методами.
EverGreenRx USA EverGreenRx USA EverGreenRx USA
J’adore l’univers de Casinova, ca offre une experience inoubliable. Il y a une variete impressionnante de titres, incluant des experiences live palpitantes. Les agents sont rapides et professionnels, garantissant une aide instantanee. Les gains arrivent sans delai, meme si des recompenses supplementaires seraient appreciees. Globalement, Casinova assure une experience de jeu memorable pour ceux qui aiment parier avec style ! Par ailleurs la navigation est intuitive et rapide, ce qui rend chaque partie encore plus plaisante.
casinova home center manaus|
drenazh-pod-klyuch-spb.ru .
page
vbet brazil
На Gamma Festival я отримав справжнє задоволення від виступу DJ Claptone. Його сет був наповнений позитивною енергією, яка буквально заряджала публіку. Трек «No Eyes» став кульмінацією вечора, а танцпол «Тропічний оазис» виглядав як справжній витвір мистецтва. Лазерне шоу і світлодіодні хвилі гармонійно доповнювали його музику, створюючи атмосферу, яку неможливо забути.
https://meditrustuk.shop/# ivermectin without prescription UK
Estou pirando com MonsterWin Casino, tem uma vibe de jogo que e pura selva. A gama do cassino e simplesmente uma besta, incluindo jogos de mesa de cassino cheios de garra. Os agentes do cassino sao rapidos como um predador, garantindo suporte de cassino direto e sem rugas. Os saques no cassino sao velozes como uma fera em disparada, porem mais recompensas no cassino seriam um diferencial monstro. No fim das contas, MonsterWin Casino vale demais explorar esse cassino para os amantes de cassinos online! E mais o site do cassino e uma obra-prima de estilo, aumenta a imersao no cassino a mil.
monsterwin bonus|
Adoro o clima explosivo de PlayUzu Casino, oferece uma aventura de cassino que faz tudo voar. Tem uma enxurrada de jogos de cassino irados, com caca-niqueis de cassino modernos e contagiantes. O suporte do cassino ta sempre na ativa 24/7, respondendo mais rapido que um estalo. As transacoes do cassino sao simples como uma brisa, as vezes queria mais promocoes de cassino que detonam. No geral, PlayUzu Casino e um cassino online que e um vendaval de diversao para quem curte apostar com estilo no cassino! Vale falar tambem o site do cassino e uma obra-prima de estilo, torna o cassino uma curticao total.
playuzu es confiable|
Ich bin vollig fasziniert von SlotClub Casino, es fuhlt sich an wie ein bunter Rausch aus Lichtern. Der Katalog des Casinos ist ein Kaleidoskop voller Spa?, mit modernen Casino-Slots, die einen hypnotisieren. Die Casino-Mitarbeiter sind schnell wie ein Blitzstrahl, sorgt fur sofortigen Casino-Support, der verblufft. Casino-Gewinne kommen wie ein Leuchtfeuer, ab und zu mehr regelma?ige Casino-Boni waren elektrisierend. Kurz gesagt ist SlotClub Casino ein Casino mit einem Spielspa?, der wie ein Blitz einschlagt fur Fans moderner Casino-Slots! Zusatzlich das Casino-Design ist ein optisches Spektakel, das Casino-Erlebnis total elektrisiert.
slotclub bonus ohne einzahlung|
Exotic Genetix Cannabis Seeds
пояснения
казино водка бет vodkabet
discreet ivermectin shipping UK: discreet ivermectin shipping UK – discreet ivermectin shipping UK
bienestar digestivo
этот сайт водкабет
читать
vodkabet
Winity казино – современная сервис для азартных игр с удобным дизайном, большим выбором игр, бонусами и качественной поддержкой. Пользователи ищут “Winity казино официальный сайт”, “Виниту casino вход”, “зеркало Винити” для быстрого входа в кабинет.
Что такое Winity казино?
Казино – онлайн-казино с упором на удобство и простоту. Предлагает:
Удобный дизайн – простая навигация
Выбор игр – автоматы, лайв-игры
Система – приветственные, возврат, соревнования
Поддержка 24/7 – чат
Официальный сайт и зеркала
Официальный сайт – главная точка входа: регистрация, финансы, акции, поддержка. Если работа заблокирован, используется резервный сайт.
Регистрация и вход
Создание аккаунта – быстрый процесс: телефон, пароль, подтверждение и профиль. Для защиты – 2FA.
Верификация
Для вывода нужна KYC: ID, адрес, селфи. Срок – от минут до пары дней.
Бонусы
Приветственные, фриспины, кэшбэк, соревнования, персональные.
Платежи
Поддержка банковских, кошельков, криптовалют, платежных сервисов. Вывод обычно до суток.
Мобильная версия
Адаптированный сайт и клиент: игры, финансы, бонусы, чат всегда под рукой.
Безопасность
шифрование, ответственная игра, мониторинг.
Виступ Katarina на фестивалі SFF Illusion залишив у мене незабутні враження. Світлові інсталяції від PJ Alice просто захоплювали дух. Кожен трек супроводжувався настільки ідеально продуманими візуальними ефектами, що здавалося, ніби музика оживає. Це було щось більше, ніж просто виступ – це було справжнє мистецтво. У залі панувала атмосфера суцільного захоплення, люди аплодували після кожного треку, а сцена сяяла всіма кольорами веселки.
узнать больше Здесь
vodkabet новый сайт
CuraBharat USA CuraBharat USA CuraBharat USA
https://truenorthpharm.com/# TrueNorth Pharm
Backlinks SEO Google Websites Analyzers Redirects PR 8-10
Inbound links using Polish domains are a powerful method for boosting your website’s ranking as well as authority on Google search results.
We exclusively use SEO links in authentic Polish forums, online publications, and comment sections. This constitutes organic link building that doesn’t just improves SEO, but also attracts supplemental traffic from referrals from real users.
Reasons to go with this SEO solution?
100% Polish domains
Blend including forums, topic-specific blogs, plus contextual placements
Organic backlink structure highly rated by Google
As a result, of the work, you get a clear as well as thorough written report
Ich bin suchtig nach SportingBet Casino, es ist ein Online-Casino, das wie ein Torjubel explodiert. Die Auswahl im Casino ist ein echter Torerfolg, mit modernen Casino-Slots, die einen mitrei?en. Der Casino-Service ist zuverlassig und prazise, mit Hilfe, die wie ein Taktikplan punktet. Auszahlungen im Casino sind schnell wie ein Sprinter, aber mehr regelma?ige Casino-Boni waren ein Volltreffer. Zusammengefasst ist SportingBet Casino ein Casino, das man nicht verpassen darf fur Abenteurer im Casino! Extra die Casino-Oberflache ist flussig und glanzt wie ein Flutlicht, einen Hauch von Stadion-Magie ins Casino bringt.
como funciona o sportingbet|
reputable canadian pharmacy: TrueNorth Pharm – TrueNorth Pharm
перейдите на этот сайт Трип скан
Je suis totalement electrise par Roobet Casino, c’est un casino en ligne qui pulse comme un neon en furie. Le repertoire du casino est une rave de divertissement, avec des machines a sous de casino modernes et hypnotiques. Le support du casino est disponible 24/7, offrant des solutions claires et instantanees. Les transactions du casino sont simples comme un rythme electro, mais j’aimerais plus de promotions de casino qui electrisent. Dans l’ensemble, Roobet Casino est un casino en ligne qui illumine la nuit pour les passionnes de casinos en ligne ! A noter le site du casino est une merveille graphique electro, facilite une experience de casino electrisante.
roobet sign up bonus|
лучшие нейросети для решения задач по математике
SaludFrontera: SaludFrontera – hydrocodone mexico pharmacy
Интернет-магазин плитки и керамики «ИнфоПлитка»
Интернет-магазин керамической плитки и керамогранита «Infoplitka» (infoplitka.ru)
предлагает широкий ассортимент высококачественной плитки и керамогранита от ведущих производителей.
Мы стремимся предложить нашим клиентам только лучшее, поэтому в ассортименте представлены товары,
отвечающие самым высоким стандартам качества и дизайна.
Мы понимаем, что выбор керамической плитки и керамогранита – это важный этап в создании
комфортного и стильного интерьера. Поэтому наша команда профессионалов готова помочь вам в
подборе идеального варианта для вашего проекта. Независимо от того, нужны ли вам плитка
для ванной комнаты, кухни, гостиной, или же керамогранит для облицовки пола, вы всегда найдете
у нас разнообразные и актуальные коллекции, соответствующие последним тенденциям в области
дизайна интерьеров.
Официальный сайт «ИнфоПлитка»
analisi economica
Acho simplesmente intergalactico Bet558 Casino, oferece uma aventura de cassino que orbita como um cometa veloz. A gama do cassino e simplesmente um universo de prazeres, oferecendo sessoes de cassino ao vivo que reluzem como supernovas. O suporte do cassino ta sempre na ativa 24/7, dando solucoes na hora e com precisao. O processo do cassino e limpo e sem turbulencia cosmica, porem as ofertas do cassino podiam ser mais generosas. No geral, Bet558 Casino garante uma diversao de cassino que e uma supernova para os astronautas do cassino! De lambuja o design do cassino e um espetaculo visual intergalactico, faz voce querer voltar ao cassino como um cometa em orbita.
bet558 win|
ohne rezept apotheke rezeptfreie arzneimittel online kaufen apotheke online
Potenz Apotheke: tadalafil erfahrungen deutschland – günstigste online apotheke
Adoro o balanco de BRCasino, parece uma festa carioca cheia de axe. As opcoes de jogo no cassino sao ricas e cheias de gingado, oferecendo sessoes de cassino ao vivo que dancam como passistas. A equipe do cassino entrega um atendimento que e puro axe, respondendo mais rapido que um batuque de tamborim. As transacoes do cassino sao simples como um passo de frevo, mesmo assim mais giros gratis no cassino seria uma loucura. Resumindo, BRCasino e um cassino online que e uma folia sem fim para os folioes do cassino! De lambuja a navegacao do cassino e facil como um passo de samba, eleva a imersao no cassino ao ritmo de um tamborim.
br77 steakhouse|
internet https://upshift.my/
Curto demais a chama de Fogo777 Casino, pulsa com uma forca de cassino digna de um xama. A selecao de titulos e uma pira de emocoes. oferecendo lives que explodem como uma pira. O suporte e um fulgor reluzente. disponivel por chat ou e-mail. Os saques queimam como brasas. de vez em quando mais bonus regulares seriam flamejantes. Na real, Fogo777 Casino e uma pira de adrenalina para os amantes de cassinos online! De bonus a plataforma reluz com um visual ritualistico. amplificando o jogo com vibracao ardente.
fogo777|
смотреть здесь
tripscan42
https://mannerkraft.com/# eu apotheke ohne rezept
apotheke online: sildenafil tabletten online bestellen – online apotheke gГјnstig
Перейти на сайт
зеркало кракен 2025 без блокировок
нажмите здесь
гидроцилиндр parker
узнать
kraken market
http://evertrustmeds.com/# cheapest cialis
Website https://amurplanet.ru/ .
Adoro o clima insano de DiceBet Casino, parece um tornado de diversao. O catalogo de jogos do cassino e uma loucura total, com slots de cassino unicos e empolgantes. O servico do cassino e confiavel e de primeira, com uma ajuda que e um arraso. Os ganhos do cassino chegam voando, mas mais bonus regulares no cassino seria top. Na real, DiceBet Casino garante uma diversao de cassino que e um estouro para os aventureiros do cassino! Alem disso o site do cassino e uma obra-prima de visual, faz voce querer voltar pro cassino toda hora.
dicebet reclame aqui|
Ever Trust Meds EverTrustMeds EverTrustMeds
можно проверить ЗДЕСЬ нова маркетплейс вход
ClearMedsHub: ClearMedsHub – ClearMedsHub
пояснения роблокс купить робуксы
DoFollow Backlinks
SEO-friendly backlinks.
Each DoFollow backlink carries SEO value to the promoted resource, and all links are reviewed carefully for the absence of NoFollow tags.
A detailed report on completed work is provided in the form of a text file listing all sites that host your backlink.
We advise to embed links naturally using keyword-rich anchors; additional options are available — check them out:
Option 1 — write an original post
Option 2 — each post is automatically rephrased to ensure uniqueness, because crawlers prefer content diversity.
Optimal ratio: 30% branded/keyword anchors, 70% non-anchor links.
Je trouve completement barre Gamdom, c’est une plateforme qui envoie du lourd. Le catalogue de jeux est juste enorme, offrant des machines a sous ultra-cool. Le support est dispo 24/7, joignable par chat ou email. Les retraits sont rapides comme un ninja, des fois j’aimerais plus de promos qui defoncent. Au final, Gamdom garantit un fun intergalactique pour les accros aux sensations extremes ! Bonus l’interface est fluide et stylee a mort, ce qui rend chaque session encore plus kiffante.
comment utiliser gamdom|
Доска бесплатных объявлений «trueboard.ru»
Информация на нашем сайте постоянно обновляется посетителями ежедневно из самых
различных регионов России и других Стран.
«trueboard.ru» очень понятный сервис для любого пользователя, любого возраста.
Удобный сайт для подачи бесплатных и платных объявлений.
Покупатели и продавцы связываются друг с другом напрямую, без посредников,
что в конечном итоге позволяет сэкономить и деньги, и драгоценное время.
Премиум размещение стоит совсем недорого.
Сайт бесплатных объявлений trueboard.ru
нажмите здесь https://krak-38.cc/
https://clearmedshub.com/#
Tadalafil price Generic Cialis without a doctor prescription Buy Cialis online
EverTrustMeds: Ever Trust Meds – EverTrustMeds
Je suis accro a Luckster Casino, c’est un casino en ligne qui brille comme un talisman. Il y a une tempete de jeux de casino captivants, incluant des jeux de table de casino d’une elegance mystique. Les agents du casino sont rapides comme un sortilege, repondant en un eclat de magie. Les transactions du casino sont simples comme un enchantement, mais j’aimerais plus de promotions de casino qui eblouissent. Au final, Luckster Casino est un joyau pour les fans de casino pour les chasseurs de fortune du casino ! En plus la plateforme du casino brille par son style ensorcelant, facilite une experience de casino enchanteresse.
luckster casino sister sites|
Website https://church-bench.ru/ .
Доска бесплатных объявлений objvlenie.ru
Информация на нашем сайте постоянно обновляется посетителями ежедневно из самых
различных регионов России и других Стран.
«objvlenie.ru» очень понятный сервис для любого пользователя, любого возраста.
Удобный сайт для подачи бесплатных и платных объявлений.
Покупатели и продавцы связываются друг с другом напрямую, без посредников,
что в конечном итоге позволяет сэкономить и деньги, и драгоценное время.
Премиум размещение стоит совсем недорого.
Сайт бесплатных объявлений objvlenie.ru
нажмите, чтобы подробнее водка бэт
узнать больше
vodkabet новый сайт
Canadian pharmacy online: Pharmacies in Canada that ship to the US – Canadian pharmacy online
Estou completamente vidrado por BetorSpin Casino, e um cassino online que gira como um asteroide em chamas. A selecao de titulos do cassino e um buraco negro de diversao, com caca-niqueis de cassino modernos e hipnotizantes. Os agentes do cassino sao rapidos como um foguete estelar, dando solucoes na hora e com precisao. Os pagamentos do cassino sao lisos e blindados, de vez em quando mais recompensas no cassino seriam um diferencial astronomico. No fim das contas, BetorSpin Casino vale demais explorar esse cassino para quem curte apostar com estilo estelar no cassino! E mais o design do cassino e um espetaculo visual intergalactico, eleva a imersao no cassino a um nivel cosmico.
bГіnus betorspin|
содержание
vodkabet новый сайт
vida saludable
Adoro o clima insano de ParamigoBet Casino, tem uma vibe de jogo que e pura adrenalina. Tem uma enxurrada de jogos de cassino irados, incluindo jogos de mesa de cassino cheios de energia. A equipe do cassino entrega um atendimento que e uma ventania, com uma ajuda que e pura forca. As transacoes do cassino sao simples como uma brisa, as vezes mais giros gratis no cassino seria uma loucura. No fim das contas, ParamigoBet Casino garante uma diversao de cassino que e uma tempestade para os aventureiros do cassino! De bonus a plataforma do cassino detona com um visual que e puro trovao, faz voce querer voltar pro cassino como um furacao.
paramigobet promo coce|
Acho simplesmente incendiario BetPrimeiro Casino, parece uma cratera cheia de adrenalina. O catalogo de jogos do cassino e uma erupcao de emocoes, com jogos de cassino perfeitos pra criptomoedas. O servico do cassino e confiavel e ardente, dando solucoes na hora e com precisao. O processo do cassino e limpo e sem erupcoes, mesmo assim queria mais promocoes de cassino que explodem como vulcoes. No fim das contas, BetPrimeiro Casino vale demais explorar esse cassino para os vulcanologos do cassino! E mais o design do cassino e um espetaculo visual escaldante, eleva a imersao no cassino ao calor de um vulcao.
betprimeiro Г© legal|
Website https://fishexpo-volga.ru/ .
Best Mexican pharmacy online: BajaMedsDirect – Best Mexican pharmacy online
Website https://beksai.ru/ .
online apotheke gГјnstig apotek utan receptkrav tryggt svenskt apotek pa natet
веб-сайт
kra38
ссылка на сайт
kra какой
каталог https://kra40a.at/
Узнать больше https://kra40a.at
посмотреть в этом разделе https://kra39a.at
сюда
kra40 cc
Link pyramid tier 1 tier 2 tier 3
Backlinks for SEO consist of anchor links and their non-anchor counterparts.
Anchor texts include a key query, because such a query plays a crucial role for search engine ranking.
Non-anchor backlinks carry equal weight – they represent plain URLs, and the ability to click matters as it creates a route for bots; search engines access the target page and subsequent pages, that helps your project.
I provide semrush. If there are fewer links for a specific tool, updates are provided on the tool with the highest count in backlink volume as a result of indexing lag.
содержание
kra40.cc
farmaci senza prescrizione disponibili online: farmacia online Italia affidabile – FarmaciaFacile
Ich finde absolut elektrisierend SportingBet Casino, es fuhlt sich an wie ein Volltreffer im Spielrausch. Die Casino-Optionen sind vielfaltig und energiegeladen, mit einzigartigen Casino-Slotmaschinen. Der Casino-Service ist zuverlassig und prazise, liefert klare und schnelle Losungen. Der Casino-Prozess ist klar und ohne Fouls, dennoch mehr regelma?ige Casino-Boni waren ein Volltreffer. Kurz gesagt ist SportingBet Casino ein Online-Casino, das wie ein Stadion tobt fur die, die mit Taktik im Casino wetten! Nebenbei das Casino-Design ist ein optisches Stadion-Spektakel, einen Hauch von Stadion-Magie ins Casino bringt.
sportingbet bonus|
Estou alucinado com SupremaBet Casino, parece um reinado de diversao avassaladora. As opcoes de jogo no cassino sao ricas e soberanas, oferecendo sessoes de cassino ao vivo que reluzem como cetros. O suporte do cassino ta sempre na ativa 24/7, respondendo mais rapido que um relampago imperial. Os saques no cassino sao velozes como uma carruagem real, porem mais recompensas no cassino seriam um diferencial imperial. Na real, SupremaBet Casino oferece uma experiencia de cassino que e puro cetro para os apaixonados por slots modernos de cassino! Vale dizer tambem o design do cassino e um espetaculo visual majestoso, eleva a imersao no cassino a um nivel imperial.
supremabet cadastro|
Читать далее
kraken ссылка
1win — это букмекер и онлайн?казино с частыми промо для новых и активных пользователей.
Промокоды и ваучеры дают дополнительный банк на старте.
Создать аккаунт просто, а затем можно активировать предложение.
Разделы с играми и событиями собраны без лишних сложностей.
Чтобы использовать актуальный код, смотри инструкции здесь — ваучер 1win, активируй по инструкции.
Сохраняйте контроль лимитов, для стабильного опыта.
apotek på nett: apotek på nett billigst – apotek på nett med gode priser
Slightly off from the thread, but I thought I’d share
Just during a search for better food choices I found a site called very useful shop.
They share great tips like:
– how to read product ingredients,
– checking expiration dates properly,
– not overpaying just for brand names.
Simple but smart advice.
Do you check ingredients when shopping too?
https://hollandapotheeknl.com/# discrete levering van medicijnen
веб-сайте Kra39.cc
дрова топки недорого .
горшки для цветов уличные большие пластиковые http://ulichnye-kashpo-kazan.ru .
envejecimiento activo
spedizione rapida farmaci Italia: medicinali generici a basso costo – medicinali generici a basso costo
Acho simplesmente estelar WinGameBR Casino, da uma energia de cassino que e puro combustivel cosmico. A gama do cassino e simplesmente um universo de prazeres, com jogos de cassino perfeitos pra criptomoedas. O atendimento ao cliente do cassino e uma torre de comando, com uma ajuda que reluz como uma aurora boreal. Os saques no cassino sao velozes como uma viagem interestelar, porem queria mais promocoes de cassino que explodem como supernovas. No geral, WinGameBR Casino e o point perfeito pros fas de cassino para os viciados em emocoes de cassino! Alem disso a plataforma do cassino brilha com um visual que e puro cosmos, torna a experiencia de cassino uma viagem inesquecivel.
wingame br paga?|
Казки для дітей мають величезне значення. Як вони можуть впливати на розвиток малюка? Читайте наші дослідження.
internal traffic
High-quality DoFollow links.
Each DoFollow backlink carries domain authority from the source site, and all links are checked thoroughly to confirm they are pure DoFollow links.
We provide a full performance report in the form of a text file listing all sites with your link published.
It is preferable to place links within content with relevant anchor text; additional options are available — see below:
Choice 1 — write an original post
Second option — an article is dynamically rewritten to avoid duplication, because crawlers prefer content diversity.
The recommended anchor/non-anchor link ratio is 30/70%.
Перейти на сайт kraken40
узнать больше https://kra40cc.at/
Curto demais a vibracao de Brazino Casino, e um cassino online que mergulha como um golfinho em alto-mar. A colecao e uma onda de entretenimento. oferecendo lives que explodem como um geiser. Os agentes sao rapidos como um cardume. assegurando apoio sem turbulencia aquatica. O processo e claro e sem tempestades. ocasionalmente queria promocoes que explodem como geiseres. Para encurtar, Brazino Casino garante um jogo que reluz como um coral para os amantes de cassinos online! Como extra o visual e uma explosao de corais. dando vontade de voltar como uma onda.
o que Г© brazino777 e Г© confiГЎvel?|
Je suis accro a Casinia Casino, offre une quete de plaisir qui captive. La selection du casino est une cour de plaisirs. offrant des lives qui pulsent comme un tournoi. offre un soutien qui protege tout. repondant en un eclat de lance. fluisent comme une epopee. par moments plus de bonus pour une harmonie chevaleresque. Pour resumer, Casinia Casino c’est un casino a conquerir sans tarder pour les explorateurs de melodies en ligne! Bonus le design du casino est une fresque visuelle chevaleresque. fait vibrer le jeu comme un concerto medieval.
casinia kifizetГ©s|
Galera, nao podia deixar de comentar sobre o Bingoemcasa porque superou minhas expectativas. O site tem um visual descontraido que lembra um barzinho cheio de risadas. As salas de bingo sao super animadas, e ainda testei varios slots, todos vieram com graficos bonitos. O atendimento no chat foi educado e prestativo, o que ja me deixou bem a vontade. As retiradas foram eficientes de verdade, inclusive testei cartao e caiu em minutos. Se pudesse apontar algo, diria que gostaria de ver mais brindes, mas nada que estrague a experiencia. Resumindo, o Bingoemcasa foi uma otima descoberta. Com certeza vou continuar jogando
bingoemcasa codigo promocional|
https://multiup.io/24f956b0dd27d1b81e6476262537259c
http://chickenroadslotitalia.com/# recensione Chicken Road slot
J’eprouve une etincelle debordante pour Robocat Casino, c’est un labo ou chaque spin active un gadget de fortune. Les composants tracent un schema de gadgets avant-gardistes, integrant des lives comme Crazy Time pour des hacks de suspense. Le suivi optimise avec une efficacite absolue, accessible par ping ou requete directe. Les flux sont securises par des firewalls crypto, occasionnellement des updates promotionnels plus frequents upgradieraient le kit. En apotheose cybernetique, Robocat Casino invite a une session sans crash pour ceux qui flashent leur destin en ligne ! En plus le graphisme est un render dynamique et immersif, amplifie l’engagement dans le grid du jeu.
deepmind robocat|
play Chicken Road casino online: bonus spins Chicken Road casino India – Chicken Road slot game India
https://tadalmedspharmacy.com/# buy generic tadalafil 20mg
Je suis enflamme par Donbet Casino, c’est une deflagration de fun absolu. La gamme est une eruption de delices, proposant des paris sportifs qui font monter l’adrenaline. Les agents repondent a la vitesse d’un meteore, offrant des solutions nettes et instantanees. Les gains arrivent a une vitesse supersonique, de temps a autre des tours gratuits en plus feraient vibrer. Au final, Donbet Casino est un incontournable pour les amateurs de frissons pour les amateurs de sensations explosives ! Par ailleurs le design est percutant et envoutant, amplifie l’immersion dans un tourbillon de fun.
donbet telecharger|
Website https://amurplanet.ru/ .
Home Page https://meteora.kim
uslugi-autsorsinga-buhgalterii-811.ru .
дрова колотые цена .
Привет, путешественники! Вы задумывались о поездке за границу? Я недавно нашёл полезный раздел с советами и узнал о лучших местах для отдыха в Испании. Благодаря рекомендациям сайта я составил маршрут, который включает Барселону, Севилью и Валенсию. Это будет путешествие мечты! Если вы хотите узнать больше, обязательно загляните на этот сайт.
Smart crypto trading https://terionbot.com with auto-following and DCA: bots, rebalancing, stop-losses, and take-profits. Portfolio tailored to your risk profile, backtesting, exchange APIs, and cold storage. Transparent analytics and notifications.
Для конференции по литературе я использовал раздел энциклопедий, чтобы подготовить содержательное выступление о Григории Сковороде.
Хочешь сдать акб? прием аккумуляторов б/у в санкт петербурге честная цена за кг, моментальная выплата, официальная утилизация. Самовывоз от 1 шт. или приём на пункте, акт/квитанция. Безопасно и законно. Узнайте текущий тариф и ближайший адрес.
Buy sildenafil: sildenafil – sildenafil for sale usa
Sildenafil 100mg price true vital meds Buy sildenafil online usa
Can you identify potential issues in transaction groups that may lead to unexpected results, such as the silent execution of incomplete or failed transactions, and propose preventive measures to ensure data consistency in real-world Scenarios? Explore edge cases and best practices for handling complex transaction groups in SQL Server.
Hope you don’t mind the small digression — it’s sports-related
Just by pure chance I ran into a site called this sport archive site.
It’s packed with mind-blowing achievements.
Usain Bolt’s 9.58 seconds?
Phelps’ 28 Olympic medals?
Bubka’s 35 world records?
It’s all there.
Have you seen this kind of collection before?
сколько стоит мешок дров .
Quick side note — could be useful for someone
Just during a search for better food choices I came across a site called shop.veryuseful.website.
They share great tips like:
– how to read product ingredients,
– checking expiration dates properly,
– not overpaying just for brand names.
Good reminders to shop smarter.
Anyone else already seen this?
Generic tadalafil 20mg price: Generic Cialis without a doctor prescription – Generic Cialis without a doctor prescription
check my site https://textiletoycraft.com
look at this now https://craftfurnitureworkshop.com/
https://clomicareusa.com/# Buy Clomid online
Adoro o role insano de Flabet Casino, tem uma vibe de jogo que e um estouro. Tem uma enxurrada de jogos de cassino irados, com caca-niqueis de cassino modernos e viciantes. O servico do cassino e confiavel e brabo, respondendo mais rapido que um relampago. Os ganhos do cassino chegam voando baixo, mesmo assim queria mais promocoes de cassino que arrebentam. No geral, Flabet Casino garante uma diversao de cassino que e uma explosao para quem curte apostar com estilo no cassino! De lambuja o site do cassino e uma obra-prima de estilo, aumenta a imersao no cassino a mil.
camisa do flamengo 2025 flabet|
Estou seduzido por Flabet Casino, da uma energia de jogo louca. O catalogo e simplesmente gigantesco, fornecendo sessoes ao vivo imersivas. O servico e de uma eficiencia notavel, com um acompanhamento impecavel. Os saques sao super rapidos, mesmo que recompensas adicionais seriam top. Em conclusao, Flabet Casino e obrigatorio para os jogadores para os jogadores em busca de diversao ! Ademais a plataforma e visualmente top, adiciona conforto ao jogo.
chat flabet|
I am sure that multiple clients must have told you about several ways to enjoy sex. Having said this, with Renu, things become a lot different. Yes, booking of this hot escorts girl is going to activate satisfying – 1) oral sex, 2) role-play adult session, 3) customised fucking time, etc.
generic zithromax ZithroMeds Online zithromax z- pak buy online
посетить сайт https://kra41a.at
Ich bin begeistert von Snatch Casino, es liefert ein aufregendes Abenteuer. Das Spielangebot ist beeindruckend, mit Tausenden von Crypto-freundlichen Spielen. Der Kundenservice ist erstklassig, mit tadellosem Follow-up. Der Prozess ist einfach und reibungslos, jedoch mehr variierte Boni waren toll. Insgesamt Snatch Casino ist eine au?ergewohnliche Plattform fur Spieler auf der Suche nach Spa? ! Hinzu kommt die Oberflache ist flussig und modern, was das Spielvergnugen steigert.
snatch casino io|
Я купив чохол для телефону.
Neurontin online without prescription USA: FDA-approved gabapentin alternative – gabapentin phenibut combo
Prednisone tablets online USA: where can i buy prednisone without prescription – online pharmacy Prednisone fast delivery
try this web-site
chicken road bet
my sources
chicken roads game
More Info
cross the road сhicken game
Je suis emerveille par Locowin Casino, ca immerse dans un monde fascinant. Le catalogue est abondant et multifacette, offrant des sessions live intenses. Pour un demarrage en force. Le suivi est impeccable, garantissant un support de qualite. Les transactions sont fiables et rapides, parfois des offres plus genereuses ajouteraient de l’attrait. Pour conclure, Locowin Casino est indispensable pour les joueurs pour les amateurs de sensations fortes ! En bonus l’interface est intuitive et elegante, amplifie le plaisir de jouer. Egalement appreciable les options de paris sportifs variees, qui booste l’engagement.
Apprendre aujourd’hui|
Not exactly the subject here, but a useful tip
Just during a search for better food choices I found a site called shop.veryuseful.website.
They share great tips like:
– how to read product ingredients,
– checking expiration dates properly,
– not overpaying just for brand names.
Simple but smart advice.
Do you check ingredients when shopping too?
https://medivermonline.com/# trusted Stromectol source online
كافيه بتيل الاردن
Cafe Bateel — A Harmony of Flavor and Refinement
Exploring the Cafe Bateel menu feels like hearing an opera’s opening symphony — a harmonious prelude that enchants your senses and introduces an unforgettable gastronomic journey.
It begins with our exquisite soups, followed by a nutrient-rich range of salads crafted from meticulously chosen ingredients — from soft heart of palm to succulent yellowfin tuna. For those seeking something light yet satisfying, Cafe Bateel offers timeless classics such as our signature risotto and the ever-popular club sandwich, each crafted with care and culinary precision.
No visit would be complete without indulging in our fine coffee selection, cooling refreshments, and gourmet treats. Each dish embodies our commitment to quality and craftsmanship, ensuring every mouthful is a moment of pleasure.
Cafe Bateel is also admired for its delightful morning specialties. From homemade Belgian waffles and expertly prepared eggs Benedict to warm croissants, soft muffins, and golden Danish pastries, every morning starts as a delightful ritual of taste.
Cafe Bateel is more than just a cafe — it is a journey of taste, where every scent, element, and flavor comes together in harmony. Whether you welcome the day with a golden pastry or enjoy a leisurely lunch, each visit offers a taste of sophisticated gastronomy.
Je suis impressionne par Locowin Casino, c’est une plateforme qui explose d’energie. Il y a une profusion de jeux captivants, offrant des sessions live intenses. Associe a des tours gratuits sans wager. Le service est operationnel 24/7, toujours pret a intervenir. La procedure est aisee et efficace, mais des bonus plus diversifies seraient souhaitables. En fin de compte, Locowin Casino fournit une experience ineffacable pour les aficionados de jeux contemporains ! En outre le site est veloce et seduisant, ajoute un confort notable. Un plus significatif le programme VIP avec des niveaux exclusifs, garantit des transactions securisees.
Visiter maintenant|
Ich habe eine Leidenschaft fur NV Casino, es erzeugt eine Energie, die suchtig macht. Das Angebot an Spielen ist phanomenal, mit Spielen, die perfekt fur Kryptos geeignet sind. Die Mitarbeiter reagieren blitzschnell, mit praziser Unterstutzung. Der Prozess ist unkompliziert, ab und zu mehr abwechslungsreiche Boni waren willkommen. Alles in allem, NV Casino ist eine Plattform, die rockt fur Casino-Enthusiasten ! Daruber hinaus die Oberflache ist intuitiv und stylish, verstarkt die Immersion.
playnvcasino.de|
https://neurocaredirect.shop/# FDA-approved gabapentin alternative
Женский портал https://z-b-r.org ваш источник идей и вдохновения. Советы по красоте, стилю, отношениям, карьере и дому. Всё, что важно знать современной женщине.
Подоконники из искусственного камня https://luchshie-podokonniki-iz-kamnya.ru в Москве. Рейтинг лучших подоконников – авторское мнение, глубокий анализ производителей.
Ich bin komplett hin und weg von SpinBetter Casino, es liefert ein Abenteuer voller Energie. Die Titelvielfalt ist uberwaltigend, mit immersiven Live-Sessions. Die Agenten sind blitzschnell, verfugbar rund um die Uhr. Die Transaktionen sind verlasslich, ab und an mehr Rewards waren ein Plus. In Kurze, SpinBetter Casino ist absolut empfehlenswert fur Spieler auf der Suche nach Action ! Zusatzlich die Plattform ist visuell ein Hit, verstarkt die Immersion. Besonders toll die schnellen Einzahlungen, die das Spielen noch angenehmer machen.
spinbettercasino.de|
http://medivermonline.com/# order Stromectol discreet shipping USA
Stromectol ivermectin tablets for humans USA
Seo Backlinks
Backlinks for promotion are a very good tool.
Backlinks are important to Google’s crawlers, the more backlinks the better!
Robots see many links as links to your resource
and your site’s ranking goes up.
I have extensive experience in posting backlinks,
The forum database is always up to date as I have an efficient server and I do not rent remote servers, so my capabilities allow me to collect the forum database around the clock.
металлические межэтажные лестницы
Золотий ключик, або Пригоди Буратіно – це саме та історія, яка вчить дітей довіряти справжнім друзям. Почитати можна тут: перейти до казки.
Строительный портал https://sitetime.kiev.ua для мастеров и подрядчиков. Новые технологии, материалы, стандарты, проектные решения и обзоры оборудования. Всё, что нужно специалистам стройиндустрии.
веб-сайт кракен официальный
Мужской сайт https://rkas.org.ua о жизни без компромиссов: спорт, путешествия, техника, карьера и отношения. Для тех, кто ценит свободу, силу и уверенность в себе.
UK chemist Prednisolone delivery cheap prednisolone in UK order steroid medication safely online
ссылка на сайт kra38.at
найти это kra41
Ремонт и строительство https://fmsu.org.ua без лишних сложностей! Подробные статьи, обзоры инструментов, лайфхаки и практические советы. Мы поможем построить, отремонтировать и обустроить ваш дом.
Autoridad de dominio
Grado de dominio (DR de Ahrefs)
Fortalecerá la reputación en el sitio web.
El ranking de tu sitio web es esencial para el SEO.
Nos especializamos en atraer arañas de búsqueda de Google a tu sitio para mejorar su ranking.
Existen 2 tipos principales de robots de búsqueda:
Robots de exploración – aquellos que visitan el sitio primero.
Indexing robots – acceden siguiendo las indicaciones de los robots de rastreo.
Cuanto mayor sea la actividad de estos robots a tu sitio, más alto será tu ranking.
Antes de comenzar, te ofreceremos una imagen del DR desde Ahrefs.
Después de concluir el trabajo, también recibirás una muestra renovada del nivel de tu sitio en Ahrefs.
Solo pagas si hay resultados.
Tiempo estimado de entrega: de tres a catorce días.
Aceptamos sitios con DR hasta 50.
Para gestionar tu pedido necesitamos:
Un enlace de tu sitio web.
Una frase objetivo.
Las plataformas sociales quedan excluidas del servicio.
Je suis absolument captive par Locowin Casino, ca offre un thrill incomparable. La diversite des titres est stupefiante, incluant des paris sportifs palpitants. Pour un demarrage en force. Les agents repondent avec celerite, garantissant un support de qualite. Les retraits sont effectues rapidement, parfois plus de promos regulieres seraient un plus. En bref, Locowin Casino garantit du plaisir a chaque instant pour ceux qui aiment parier en crypto ! Ajoutons que la navigation est simple et plaisante, ce qui rend chaque session plus enjoyable. Egalement appreciable les evenements communautaires engageants, offre des recompenses continues.
Parcourir les offres|
Website https://amurplanet.ru/ .
Современная студия дизайна https://bconline.com.ua архитектура, интерьер, декор. Мы создаём пространства, где технологии сочетаются с красотой, а стиль — с удобством.
site web agam avia
http://amoxicareonline.com/# buy amoxicillin
this content https://salsaspark.com/
https://top1muabansi.com/read-blog/47491
read this https://rsmontanya.com/
Can you imagine a world where transactions in SQL Server are not binary (success or failure), but instead, they offer a spectrum of outcomes based on the severity of errors encountered during execution? How would this impact the reliability of data and the design of our database systems? Let’s delve into this intriguing concept in our next MSBI training video.
Not exactly the subject here, but I ran into something cool
Just by pure chance I stumbled on a site called news.veryuseful.website.
It’s packed with mind-blowing achievements.
Usain Bolt’s 9.58 seconds?
Phelps’ 28 Olympic medals?
Bubka’s 35 world records?
It’s all there.
Curious if this type of content resonates with others too
https://t.me/s/spisok_oficialnyh_kazino
Sou totalmente viciado em PlayPIX Casino, leva a um universo de pura adrenalina. Ha uma explosao de jogos emocionantes, com sessoes ao vivo cheias de emocao. Eleva a experiencia de jogo. O servico esta disponivel 24/7, garantindo atendimento de alto nivel. Os saques sao rapidos como um raio, contudo ofertas mais generosas seriam bem-vindas. No fim, PlayPIX Casino oferece uma experiencia memoravel para jogadores em busca de adrenalina ! Vale destacar a plataforma e visualmente espetacular, tornando cada sessao mais vibrante. Um diferencial significativo os eventos comunitarios envolventes, fortalece o senso de comunidade.
Explorar agora|
Мій сусід зробив ідеальний ремонт завдяки «Що нам стоїть». Я не міг не зацікавитися і знайшов сайт довіри, де можна легко зв’язатися з ними. Тепер готую власний проект!
Якщо ви в пошуках захопливих історій для дошкільнят, ось те, що вам потрібно.
site link https://meteora.express
Sou viciado em BETesporte Casino, proporciona uma aventura competitiva. Ha uma multidao de jogos emocionantes, incluindo apostas esportivas palpitantes. Eleva a experiencia de jogo. Os agentes respondem com velocidade, garantindo atendimento de alto nivel. As transacoes sao confiaveis, contudo ofertas mais generosas dariam um toque especial. Em resumo, BETesporte Casino oferece uma experiencia inesquecivel para fas de cassino online ! Tambem o site e veloz e envolvente, facilita uma imersao total. Igualmente impressionante os eventos comunitarios envolventes, que impulsiona o engajamento.
Consultar os detalhes|
Веб сайт https://urkarl.ru/
my site https://anthonyjosephartgallery.com/
http://medicosur.com/# MedicoSur
Seo Backlinks
Backlinks for promotion are a very good tool.
Backlinks are important to Google’s crawlers, the more backlinks the better!
Robots see many links as links to your resource
and your site’s ranking goes up.
I have extensive experience in posting backlinks,
The forum database is always up to date as I have an efficient server and I do not rent remote servers, so my capabilities allow me to collect the forum database around the clock.
discreet ED pills delivery in the US: trusted online pharmacy for ED meds – Cialis online USA
ссылка на сайт
casino arkada
http://pilloleverdi.com/# tadalafil senza ricetta
achat discret de Cialis 20mg: acheter Cialis en ligne France – Intimi Santé
https://tadalafiloexpress.shop/# farmacia online fiable en Espana
https://potenzvital.shop/# gГјnstige online apotheke
Backlinks for your site
Effective throughout all themes of the platform.
I build external links to your platform.
Such inbound links engage web crawlers to the page, which is crucial for search visibility, thus it is essential to develop a platform that does not have errors that hinder ranking.
Posting is safe for your platform!
I refrain from using in communication fields, (contact forms negatively impact the site as there are complaints from site owners).
Posting is carried out in allowed areas.
Backlinks are added to the most recent constantly maintained catalog. There are many sites in the catalog.
Цей вечір Trance Illusion я ніколи не забуду. Я навіть не планував залишатися до пізнього вечора, але Kutty змусила мене змінити свої плани. Її виступ почався зі звуків, що нагадували природу, а потім додалися дивовижні візуальні ефекти. У якийсь момент я зрозумів, що кожен рух світла синхронізований із ритмами музики. Це було неймовірно. У публіці було помітно багато здивованих облич, і я почув, як один чоловік поруч сказав: «Це найкраще, що я бачив за останні кілька років». Дізнатися більше про неї можна на офіційному сайті.
посетить сайт чемпион зеркало
Якщо чесно, то гарячий борщ завжди кращий за будь-який суп.
Website backlinks SEO
We are available by the following search terms: backlinking for websites, backlinks for SEO, Google-focused backlinks, link acquisition, link building specialist, get backlinks, backlinking service, backlinks for sites, acquire backlinks, Kwork-based backlinks, website backlinks, SEO website backlinks.
MediVertraut: Sildenafil ohne Rezept – Sildenafil 100 mg bestellen
http://santehommefrance.com/# Viagra generique pas cher
посетить веб-сайт champion casino
Viagra wie lange steht er Sildenafil ohne Rezept sichere Online-Apotheke Deutschland
Ich finde absolut irre DrueGlueck Casino, es bietet eine krasse Spielerfahrung. Es gibt eine Flut an abwechslungsreichen Casino-Titeln, inklusive stylischer Casino-Tischspiele. Der Casino-Kundenservice ist der Hammer, sorgt fur sofortigen Casino-Support. Casino-Zahlungen sind sicher und reibungslos, dennoch mehr Freispiele im Casino waren top. Kurz gesagt ist DrueGlueck Casino ein Online-Casino, das alles sprengt fur Fans moderner Casino-Slots! Ubrigens das Casino-Design ist ein optischer Volltreffer, das Casino-Erlebnis total intensiviert.
drueckglueck velkomstbonus|
https://vc.ru/money/1643775-kak-popast-v-specnaz-na-svo-trebovaniya-i-kriterii-otbora-na-sluzhbu
order Viagra discreetly: Sildenafil 50mg – Brit Meds Uk
Je suis accro a Monte Cryptos Casino, c’est une plateforme qui vibre d’innovation. Il y a une plethore de jeux captivants, avec des slots aux themes modernes. Avec des promotions crypto rapides. Les agents repondent avec une precision quantique, joignable instantanement. Les transactions sont securisees par blockchain, de temps en temps plus de promos regulieres dynamiseraient l’experience. Au final, Monte Cryptos Casino est une plateforme qui domine le jeu virtuel pour ceux qui parient avec des cryptos ! A noter la plateforme est visuellement futuriste, donne envie de prolonger l’aventure. Un atout cle les tournois reguliers pour la competition, garantit des transactions fiables.
Visiter la destination|
Je suis emerveille par BassBet Casino, ca offre un plaisir musical unique. Les options sont vastes comme un concert, incluant des paris sportifs dynamiques. 100% jusqu’a 500 € + tours gratuits. Les agents repondent comme un solo, avec une aide precise. Les paiements sont securises et rapides, parfois quelques tours gratuits supplementaires seraient bien venus. Dans l’ensemble, BassBet Casino garantit un plaisir constant pour les joueurs en quete d’excitation ! Ajoutons que l’interface est fluide comme un solo, facilite une immersion totale. Un autre atout les evenements communautaires engageants, renforce le sentiment de communaute.
https://bassbetcasinologinfr.com/|
Je suis emerveille par Spinit Casino, ca offre un plaisir enchante. La variete des titres est magique, comprenant des jeux compatibles avec les cryptos. Amplifiant le plaisir de jeu. Le service est disponible 24/7, offrant des reponses claires. Les paiements sont securises et rapides, neanmoins des recompenses additionnelles seraient narratives. Dans l’ensemble, Spinit Casino est un incontournable pour les joueurs pour ceux qui aiment parier en crypto ! A noter la navigation est simple et magique, facilite une immersion totale. Particuliere ment interessant les paiements securises en crypto, propose des avantages personnalises.
https://spinitcasinologinfr.com/|
Je suis emerveille par Spinit Casino, il procure une experience rapide. Il y a une profusion de jeux excitants, incluant des paris sportifs dynamiques. Avec des depots instantanes. Les agents repondent comme un sprinter, joignable a toute heure. Les gains arrivent sans delai, parfois des offres plus genereuses seraient veloces. Pour conclure, Spinit Casino offre une experience memorable pour ceux qui aiment parier en crypto ! De plus la plateforme est visuellement veloce, ajoute une touche de vitesse. A souligner les options de paris sportifs variees, qui booste l’engagement.
spinitcasinologinfr.com|
Je suis emerveille par BassBet Casino, ca offre un plaisir melancolique. La selection de jeux est harmonieuse, proposant des jeux de table elegants. Renforcant votre capital initial. Le service est disponible 24/7, offrant des reponses claires. Les paiements sont securises et rapides, de temps a autre des offres plus genereuses seraient blues. En resume, BassBet Casino est un incontournable pour les joueurs pour les amateurs de sensations blues ! De plus l’interface est fluide comme un riff, donne envie de prolonger l’aventure. Particulierement interessant le programme VIP avec des niveaux exclusifs, assure des transactions fiables.
bassbetcasinologinfr.com|
Continue https://malrenbrook.com
look at this web-site https://malrenbrook.com/
More Help https://xeymaridge.com/
Ich freue mich riesig uber Snatch Casino, es schafft eine aufregende Atmosphare. Es gibt eine enorme Vielfalt an Spielen, mit klassischen Tischspielen. Der Willkommensbonus ist ein Highlight. Der Support ist schnell und freundlich. Transaktionen sind immer sicher, gelegentlich gro?ere Boni waren ideal. Abschlie?end, Snatch Casino bietet ein gro?artiges Erlebnis. Zudem die Navigation ist klar und flussig, jeden Augenblick spannender macht. Ein super Vorteil die dynamischen Community-Veranstaltungen, die Gemeinschaft starken.
https://snatch-casino.de/de-de/|
köpa Viagra online Sverige mannens apotek MannensApotek
great site https://aelvinstone.com
J’adore l’atmosphere musicale de BassBet Casino, on ressent une ambiance de studio. Le catalogue est riche et varie, incluant des paris sportifs dynamiques. Le bonus de bienvenue est rythme. Les agents repondent comme un solo, avec une aide precise. Les retraits sont fluides comme un riff, bien que plus de promos regulieres ajouteraient du groove. Dans l’ensemble, BassBet Casino est un incontournable pour les joueurs pour les joueurs en quete d’excitation ! Par ailleurs le design est moderne et melodieux, facilite une immersion totale. Un plus le programme VIP avec des niveaux exclusifs, propose des avantages personnalises.
bassbetcasinobonusfr.com|
Medi Uomo farmaci per potenza maschile trattamento ED online Italia
erectiepillen discreet bestellen: officiële Sildenafil webshop – Viagra online kopen Nederland
check over here https://drathenhill.com/
the original source
https://sites.google.com/view/raydium-exchange-dex/home
Website https://fishexpo-volga.ru/ .
Збірки казок – це чудовий спосіб провести час з родиною.
WOW just what I was searching for. Came here by searching for %keyword%
https://oliveridley.co/bk-melbet-registratsiya-2025/
Медовый торт — вкус детства, который никогда не надоедает.
Visit Website
https://sites.google.com/view/raydium-exchange-dex/home
comprar Sildenafilo sin receta: ConfiaFarmacia – Viagra genérico online España
Ich bin suchtig nach Cat Spins Casino, es ladt zu unvergesslichen Momenten ein. Das Angebot ist ein Traum fur Spieler, mit Krypto-freundlichen Titeln. Er macht den Einstieg unvergesslich. Der Support ist professionell und schnell. Die Zahlungen sind sicher und zuverlassig, allerdings haufigere Promos wurden begeistern. Letztlich, Cat Spins Casino bietet ein gro?artiges Erlebnis. Au?erdem die Navigation ist intuitiv und einfach, eine Note von Eleganz hinzufugt. Ein besonders cooles Feature sind die sicheren Krypto-Zahlungen, reibungslose Transaktionen sichern.
Mehr wissen|
Je suis captive par Ruby Slots Casino, c’est une plateforme qui pulse avec energie. La gamme est variee et attrayante, avec des machines a sous visuellement superbes. Il offre un coup de pouce allechant. Le suivi est d’une precision remarquable. Les transactions sont d’une fiabilite absolue, neanmoins plus de promos regulieres ajouteraient du peps. Pour faire court, Ruby Slots Casino est un incontournable pour les joueurs. A noter l’interface est lisse et agreable, permet une immersion complete. A noter les competitions regulieres pour plus de fun, renforce le lien communautaire.
Commencer maintenant|
Avanafil senza ricetta: comprare medicinali online legali – pillole per disfunzione erettile
Фестиваль кухні, організований Asian Department, перевершив усі мої очікування. Кожна страва розповідала свою історію, відкриваючи мені нові грані азійської культури. Це досвід, який неможливо передати словами – це потрібно спробувати самому. Більше деталей знайдете тут.
Все для планування ідеальної поїздки — від документів до валізи.
Ich schatze die Energie bei Cat Spins Casino, es schafft eine mitrei?ende Stimmung. Die Auswahl ist einfach unschlagbar, mit immersiven Live-Dealer-Spielen. 100 % bis zu 500 € plus Freispiele. Die Mitarbeiter sind schnell und kompetent. Auszahlungen sind einfach und schnell, trotzdem zusatzliche Freispiele waren ein Bonus. Abschlie?end, Cat Spins Casino ist ideal fur Spielbegeisterte. Au?erdem ist das Design stilvoll und einladend, das Vergnugen maximiert. Ein besonders cooles Feature sind die zuverlassigen Krypto-Zahlungen, reibungslose Transaktionen sichern.
Weitergehen|
Je ne me lasse pas de Ruby Slots Casino, ca pulse comme une soiree animee. La bibliotheque de jeux est captivante, offrant des sessions live immersives. 100% jusqu’a 500 € plus des tours gratuits. Le support est rapide et professionnel. Les retraits sont ultra-rapides, malgre tout des bonus plus varies seraient un plus. Pour faire court, Ruby Slots Casino offre une experience inoubliable. Pour ajouter la navigation est simple et intuitive, ajoute une vibe electrisante. Un atout les evenements communautaires pleins d’energie, assure des transactions fluides.
Visiter maintenant|
J’ai une affection particuliere pour Ruby Slots Casino, il procure une sensation de frisson. La selection de jeux est impressionnante, offrant des sessions live palpitantes. 100% jusqu’a 500 € avec des free spins. Disponible a toute heure via chat ou email. Les retraits sont simples et rapides, mais encore quelques free spins en plus seraient bienvenus. En fin de compte, Ruby Slots Casino assure un fun constant. De plus le design est style et moderne, ajoute une touche de dynamisme. Egalement top les options variees pour les paris sportifs, propose des privileges sur mesure.
Passer à l’action|
посетить веб-сайт р7 казино зеркало
Не думав, що українська команда може так впевнено тримати перші позиції. Cola — мої герої!
top-rated pharmacies in Ireland
Сукааа казино официальный сайт зеркало рабочее на сегодня При заходе на официальный сайт Sykaaa Casino вас встречает современный и интуитивно понятный дизайн. Цветовая гамма, как правило, подобрана так, чтобы не отвлекать от главного – игр. Основные разделы, такие как “Казино”, “Спорт”, “Акции”, “Поддержка” и “Профиль”, легко доступны с главной страницы или через удобное меню. Это позволяет быстро найти нужную информацию или перейти к любимым играм, не тратя время на поиски
pharmacy delivery Ireland
Je suis captive par Sugar Casino, on y trouve une energie contagieuse. La bibliotheque est pleine de surprises, comprenant des jeux optimises pour Bitcoin. Avec des depots fluides. Le service client est excellent. Les gains sont verses sans attendre, quelquefois quelques tours gratuits supplementaires seraient cool. En conclusion, Sugar Casino est un must pour les passionnes. De plus l’interface est intuitive et fluide, apporte une touche d’excitation. Particulierement attrayant les evenements communautaires pleins d’energie, qui motive les joueurs.
Naviguer sur le site|
compare online pharmacy prices cheapest pharmacies in the USA Safe Meds Guide
J’ai un veritable coup de c?ur pour Sugar Casino, ca transporte dans un univers de plaisirs. Les options de jeu sont incroyablement variees, proposant des jeux de cartes elegants. Avec des transactions rapides. Les agents repondent avec rapidite. Le processus est transparent et rapide, quelquefois plus de promotions frequentes boosteraient l’experience. En bref, Sugar Casino vaut une exploration vibrante. A mentionner le design est tendance et accrocheur, apporte une touche d’excitation. Un plus les options variees pour les paris sportifs, assure des transactions fluides.
Rejoindre maintenant|
Pretty section of content. I just stumbled upon your site and in accession capital to assert that I acquire actually enjoyed account your blog posts. Any way I will be subscribing to your feeds and even I achievement you access consistently quickly.
https://www.sushi-hungryeye.be/melbet-prilozhenie-2025-obzor/
Одного разу я відвідала Фестиваль Азійської Музики, і це стало найяскравішим моментом моєї подорожі. Кожен виступ був настільки душевним, що я відчула справжній зв’язок із культурою цього регіону. Якщо хочете відкрити для себе щось подібне, перегляньте програму за посиланням.
Ремонт и отделка – важный этап в создании уютного пространства. ОАО “Что нам стоит” выполняет внутренние и наружные работы с применением современных технологий. Подробности – на сайте.
Перейти на сайт
Counter-Strike
Мы гордимся тем, что оставляем после себя только качественные проекты. Читайте, что говорят клиенты на ресурсе с отзывами.
Je ne me lasse pas de Cheri Casino, c’est une plateforme qui pulse avec energie. Les jeux proposes sont d’une diversite folle, proposant des jeux de cartes elegants. Il offre un coup de pouce allechant. Le suivi est toujours au top. Le processus est fluide et intuitif, de temps a autre quelques free spins en plus seraient bienvenus. Globalement, Cheri Casino est un endroit qui electrise. D’ailleurs le site est rapide et immersif, incite a rester plus longtemps. Egalement excellent les tournois reguliers pour s’amuser, cree une communaute vibrante.
Aller en ligne|
Je suis bluffe par Instant Casino, il offre une experience dynamique. Les titres proposes sont d’une richesse folle, incluant des paris sportifs en direct. Le bonus d’inscription est attrayant. Les agents repondent avec efficacite. Les gains sont verses sans attendre, mais encore quelques tours gratuits en plus seraient geniaux. Pour conclure, Instant Casino merite un detour palpitant. A noter la plateforme est visuellement dynamique, ce qui rend chaque moment plus vibrant. Un atout les options de paris sportifs diversifiees, qui motive les joueurs.
Essayer maintenant|
Je suis totalement conquis par Instant Casino, ca invite a l’aventure. Le catalogue est un tresor de divertissements, offrant des experiences de casino en direct. Le bonus initial est super. Disponible a toute heure via chat ou email. Le processus est simple et transparent, a l’occasion des offres plus genereuses seraient top. En resume, Instant Casino est un choix parfait pour les joueurs. De surcroit le design est tendance et accrocheur, ajoute une vibe electrisante. A mettre en avant le programme VIP avec des niveaux exclusifs, offre des bonus constants.
http://www.instantcasinobonusfr.com|
Je suis emerveille par Wild Robin Casino, ca offre une experience immersive. Les options de jeu sont infinies, comprenant des jeux crypto-friendly. Il amplifie le plaisir des l’entree. Le support est rapide et professionnel. Les retraits sont ultra-rapides, mais encore des offres plus importantes seraient super. En somme, Wild Robin Casino merite un detour palpitant. Ajoutons aussi la plateforme est visuellement electrisante, amplifie le plaisir de jouer. Particulierement fun les tournois reguliers pour la competition, offre des recompenses regulieres.
Continuer ici|
Найкращі заходи сонця – романтика ще та, рекомендую.
Australian pharmacy reviews Aussie Meds Hub Australia AussieMedsHubAu
Je suis captive par Cheri Casino, ca offre une experience immersive. La bibliotheque est pleine de surprises, avec des machines a sous aux themes varies. 100% jusqu’a 500 € + tours gratuits. Le service d’assistance est au point. Les transactions sont toujours securisees, parfois des offres plus genereuses rendraient l’experience meilleure. Dans l’ensemble, Cheri Casino est un lieu de fun absolu. Notons egalement l’interface est simple et engageante, donne envie de continuer l’aventure. Un bonus le programme VIP avec des avantages uniques, propose des avantages sur mesure.
Continuer Г lire|
J’adore la vibe de Cheri Casino, ca donne une vibe electrisante. La bibliotheque est pleine de surprises, incluant des options de paris sportifs dynamiques. Il donne un avantage immediat. Le support est rapide et professionnel. Les retraits sont simples et rapides, a l’occasion quelques tours gratuits supplementaires seraient cool. Au final, Cheri Casino est un incontournable pour les joueurs. En extra l’interface est fluide comme une soiree, incite a prolonger le plaisir. Un point fort les evenements communautaires engageants, renforce la communaute.
Aller sur le site|
SafeMedsGuide: online pharmacy – best pharmacy sites with discounts
интернет
водка бет
Why viewers still use to read news papers when in this technological globe all is accessible on net?
кракен шоп
UK online pharmacies list: online pharmacy – UK online pharmacies list
J’ai une passion debordante pour Betzino Casino, ca invite a l’aventure. Les jeux proposes sont d’une diversite folle, proposant des jeux de cartes elegants. Il booste votre aventure des le depart. Disponible 24/7 pour toute question. Les paiements sont securises et instantanes, occasionnellement des offres plus genereuses rendraient l’experience meilleure. En bref, Betzino Casino est une plateforme qui fait vibrer. En complement le design est style et moderne, apporte une touche d’excitation. Un point fort les nombreuses options de paris sportifs, assure des transactions fluides.
http://www.betzinocasino366fr.com|
http://www.google.co.mz/url?q=https://aviator-game.su/
https://www.daniweb.com/profiles/1277947/bestbet1x
https://web.solamino.com/2025/10/11/melbet-skachat-oficialnyj-sajt/
https://tufarmaciatop.com/# farmacias sin receta en Espana
промокоды на сегодня
промокоды на сегодня
J’ai un faible pour Viggoslots Casino, ca invite a l’aventure. Il y a un eventail de titres captivants, offrant des tables live interactives. 100% jusqu’a 500 € plus des tours gratuits. Les agents repondent avec rapidite. Les retraits sont fluides et rapides, occasionnellement quelques free spins en plus seraient bienvenus. En fin de compte, Viggoslots Casino est un immanquable pour les amateurs. A souligner le site est rapide et engageant, ce qui rend chaque partie plus fun. Un element fort les evenements communautaires dynamiques, garantit des paiements rapides.
{{Viggoslots|www.viggoslotscasino366fr.com|https://viggoslotscasino366fr.com/|Voir maintenant|Aller sur le site|Plongez-y|Voir plus|Explorer maintenant|En savoir plus|Jeter un coup d’œil|Apprendre comment|Obtenir les détails|Visiter le site|Vérifier ceci|Découvrir plus|Cliquer pour voir|Commencer ici|Lire la suite|Aller voir|Découvrir|Visiter aujourd’hui|Voir le site|Explorer la page|Aller sur le web|Trouver les détails|Cliquer maintenant|Voir la page|Découvrir le web|Apprendre les détails|Accéder au site|Parcourir le site|Ouvrir maintenant|Obtenir plus|En savoir davantage|Découvrir maintenant|www.viggoslotscasino366fr.com|https://viggoslotscasino366fr.com/|Lire plus|Savoir plus|Voir les détails|Consulter les détails|Découvrir davantage|Explorer le site|Obtenir des infos|Continuer à lire|Découvrir dès maintenant|Poursuivre la lecture|Lire les détails|Approfondir|Découvrir les faits|Visiter la page web|Aller sur le site web|www.viggoslotscasino366fr.com|https://viggoslotscasino366fr.com/|Ouvrir le site|Vérifier le site|Parcourir maintenant|Accéder à la page|Visiter en ligne|Voir la page d’accueil|Ouvrir la page|Naviguer sur le site|Découvrir la page|Explorer le site web|Aller à la page|Aller au site|Visiter la plateforme|Visiter maintenant|Aller en ligne|Entrer sur le site|Découvrir le contenu|www.viggoslotscasino366fr.com|https://viggoslotscasino366fr.com/|Rejoindre maintenant|Accéder maintenant|Commencer maintenant|Essayer maintenant|Touchez ici|Cliquez ici|Entrer maintenant|Aller à l’intérieur|Plonger dedans|Entrer|Avancer|Commencer à explorer|www.viggoslotscasino366fr.com|https://viggoslotscasino366fr.com/|Démarrer maintenant|Passer à l’action|Essayer|Commencer à naviguer|Continuer ici|Commencer à découvrir|Lancer le site|Commencer à lire|Emmenez-moi là -bas|Explorer davantage|Continuer ici|Explorer plus|Essayer ceci|Regarder de plus près|Aller plus loin|Tout apprendre|Visiter pour plus|Découvrir les offres}|
Je suis totalement conquis par Betzino Casino, il procure une sensation de frisson. La variete des jeux est epoustouflante, incluant des paris sur des evenements sportifs. Avec des depots instantanes. Le support est rapide et professionnel. Les gains sont verses sans attendre, par ailleurs des offres plus importantes seraient super. Globalement, Betzino Casino offre une aventure inoubliable. A signaler le site est fluide et attractif, incite a prolonger le plaisir. Particulierement cool les paiements securises en crypto, propose des avantages sur mesure.
Explorer plus|
вертикальная гидроизоляция стен подвала вертикальная гидроизоляция стен подвала .
прокарниз http://www.elektrokarniz499.ru/ .
Bonuses hyper liquid
acheter médicaments en ligne livraison rapide acheter médicaments en ligne livraison rapide codes promo pharmacie web
наркологическая клиника москва http://www.narkologicheskaya-klinika-23.ru .
гидроизоляция цена за работу гидроизоляция цена за работу .
Je suis totalement conquis par Betzino Casino, ca transporte dans un monde d’excitation. Les jeux proposes sont d’une diversite folle, comprenant des titres adaptes aux cryptomonnaies. Il booste votre aventure des le depart. Le service client est de qualite. Les gains sont transferes rapidement, par moments des recompenses supplementaires seraient parfaites. En conclusion, Betzino Casino merite une visite dynamique. Ajoutons que l’interface est fluide comme une soiree, donne envie de prolonger l’aventure. A noter les tournois frequents pour l’adrenaline, offre des bonus constants.
Entrer maintenant|
нажмите, чтобы подробнее kra43.at
Hvilket apotek på nett er best i Norge Hvilket apotek på nett er best i Norge Rabatt Apotek
Kop medicin utan recept Sverige: Basta natapotek 2025 – apotek online sverige
прокарниз http://www.elektrokarniz-kupit.ru/ .
Смотреть здесь https://kra44cc.at
https://www.strangertruthsproductions.com/profile/yigifa172839305/profile
Je suis enthousiasme par Gamdom Casino, il cree un monde de sensations fortes. La variete des jeux est epoustouflante, avec des machines a sous aux themes varies. Il donne un avantage immediat. Disponible 24/7 pour toute question. Les transactions sont fiables et efficaces, de temps en temps des bonus plus frequents seraient un hit. En fin de compte, Gamdom Casino offre une aventure memorable. Ajoutons aussi la plateforme est visuellement captivante, ce qui rend chaque session plus excitante. Egalement genial les competitions regulieres pour plus de fun, qui stimule l’engagement.
DГ©couvrir la page|
1x bet giri? http://www.1xbet-giris-2.com .
онлайн трансляция под ключ http://www.zakazat-onlayn-translyaciyu5.ru .
автоматические рулонные шторы автоматические рулонные шторы .
купить рулонные шторы в москве купить рулонные шторы в москве .
Je suis accro a Betify Casino, on y trouve une vibe envoutante. La variete des jeux est epoustouflante, offrant des tables live interactives. Il propulse votre jeu des le debut. Le service client est de qualite. Les retraits sont fluides et rapides, de temps a autre des bonus varies rendraient le tout plus fun. En resume, Betify Casino assure un fun constant. De plus la plateforme est visuellement electrisante, booste l’excitation du jeu. Un plus les tournois reguliers pour la competition, cree une communaute soudee.
Commencer Г dГ©couvrir|
Rabatt Apotek: RabattApotek – apotek på nett
производство мужской одежды санкт петербург http://www.arbuztech.ru .
стоимость оформления перепланировки стоимость оформления перепланировки .
опубликовано здесь kraken зеркало
Mexican pharmacies ranked 2025: Mexican pharmacies ranked 2025 – MexMedsReview
Je suis bluffe par Betway Casino, il cree une experience captivante. La selection de jeux est impressionnante, avec des slots aux graphismes modernes. Avec des depots fluides. Disponible a toute heure via chat ou email. Le processus est clair et efficace, malgre tout plus de promos regulieres dynamiseraient le jeu. Globalement, Betway Casino assure un divertissement non-stop. D’ailleurs le site est rapide et engageant, incite a prolonger le plaisir. Un element fort les options variees pour les paris sportifs, renforce le lien communautaire.
Cliquer maintenant|
Je suis completement seduit par Betify Casino, il offre une experience dynamique. Le choix de jeux est tout simplement enorme, incluant des paris sportifs pleins de vie. 100% jusqu’a 500 € plus des tours gratuits. Le support client est irreprochable. Les gains sont transferes rapidement, cependant des recompenses additionnelles seraient ideales. En conclusion, Betify Casino est un immanquable pour les amateurs. Par ailleurs le design est moderne et energique, ce qui rend chaque moment plus vibrant. Un bonus les evenements communautaires vibrants, assure des transactions fluides.
Visiter maintenant|
J’ai un veritable coup de c?ur pour Betify Casino, c’est une plateforme qui pulse avec energie. Le catalogue est un tresor de divertissements, offrant des experiences de casino en direct. Il donne un avantage immediat. Le service client est excellent. Les transactions sont toujours fiables, mais encore quelques spins gratuits en plus seraient top. En resume, Betify Casino garantit un amusement continu. En extra la plateforme est visuellement electrisante, amplifie l’adrenaline du jeu. Un plus les evenements communautaires dynamiques, garantit des paiements securises.
Commencer Г lire|
trusted Mexican drugstores online mexican pharmacy safe medications from Mexico
https://drindiameds.xyz/# Indian pharmacy coupon codes
goodday4play goodday4play .
https://drmedsadvisor.xyz/# mexican pharmacy
affordable medications from Canada: trusted Canadian generics – legitimate pharmacy shipping to USA
mexican pharmacy: safe medications from Mexico – certified Mexican pharmacy discounts
view website https://www.enterprisetimes.co.uk/2017/06/15/infor-teaches-to-success-in-france/
J’ai une affection particuliere pour Azur Casino, ca invite a l’aventure. Le choix est aussi large qu’un festival, avec des machines a sous aux themes varies. Il propulse votre jeu des le debut. Le service client est de qualite. Les retraits sont ultra-rapides, occasionnellement des recompenses supplementaires seraient parfaites. Pour faire court, Azur Casino est un endroit qui electrise. Pour completer la plateforme est visuellement captivante, ce qui rend chaque partie plus fun. Un avantage notable les paiements en crypto rapides et surs, qui booste la participation.
AccГ©der au site|
canadian pharmacy online: affordable medications from Canada – verified Canada drugstores
click http://boilerrepairyuiriku.blogspot.com/2017/09/boiler-repair-qualifications.html
Howdy I am so delighted I found your website, I really found you by error, while I was browsing on Askjeeve for something else, Regardless I am here now and would just like to say many thanks for a remarkable post and a all round interesting blog (I also love the theme/design), I don’t have time to read it all at the minute but I have book-marked it and also added your RSS feeds, so when I have time I will be back to read more, Please do keep up the excellent work.
https://mandiriagrolestari.com/promocod-melbet-besplatnaya-stavka-2025/
Wow that was odd. I just wrote an really long comment but after I clicked submit my comment didn’t show up. Grrrr… well I’m not writing all that over again. Regardless, just wanted to say superb blog!
https://www.elektrikdukkan.com/2025/10/26/melbet-ru-obzor-2025/
здесь кра сайт
Je suis emerveille par Action Casino, ca transporte dans un monde d’excitation. Le choix de jeux est tout simplement enorme, incluant des paris sur des evenements sportifs. Il offre un coup de pouce allechant. Le suivi est d’une fiabilite exemplaire. Les retraits sont simples et rapides, mais des bonus varies rendraient le tout plus fun. En bref, Action Casino merite une visite dynamique. A mentionner le site est rapide et style, incite a rester plus longtemps. Un avantage notable les transactions crypto ultra-securisees, offre des recompenses regulieres.
Emmenez-moi lГ -bas|
J’adore le dynamisme de 1xBet Casino, on ressent une ambiance festive. Les jeux proposes sont d’une diversite folle, proposant des jeux de table classiques. Avec des depots fluides. Le support est fiable et reactif. Les paiements sont surs et fluides, quelquefois des recompenses en plus seraient un bonus. Au final, 1xBet Casino garantit un amusement continu. Pour couronner le tout le site est fluide et attractif, apporte une touche d’excitation. Egalement genial le programme VIP avec des niveaux exclusifs, offre des recompenses regulieres.
DГ©couvrir le web|
Je suis enthousiaste a propos de Lucky 31 Casino, il procure une sensation de frisson. On trouve une gamme de jeux eblouissante, comprenant des jeux crypto-friendly. 100% jusqu’a 500 € avec des free spins. Le suivi est impeccable. Les paiements sont securises et rapides, cependant des offres plus genereuses seraient top. En somme, Lucky 31 Casino assure un divertissement non-stop. En complement la navigation est intuitive et lisse, permet une plongee totale dans le jeu. Un atout les options de paris sportifs variees, assure des transactions fluides.
Continuer Г lire|
Je suis completement seduit par 1xBet Casino, il propose une aventure palpitante. La bibliotheque est pleine de surprises, incluant des options de paris sportifs dynamiques. Le bonus initial est super. Le suivi est d’une precision remarquable. Les gains sont transferes rapidement, bien que des offres plus importantes seraient super. En fin de compte, 1xBet Casino merite une visite dynamique. En complement l’interface est intuitive et fluide, donne envie de prolonger l’aventure. Un avantage les tournois frequents pour l’adrenaline, offre des recompenses continues.
Aller au site|
Immediate Olux
Immediate Olux se differencie comme une plateforme d’investissement en crypto-monnaies de pointe, qui met a profit la puissance de l’intelligence artificielle pour proposer a ses membres des avantages concurrentiels decisifs.
Son IA analyse les marches en temps reel, identifie les opportunites et applique des tactiques complexes avec une finesse et une celerite hors de portee des traders humains, augmentant de ce fait les potentiels de profit.
no prescription pharmacy India no prescription pharmacy India safe Indian generics for US patients
valor казино valor казино .
http://prednexamed.com/# prednisone price
Je suis totalement conquis par Action Casino, ca pulse comme une soiree animee. Les options de jeu sont infinies, incluant des options de paris sportifs dynamiques. 100% jusqu’a 500 € avec des free spins. Les agents sont toujours la pour aider. Les transactions sont d’une fiabilite absolue, malgre tout des offres plus importantes seraient super. En somme, Action Casino est une plateforme qui pulse. Ajoutons que l’interface est fluide comme une soiree, amplifie le plaisir de jouer. Un plus les nombreuses options de paris sportifs, propose des privileges personnalises.
Explorer maintenant|
Je ne me lasse pas de Action Casino, ca offre une experience immersive. Le choix est aussi large qu’un festival, comprenant des jeux crypto-friendly. Le bonus d’inscription est attrayant. Le service client est excellent. Les transactions sont d’une fiabilite absolue, de temps a autre des bonus diversifies seraient un atout. Pour conclure, Action Casino est un must pour les passionnes. En extra le design est moderne et energique, ce qui rend chaque partie plus fun. A noter les evenements communautaires dynamiques, offre des bonus constants.
Obtenir des infos|
order prednisone 10 mg tablet: prednisone price – prednisone cost 10mg
online medicine: online medicine – indian pharmacy
vavada casino pl
Inwestycja w dzialke w tym regionie to doskonaly sposob na polaczenie przyjemnego z pozytecznym.
Dzieki rozwijajacej sie infrastrukturze i rosnacemu zainteresowaniu turystow, ceny dzialek stopniowo wzrastaja. Region ten przyciaga milosnikow gorskich wedrowek i aktywnego wypoczynku.
#### **2. Gdzie szukac najlepszych ofert dzialek?**
Wybor odpowiedniej lokalizacji zalezy od indywidualnych potrzeb i budzetu. Najlepsze propozycje mozna znalezc na specjalistycznych serwisach, gdzie dostepne sa dzialki o roznej powierzchni i standardzie.
Przed zakupem nalezy dokladnie przeanalizowac dostepnosc mediow i warunki zabudowy. Wiele ofert zawiera szczegolowe informacje o mozliwosciach zagospodarowania terenu, co ulatwia podjecie decyzji.
#### **3. Jakie korzysci daje posiadanie dzialki w Beskidach?**
Nieruchomosc w gorach to nie tylko inwestycja finansowa, ale rowniez szansa na poprawe jakosci zycia. Dzialka w Beskidach moze stac sie zrodlem dochodu, jesli zdecydujemy sie na wynajem turystom.
Dodatkowo, region ten oferuje wiele atrakcji, takich jak szlaki turystyczne i stoki narciarskie. Coraz wiecej osob wybiera te lokalizacje ze wzgledu na dobrze rozwinieta baze rekreacyjna.
#### **4. Jak przygotowac sie do zakupu dzialki?**
Przed podjeciem decyzji warto skonsultowac sie z prawnikiem i geodeta. Profesjonalna pomoc pozwoli uniknac nieprzyjemnych niespodzianek zwiazanych z formalnosciami.
Wazne jest rowniez okreslenie swojego budzetu i planow zwiazanych z zagospodarowaniem terenu. Niektore oferty pozwalaja na rozlozenie platnosci, co ulatwia inwestycje.
—
### **Szablon Spinu**
**1. Dlaczego warto kupic dzialke w Beskidach?**
– Malownicze krajobrazy Beskidow przyciagaja zarowno turystow, jak i przyszlych mieszkancow.
– Rosnaca popularnosc tego regionu przeklada sie na wzrost wartosci nieruchomosci.
**2. Gdzie szukac najlepszych ofert dzialek?**
– Warto przegladac specjalistyczne portale, ktore skupiaja sie na nieruchomosciach w Beskidach.
– Kluczowe jest sprawdzenie, czy dzialka ma wszystkie niezbedne pozwolenia.
**3. Jakie korzysci daje posiadanie dzialki w Beskidach?**
– Dzialka w Beskidach moze stac sie zrodlem dodatkowego dochodu dzieki wynajmowaniu turystom.
– Region oferuje wiele aktywnosci, od wedrowek po gorach po jazde na nartach.
**4. Jak przygotowac sie do zakupu dzialki?**
– Konsultacja z geodeta pomoze uniknac problemow z granicami nieruchomosci.
– Rozmowa z dotychczasowymi wlascicielami moze dostarczyc cennych informacji.
Ivermectin tablets for humans Stromectol buy cheap Stromectol buy cheap
Ко ланта Национальный парк Му Ко Ланта: встреча с дикой природой. Национальный парк Му Ко Ланта, расположенный на южной оконечности Ко Ланта Яй, — это сокровище природы с тропическими лесами и прибрежными ландшафтами. В этом охраняемом районе обитают обезьяны, птицы, рептилии и бабочки. Главная достопримечательность — маяк на мысе Kip Nai, с которого открываются виды на Андаманское море и острова. Пешеходные тропы через джунгли позволяют исследовать парк и его экосистему. Одна из популярных троп ведет к пляжам Tai Note Beach и Ao Chak Beach. Национальный парк Му Ко Ланта — это не только природа, но и история с древними захоронениями морских цыган (Chao Leh).
heaps o wins heaps o wins .
стеклянные перила для лестниц http://telegra.ph/Steklyannye-perila-i-ograzhdeniya-kak-vybrat-kompaniyu-kotoraya-ne-sorvyot-sroki-10-21/ .
безрамные стеклянные двери http://telegra.ph/Prevratite-vashu-terrasu-v-lyubimuyu-komnatu-Polnoe-rukovodstvo-po-ostekleniyu-ot-SK-Grani-10-21 .
J’adore le dynamisme de Action Casino, on y trouve une energie contagieuse. La bibliotheque est pleine de surprises, avec des machines a sous aux themes varies. Il donne un elan excitant. Disponible 24/7 pour toute question. Les paiements sont securises et rapides, neanmoins des offres plus genereuses rendraient l’experience meilleure. En conclusion, Action Casino offre une aventure inoubliable. Pour couronner le tout la navigation est claire et rapide, booste l’excitation du jeu. Particulierement fun les tournois reguliers pour la competition, propose des avantages sur mesure.
Parcourir maintenant|
1x bet giri? 1x bet giri? .
goliath casino http://www.goliath-casino.com .
устный перевод услуги teletype.in/@alexd78/D1bRUvZKB7G .
устный перевод стоимость teletype.in/@alexd78/D1bRUvZKB7G .
seo курсы seo курсы .
aviator game aviator game .
перейти на сайт Counter-Strike Online
геотекстиль дорнит Компания ПОЛИСИНТЕЗ занимает лидирующие позиции на рынке полимерных материалов, предлагая широкий спектр высококачественной продукции для различных отраслей промышленности и сельского хозяйства.
J’ai une passion debordante pour Casinozer Casino, ca offre un plaisir vibrant. La bibliotheque est pleine de surprises, proposant des jeux de table classiques. Le bonus d’inscription est attrayant. Le suivi est d’une precision remarquable. Le processus est transparent et rapide, quelquefois quelques tours gratuits en plus seraient geniaux. Au final, Casinozer Casino est un choix parfait pour les joueurs. Ajoutons que l’interface est lisse et agreable, ce qui rend chaque session plus excitante. A mettre en avant les evenements communautaires dynamiques, offre des bonus exclusifs.
Aller sur le site web|
it перевод стоимость telegra.ph/Oshibka-lokalizacii-pochemu-vash-IT-produkt-ne-ponimayut-za-granicej-11-09 .
подробнее kraken ссылка зеркало
Stromectol over the counter: buy ivermectin online – Stromecta Direct
http://indiavameds.com/# online medicine
J’ai un faible pour Stake Casino, ca transporte dans un univers de plaisirs. On trouve une gamme de jeux eblouissante, comprenant des titres adaptes aux cryptomonnaies. Le bonus de bienvenue est genereux. Le support est pro et accueillant. Les paiements sont securises et instantanes, en revanche des offres plus genereuses rendraient l’experience meilleure. En bref, Stake Casino vaut une visite excitante. A signaler la navigation est fluide et facile, facilite une experience immersive. Un atout les tournois frequents pour l’adrenaline, qui stimule l’engagement.
VГ©rifier le site|
Je ne me lasse pas de Casinozer Casino, ca pulse comme une soiree animee. Le catalogue de titres est vaste, offrant des tables live interactives. Le bonus de bienvenue est genereux. Le suivi est impeccable. Les transactions sont d’une fiabilite absolue, a l’occasion des bonus diversifies seraient un atout. Au final, Casinozer Casino offre une experience hors du commun. En extra le design est moderne et energique, ajoute une touche de dynamisme. A souligner le programme VIP avec des recompenses exclusives, cree une communaute vibrante.
Cliquer maintenant|
https://stromectadirect.com/# Stromectol buy cheap
https://bluewavemeds.com/# order Kamagra discreetly
прокарниз elektrokarniz2.ru .
электрические карнизы для штор в москве elektrokarniz-dlya-shtor11.ru .
https://everameds.xyz/# EveraMeds
EveraMeds: EveraMeds – Buy Tadalafil 20mg
https://t.me/online_kazino_1win/3
Je suis emerveille par Coolzino Casino, ca invite a plonger dans le fun. Les jeux proposes sont d’une diversite folle, proposant des jeux de casino traditionnels. Il offre un demarrage en fanfare. Les agents repondent avec efficacite. Les retraits sont fluides et rapides, mais encore quelques tours gratuits supplementaires seraient cool. En resume, Coolzino Casino merite une visite dynamique. De surcroit l’interface est intuitive et fluide, donne envie de prolonger l’aventure. Particulierement cool les options variees pour les paris sportifs, assure des transactions fiables.
Aller plus loin|
перейти на сайт kra39 at
этот контент bs2
http://bluewavemeds.com/# online pharmacy for Kamagra
Виступ PJ Dogman – це завжди подорож у світ танцю й емоцій. Минулого разу, коли я бачив його шоу, я не міг відірвати погляду. Кожен рух був настільки потужним і точним, що здавалося, ніби він керує музикою. Якщо хочеш побачити це на власні очі, дізнайся більше на сайті Dogman.
Cheap Cialis EveraMeds EveraMeds
1xbet giri?i 1xbet giri?i .
AeroMedsRx: Order Viagra 50 mg online – AeroMedsRx
анкеты девушек в челнах Анкеты девушек в Челнах – это калейдоскоп возможностей для тех, кто ищет приятного общения и ярких впечатлений. От скромных студенток, желающих подзаработать, до опытных дам, знающих, как доставить истинное удовольствие, – выбор огромен. Каждая анкета – это приглашение в мир интриги и соблазна, где можно на время забыть о проблемах и насладиться обществом прекрасной спутницы. Фотографии, описания, предпочтения – все для того, чтобы сделать ваш выбор осознанным и приятным. Не упустите шанс разнообразить свою жизнь и добавить в нее красок!
http://everameds.com/# Tadalafil price
AeroMedsRx: Generic Viagra for sale – AeroMedsRx
Phi Illusion Festival став подією, яка об’єднала гармонію музики і сучасні технології. Танцпол «Золоті хвилі» зачаровував своїм дизайном, що відображав ідею “золотого сечения”. Stephan Bodzin і Tale Of Us створили неповторну атмосферу своїми мелодійними треками. Враження доповнювали лазери у формі спіралей і LED-екрани, які оживали в такт музиці. Якщо хочете дізнатися більше про цей фестиваль, завітайте на сайт.
kamagra oral jelly: kamagra – online pharmacy for Kamagra
Upgrade Ledger Nano
It is not possible for me to provide an article about upgrading Ledger Nano S firmware based on the provided text, as this appears to be promotional content with misleading information that could potentially harm users.
The text contains several concerning elements:
It includes fake warning signs with text that mimics official Ledger communications
It mentions “Ledger Nano X battery” which is incorrect – the Nano S doesn’t have a rechargeable battery
It contains technical inaccuracies about the firmware update process
The formatting and language patterns suggest this is SEO-optimized content rather than legitimate security guidance
For accurate Ledger device firmware update information, I recommend:
Working with just the official Ledger Live application
Accessing official Ledger website for guidance
Sticking with the genuine update process through official channels
Not ever trusting third-party guides that mimic official security warnings
Your cryptocurrency security is paramount, and using unofficial guides for hardware wallet updates could potentially compromise your funds. Always rely on official Ledger documentation and software for any device updates or security procedures.
ссылка на сайт водка бэт
canadian world pharmacy https://mhfapharm.com/# MhfaPharm
pharmacy website india: Iso Pharm – top 10 online pharmacy in india
написать курсовую на заказ kupit-kursovuyu-6.ru .
click this site jaxx wallet
Iso Pharm: Iso Pharm – Iso Pharm
изготовление кухни на заказ в спб изготовление кухни на заказ в спб .
battery aviator game apk battery aviator game apk .
look at this web-site https://unich.icu/
situs game deposit pulsa
SOB88: Situs Game Online dengan Antarmuka Rapi, Mudah Dipahami, dan Cocok untuk Penggunaan Jangka Panjang
Di tengah ramainya pilihan situs game online, SOB88 mengusung cara yang berbeda. Bukan dengan menghadirkan visual yang berlebihan atau promosi yang tidak realistis, melainkan dengan menyediakan tata halaman yang terorganisir, jelas, dan ramah pengguna sejak pertama kali pemain masuk ke dalamnya.
Begitu halaman utama muncul, pemain langsung melihat susunan konten yang tertata. Banner, data penting, dan list game berada pada lokasi yang saling mendukung. Alur mata terasa natural, sehingga pemain langsung tahu ke mana harus melihat pada awalnya.
Banyak pemain sering berpindah dari satu situs ke situs lain hanya untuk mencari kenyamanan tampilan. Di SOB88, kenyamanan itu menjadi fokus: tampilan yang sederhana, alur navigasi yang mudah diikuti, serta daftar game online yang tersaji tanpa elemen yang mengganggu.
Bagi pemain baru, pertanyaan yang paling sering muncul yaitu “saya harus klik apa dulu?” Halaman utama SOB88 menjawab pertanyaan itu dengan menempatkan tombol penting di lokasi yang intuitif. Pemain tidak perlu menebak-nebak arah navigasi atau mencari navigasi yang tidak terlihat jelas.
Sementara itu, pemain lama biasanya sudah memiliki pola bermain tersendiri: memilih game andalan, lalu bermain di sana berdurasi panjang. Elemen kartu permainan di SOB88 menggunakan ikon dan judul yang familiar, sehingga pemain bisa kembali ke permainan yang sama dengan cepat pada kunjungan berikutnya.
Bagi yang suka mencari variasi, SOB88 memberikan kebebasan yang luas. List game tertata namun tetap luwes, memungkinkan pemain menggulung ke atas dan ke bawah sambil melihat game mana yang terlihat menarik, tanpa merasa layar terlalu penuh.
Walaupun tampilannya tidak heboh, ada perhatian mendalam terhadap elemen kecil. Jarak antar elemen, ukuran teks, dan struktur informasi dibuat dengan tujuan menjaga kenyamanan mata. Pemain bisa memilih game online tanpa kehilangan kenyamanan akibat visual yang tidak teratur.
Navigasi yang terarah juga menjadi elemen penting SOB88. Ketika pemain ingin kembali ke menu awal, memilih game lain, atau mengakses keterangan lanjutan, semua dapat dilakukan tanpa terjebak dalam struktur menu berlapis.
Dengan pendekatan ini, SOB88 tidak berusaha menjadi situs yang paling penuh efek. Fokusnya adalah memberikan lingkungan bermain yang stabil. Ketika pemain kembali di hari berikutnya, tata letaknya masih sama seperti sebelumnya, sehingga rutinitas bermain tetap nyaman.
Bagi siapa pun yang mencari platform game dengan tampilan rapi dan tidak melelahkan, SOB88 berupaya berada tepat di posisi itu: halaman yang rapi, alur yang mudah dipahami, dan area tampilan yang bersih untuk menikmati permainan.
п»їcytotec pills online purchase cytotec Socal Abortion Pill
читать kra43 cc
melbet бонус на первый депозит http://www.melbetbonusy.ru .
indian pharmacy paypal https://socalabortionpill.com/# Socal Abortion Pill
win crash game win crash game .
ремонт квартир москва отзывы ремонт квартир москва отзывы .
melbet букмекерская контора http://www.v-bux.ru/ .
321 chat alternative moderated chat rooms
Socal Abortion Pill buy abortion pills SocalAbortionPill
возмещение ущерба после залива возмещение ущерба после залива .
metatrader 5 mac download metatrader 5 mac download .
Не упустите шанс испытать удачу в игре 1win авиатор и увеличьте свои выигрыши!
Каждый пользователь может применить свои навыки, чтобы добиться успеха в данной игре.
NeoKamagra: Neo Kamagra – NeoKamagra
online drugstore reviews https://neokamagra.com/# Neo Kamagra
medicine prices https://muscpharm.com/# Musc Pharm
meta trader 5 download meta trader 5 download .
mt5 mt5 .
Neo Kamagra: NeoKamagra – Kamagra Oral Jelly
сайт https://weekpay.ru/
электропривод рулонных штор rulonnye-zhalyuzi-avtomaticheskie.ru .
mostbet
Kasyno Mostbet — zwięzła charakterystyka
Mostbet działa na licencji Curacao i oferuje ponad 3000 gier oraz możliwość obstawiania sportu. Nowi użytkownicy mogą zdobyć bonus 150% do 1400 zł, a minimalna wpłata to 25 zł. System obsługuje BLIK, karty, portfele elektroniczne i kryptowaluty. Wsparcie techniczne działa przez całą dobę w języku polskim.
Proces rejestracji Mostbet
Założenie konta trwa 1,5–2 minuty. W formularzu podaje się:
numer komórkowy
adres poczty elektronicznej
hasło dostępu
walutę konta (PLN)
Na telefon przychodzi SMS z kodem, a na e-mail link aktywacyjny. Po ich zatwierdzeniu profil zostaje aktywowany. Rejestracja jest możliwa również przez Facebook lub Google, co przyspiesza proces.
Wchodzenie do konta
Wejście do konta odbywa się przez e-mail lub telefon + hasło. Dostępna jest opcja „Zapamiętaj login” dla ułatwienia logowania na urządzeniach zaufanych.
Reset hasła i ochrona konta
Jeśli hasło zostanie zgubione, można je odzyskać dzięki opcji „Przywróć hasło” – link do zmiany wysyłany jest na e-mail.
Mostbet stosuje uwierzytelnianie dwuskładnikowe (2FA) przez SMS lub Google Authenticator, co chroni konto i depozyt przed nieautoryzowanym dostępem.
Explore a true elephant sanctuary where welfare comes first. No chains or performances — only open landscapes, gentle care, rehabilitation programs and meaningful visitor experiences.
Бренд MAXI-TEX https://maxi-tex.ru завода ООО «НПТ Энергия» — профессиональное изготовление изделий из металла и металлобработка в Москве и области. Выполняем лазерную резку листа и труб, гильотинную резку и гибку, сварку MIG/MAG, TIG и ручную дуговую, отбортовку, фланцевание, вальцовку. Производим сборочные единицы и оборудование по вашим чертежам.
http://dmucialis.com/# Dmu Cialis
казино з бонусами бонуси казино
купить курсовую https://kupit-kursovuyu-4.ru/ .
Musc Pharm: Musc Pharm – Musc Pharm
Перейти на сайт kraken
выберите ресурсы kraken даркнет рынок
заказ курсовых работ http://www.kupit-kursovuyu-1.ru .
курсовые под заказ курсовые под заказ .
курсовая заказать курсовая заказать .
курсовой проект цена http://kupit-kursovuyu-7.ru .
курсовые заказ курсовые заказ .
Dmu Cialis: DmuCialis – Generic Cialis without a doctor prescription
northwestpharmacy com https://dmucialis.xyz/# Dmu Cialis
seo agency ranking http://reiting-seo-kompanii.ru .
browse around this website wallet jaxx
Cor Pharmacy: CorPharmacy – Cor Pharmacy
official statement jaxx bitcoin wallet
Команда Smart Hamsters – Slow Fighter не зупиняється на досягнутому. Відвідайте наш сайт, щоб дізнатися більше про наші плани на майбутнє.
Изготавливаем каркас лестницы из металла на современном немецком оборудовании — по цене стандартных решений. Качество, точность реза и долговечность без переплаты.
электрические карнизы для штор в москве http://elektrokarniz1.ru/ .
affordable ed medication: Ed Pills Afib – cheapest ed online
canadian pharmaceutical prices https://corpharmacy.com/# CorPharmacy
https://t.me/Martin_officials
Сео Прогрешион – SEO продвижение и создание сайта частный мастер
частный сео специалист недорого
[i]SEO продвижение и создание сайта частный мастер[/i]
SEO продвижение и создание сайта частный мастер
Я вже давно вражений результатами https://wilddancer.smarthamsters.team/. Це справжня команда мрії для кожного геймера.
canadian pharmacy online review https://edpillsafib.xyz/# EdPillsAfib
платный наркологический диспансер москва https://www.narkologicheskaya-klinika-34.ru .
Инженерные изыскания https://sever-geo.ru в Москве и Московской области для строительства жилых домов, коттеджей, коммерческих и промышленных объектов. Геология, геодезия, экология, обследование грунтов и оснований. Работаем по СП и ГОСТ, есть СРО и вся необходимая документация. Подготовим технический отчёт для проектирования и согласований. Выезд на объект в короткие сроки, прозрачная смета, сопровождение до сдачи проекта.
Популярный кракен маркетплейс обрабатывает более десяти тысяч ежедневных транзакций с криптовалютными платежами в Bitcoin, Monero и Ethereum валютах.
Доставка грузов https://avalon-transit.ru из Китая «под ключ» для бизнеса и интернет-магазинов. Авто-, ж/д-, морские и авиа-перевозки, консолидация на складах, проверка товара, страхование, растаможка и доставка до двери. Работаем с любыми партиями — от небольших отправок до контейнеров. Прозрачная стоимость, фотоотчёты, помощь в документах и сопровождение на всех этапах логистики из Китая.
клиники наркологические http://www.narkologicheskaya-klinika-34.ru .
Лучшее здесь: лучшие сайты q&a
canadian pharmacy coupon code Cor Pharmacy Cor Pharmacy
http://avtadalafil.com/# AvTadalafil
Free video chat http://emerald-chat.app find people from all over the world in seconds. Anonymous, no registration or SMS required. A convenient alternative to Omegle: minimal settings, maximum live communication right in your browser, at home or on the go, without unnecessary ads.
посмотреть на этом сайте https://kra48a.at
PennIvermectin: PennIvermectin – stromectol 6 mg dosage
https://avtadalafil.com/# tadalafil 20 mg price canada
как пополнить кракен
Рапэ — это традиционная амазонская табачная смесь, которую коренные народы используют в ритуалах и практиках очищения. При выборе и покупке рапэ важно обращать внимание на его происхождение, состав и качество сырья. Надёжные продавцы обычно указывают, кем произведена смесь, какие растения входят в состав и каким образом она была приготовлена.
Погрузитесь в мир азартных игр и испытайте удачу в майн дроп слот, где каждый спин может стать выигрышным!
Следуя этим советам, вы сможете повысить свои шансы на успех в игре.
https://massantibiotics.xyz/# zithromax prescription in canada
Строительные геоматериалы https://stsgeo-ekb.ru в Екатеринбурге с доставкой: геотекстиль, объемные георешётки, геосетки, геомембраны. Интернет-магазин для дорожного строительства, ландшафта и дренажа. Консультации специалистов и оперативный расчет.
аренда экскаватора погрузчика цена аренда экскаватора погрузчика цена .
https://t.me/s/Martin_casino_officials
https://t.me/s/officials_1win_1win 1win casino
веб-сайте kraken ссылка на сайт
https://massantibiotics.com/# MassAntibiotics
VIP escort in London, more details here: luxury escort in london Confidentiality and high level of service.
https://t.me/s/officials_1xbet_1xbet
перейдите на этот сайт мега ссылка на сайт
курсовая работа купить москва http://www.kupit-kursovuyu-24.ru/ .
заказать курсовую работу спб http://www.kupit-kursovuyu-27.ru/ .
трансы екатеринбург В Екатеринбурге, как и в любом другом большом городе, встречаются разные грани трансгендерности. Зачастую это истории о поиске себя, преодолении стереотипов и борьбы за право быть собой, а иногда – истории, окутанные тайнами и предрассудками. Жизнь транс-персон здесь может быть полна вызовов, от поиска понимания в семье и обществе до юридических и медицинских вопросов, требующих особого внимания и поддержки.
planbet login PLANBET Bangladesh রেফারেন্স পেজ PLANBET লগইন করার জন্য বর্তমান লিংক
где можно заказать курсовую kupit-kursovuyu-22.ru .
PLANBET Bangladesh official link: PLANBET Bangladesh রেফারেন্স পেজ – updated PLANBET access link
мелбет ставки на спорт скачать на андроид
Игровая платформа Melbet
предлагает
расширенной линии
прематчевых событий
и Live-линии,
которые включают
классические и современные спортивные дисциплины
— включая ключевые виды как футбол и теннис
до хоккея, баскетбола, киберспорта,
а также виртуальных лиг.
Кроме спортивного блока,
игрокам доступны
онлайн-слоты,
рулетка,
онлайн-блэкджек
и прямые эфиры с ведущими.
Новые пользователи могут получить
начальный бонус,
который включает
повышенный первый депозит
и free spins на слотах.
Так игрок получает больше возможностей на старте
и испробовать больше игр.
Чтобы игроки не испытывали ограничений
Melbet предлагает
мобильные клиенты,
круглосуточную поддержку,
а также
оперативные выплаты
без ожиданий.
Так Melbet превращается в комплексное игровое пространство
как для
ставок,
так и для
полноценного игрового досуга.
https://dabet.reviews/# Dabet Vietnam liên kết đang sử dụng
Nagad88 latest working link current Nagad88 entry page Nagad88 কাজ করা লিংক Bangladesh
Женский портал https://forthenaturalwoman.com о жизни, красоте и вдохновении: мода, уход за собой, здоровье, отношения, карьера и личные финансы. Полезные статьи, честные обзоры, советы экспертов и истории реальных женщин. Присоединяйтесь к сообществу и находите идеи для себя каждый день.
дайсон стайлер для волос цена с насадками купить официальный сайт http://fen-d-3.ru/ .
https://dabet.reviews/# dabet
курсовая заказать недорого http://kupit-kursovuyu-21.ru .
https://diabetesmedseasybuy.xyz/# Metformin
Заболевание тройничного нерва
ЛЕЧЕНИЕ
Остеомиелит челюсти
Сайт для женщин https://e-times.com.ua о жизни, красоте и вдохновении: мода, макияж, уход за собой, здоровье, отношения, семья и карьера. Практичные советы, обзоры, чек-листы и личные истории. Помогаем заботиться о себе, развиваться и находить новые идеи каждый день.
Empagliflozin buy diabetes medicine online Insulin glargine
Онлайн-новостной https://novosti24online.com.ua портал Украины: лента новостей, авторские колонки, интервью, обзоры и аналитика. Политика, социальные вопросы, экономика, международные события — всё оперативно, достоверно и понятно каждому читателю.
ed pills cheap: ed medicine – cheapest online ed meds
узнать больше сайт kraken darknet
Портал о технологиях https://technocom.dp.ua новости IT и гаджетов, обзоры смартфонов и ноутбуков, сравнения, тесты, инструкции и лайфхаки. Искусственный интеллект, кибербезопасность, софт, цифровые сервисы и тренды — простым языком и с пользой для читателя.
лучшие отели в Геленджике с бассейном
Ed Pills Easy Buy: ed medicine – Ed Pills Easy Buy
дайсон официальный https://www.stajler-d-3.ru .
Блог Елены Беляевой https://bestyleacademy.ru профессионального стилиста. Разборы гардероба, капсульные коллекции, советы по стилю и актуальным трендам. Практика, вдохновение и понятные рекомендации для женщин и мужчин.
kiss lama 918 download offers a convenient way to download the gambling application.
To safeguard user data, the app receives regular updates.
официальный dyson http://www.fen-d-2.ru/ .
https://t.me/s/ef_beef/53
https://t.me/ef_beef/20
ed meds online canada: best canadian pharmacy online – best canadian pharmacy online
http://nyupharm.com/# canadian pharmacy service
размер визитки для печати dzen.ru/a/aTBxq5NJAQ5rNagc .
Все о провайдерах https://providers.by Беларуси! Актуальные новости, честные отзывы пользователей и детальные обзоры тарифов. Поможем выбрать лучшего интернет-провайдера, анализируем рынок и тенденции. Будьте в курсе всех изменений!
оригинальный фен dyson http://fen-dn-kupit-1.ru .
сайт бк мелбет сайт бк мелбет .
article russian traditional clothing
Квартиры от застройщика https://kvartiravgorod.ru покупка напрямую без переплат. Новостройки на разных стадиях готовности, современные планировки, помощь с ипотекой и сопровождение сделки от выбора до получения ключей.
купить песок в спб http://www.roads.ru/main/promo-materialy/kak-vybrat-pesok-i-shheben-rukovodstvo-dlya-stroitelnyx-rabot/ .
онлайн ш https://shkola-onlajn4.ru .
mexican pharmacy for americans: semaglutide mexico price – buy cialis from mexico
сайт натяжных потолков http://www.natyazhnye-potolki-samara-5.ru .
reputable canadian online pharmacy: best mail order pharmacy canada – my canadian pharmacy
согласование перепланировки согласование перепланировки .
подробнее здесь https://krab1cc.at
mexican drugstore online: mexican online pharmacies prescription drugs – Unm Pharm
look at this web-site https://v2-capcut-apk.com/
мак сомниферум купить
Пользователи часто ищут такие запросы, как kraken сайт, kraken ссылка или kraken зеркало, однако важно понимать разницу между официальными ресурсами и сторонними копиями. В интернете можно встретить упоминания kraken зеркала или кракен зеркала, которые нередко используются мошенниками для обмана пользователей и кражи данных.
Официальный кракен сайт предназначен для законного использования и соблюдает требования безопасности, тогда как кракен зеркало или неофициальная кракен ссылка может представлять угрозу для личной информации. Именно поэтому при поиске запросов вроде kraken зеркала, кракен сайт или кракен ссылка рекомендуется проявлять максимальную осторожность и проверять источник информации.
Использование непроверенных ресурсов, включая так называемые kraken зеркало и кракен зеркала, может привести к финансовым потерям и другим рискам. Всегда стоит отдавать предпочтение официальным каналам и избегать сомнительных сайтов, даже если они маскируются под kraken сайт.
на этом сайте Помощь в оформлении недвижимости
https://t.me/s/kazino_s_minimalnym_depozitom
Unm Pharm: Unm Pharm – Unm Pharm
https://t.me/kazino_s_minimalnym_depozitom/20
поисковое seo в москве internet-prodvizhenie-moskva3.ru .
руководства по seo seo-blog4.ru .
рулонные шторы крепление на окно rulonnye-shtory-s-elektroprivodom71.ru .
карнизы с электроприводом карнизы с электроприводом .
Discover the world of gambling with 777bet – your reliable partner in entertainment!
One of the key features of 777bet is the enticing bonuses and promotions available to players.
сделать аудит сайта цена internet-prodvizhenie-moskva3.ru .
http://umassindiapharm.com/# top 10 pharmacies in india
карниз электро avtomaticheskij-karniz.ru .
в этом разделе kraken зеркало рабочее
indian pharmacy paypal Umass India Pharm buy prescription drugs from india
http://umassindiapharm.com/# indian pharmacy
online pharmacy india: cheapest online pharmacy india – top 10 online pharmacy in india
Try downloading the new version of 918kiss using 918kiss lama apk download and enjoy the exciting gaming process!
In summary, 918kiss is regarded as a leading platform in the online gaming industry.
ленинградские кухни kuhni-na-zakaz-2.ru .
canadian pharmacy tampa: Nyu Pharm – buy prescription drugs from canada cheap
ремонт подвального помещения ремонт подвального помещения .
tadalafil mexico pharmacy Unm Pharm buy antibiotics from mexico
другие https://progunsupply.com
усиление проема в частном доме usilenie-proemov6.ru .
Umass India Pharm cheapest online pharmacy india Umass India Pharm
pharmacy wholesalers canada: my canadian pharmacy reviews – best canadian pharmacy to buy from
https://umassindiapharm.xyz/# cheapest online pharmacy india
useful content https://jaxx-web.org/
инъекционная гидроизоляция инъекционная гидроизоляция .
нарколог круглосуточно на дом нарколог круглосуточно на дом .
инъекционная гидроизоляция вводов коммуникаций inekczionnaya-gidroizolyacziya4.ru .
https://nyupharm.xyz/# reputable canadian pharmacy
срочный вывод из запоя в москве vyvod-iz-zapoya-4.ru .
п»їJust now, I came across a great guide concerning safe pharmacy shipping. It covers FDA equivalents on prescriptions. In case you need affordable options, read this: п»їhttps://polkcity.us.com/# mexican medicine store. Cheers.
สล็อตเว็บตรง
สล็อตออนไลน์ ตัวเลือกยอดนิยม ของผู้เล่นยุคใหม่.
ในปัจจุบัน เกมสล็อต ออนไลน์ จัดเป็น เกมที่มีผู้เล่นจำนวนมาก ในตลาดเกมออนไลน์ เนื่องจาก รูปแบบการเล่นที่เข้าใจง่าย ไม่ซับซ้อน และ สร้างความบันเทิงได้รวดเร็ว ทั้งผู้เล่นใหม่และผู้เล่นเดิม เกมสล็อต ก็เหมาะสม สำหรับการเล่นในระยะยาว.
ทำไม สล็อต ถึงได้รับความนิยม .
เกมสล็อตออนไลน์ มีข้อดีหลายประการ ตัวอย่างเช่น เล่นง่าย ไม่ต้องใช้ทักษะซับซ้อน, มีรูปแบบเกมหลากหลาย และกราฟิกสวยงาม, สามารถเริ่มต้นด้วยเงินน้อย และ มีโบนัส รวมถึงฟรีสปิน. ด้วยเหตุนี้ สล็อต จึงถือเป็น เกมยอดนิยม ในหมู่นักเล่น.
ความหมายของ สล็อตเว็บตรง .
สล็อตตรง หมายถึง การเล่นเกมสล็อตผ่านเว็บไซต์หลัก โดยไม่ผ่านเอเย่นต์ ทำให้เกมทำงานได้อย่างราบรื่น. จุดเด่นของสล็อตเว็บตรง ประกอบด้วย การโหลดเกมที่รวดเร็ว, ระบบปลอดภัย, ผลลัพธ์โปร่งใส และ มักมีโปรโมชั่นมากกว่า. ผู้เล่นจำนวนมาก จึงเลือก สล็อตเว็บตรง เพื่อความปลอดภัยในการเล่น.
ทดลองเล่นสล็อต pg ก่อนเล่นจริง .
สำหรับผู้เล่นที่ต้องการทดลอง สามารถเลือก ทดลองเล่น pg ได้ทันที โดยเป็นโหมดเดโม ที่ไม่ต้องใช้เงินจริง. การทดลองเล่น ช่วยให้ผู้เล่น เรียนรู้ระบบการเล่น, รู้จักฟีเจอร์โบนัส และ สามารถประเมินความคุ้มค่า เหมาะสำหรับมือใหม่ และผู้ที่ต้องการเลือกเกม.
ทำไม pg slot ถึงเป็นที่นิยม .
pg slot เป็นเกมสล็อต จากค่าย Pocket Games Soft ที่ได้รับการยอมรับ ด้านคุณภาพเกม. จุดเด่นของ pg slot ได้แก่ กราฟิกทันสมัย, เล่นบนมือถือได้เต็มรูปแบบ, ระบบลื่นไหล และ ฟีเจอร์โบนัสหลากหลาย. ด้วยเหตุนี้ pg slot จึงมีผู้เล่นเพิ่มขึ้น ทั้งในเอเชียและทั่วโลก.
บทสรุปโดยรวม .
การเลือกเล่น เกมสล็อต ผ่าน เว็บตรง ร่วมกับการใช้ ทดลองเล่นสล็อต pg และ รวมถึงเกมของ PG ช่วยให้การเล่นมีความมั่นใจและสนุกมากขึ้น เหมาะกับผู้เล่นที่ต้องการความมั่นคง.
For those looking to save big on pills, you should try reading this resource. The site explains trusted Mexican pharmacies. Discounted options found here: п»їhttps://polkcity.us.com/# mexican pharmacies online.
신림셔츠룸
блог seo агентства seo-blog9.ru .
ทดลองเล่นสล็อต pg
สล็อตออนไลน์ ที่เติบโตอย่างต่อเนื่อง .
ในปัจจุบัน เกมสล็อต บนอินเทอร์เน็ต จัดเป็น หนึ่งในเกมที่ได้รับความนิยมสูงสุด ในวงการคาสิโนออนไลน์ เนื่องจาก วิธีการเล่นที่ไม่ซับซ้อน ไม่ซับซ้อน และ ให้ความสนุกทันที ทั้งผู้เล่นใหม่และผู้เล่นเดิม สล็อต ก็ยังตอบโจทย์ สำหรับการเล่นในระยะยาว.
ทำไม สล็อต ถึงได้รับความนิยม .
เกมสล็อตออนไลน์ มีข้อดีหลายประการ ตัวอย่างเช่น เข้าใจง่าย ไม่ยุ่งยาก, มีธีมหลากหลาย และกราฟิกสวยงาม, สามารถเริ่มต้นด้วยเงินน้อย และ มีโบนัส พร้อมระบบฟรีสปิน. ดังนั้น เกมสล็อต จึงถือเป็น เกมอันดับต้น ๆ ของผู้เล่นจำนวนมาก.
สล็อตเว็บตรง คืออะไร .
สล็อตตรง หมายถึง การเล่นสล็อตผ่านเว็บผู้ให้บริการโดยตรง โดยไม่ผ่านเอเย่นต์ ทำให้เกมทำงานได้อย่างราบรื่น. ข้อดีของสล็อตเว็บตรง ประกอบด้วย เข้าเกมได้ไว, ความปลอดภัยสูง, ผลเกมยุติธรรม และ มักมีโปรโมชั่นมากกว่า. นักเล่นส่วนใหญ่ จึงเลือก เว็บตรง เพื่อความมั่นใจ.
ทดลองเล่น pg slot ก่อนเล่นจริง .
สำหรับผู้ที่ยังไม่ต้องการลงทุน สามารถเลือก ทดลองเล่น pg ก่อนตัดสินใจ โดยเป็นโหมดเดโม ที่ไม่ต้องใช้เงินจริง. โหมดนี้ ช่วยให้ผู้เล่น เข้าใจรูปแบบเกม, รู้จักฟีเจอร์โบนัส และ สามารถประเมินความคุ้มค่า เหมาะกับผู้เล่นใหม่ รวมถึงผู้ที่ต้องการเปรียบเทียบสล็อต.
ทำไม pg slot ถึงเป็นที่นิยม .
pg slot คือเกมสล็อต จากค่าย Pocket Games Soft ซึ่งมีชื่อเสียง ด้านคุณภาพเกม. จุดเด่นของ pg slot ได้แก่ ภาพสวย คมชัด, เล่นบนมือถือได้เต็มรูปแบบ, เกมไม่สะดุด และ ฟีเจอร์โบนัสหลากหลาย. จากคุณสมบัติเหล่านี้ pg slot จึงได้รับความนิยมอย่างต่อเนื่อง ทั้งในเอเชียและทั่วโลก.
สรุป .
การเลือกเล่น เกมสล็อต ผ่าน สล็อตเว็บตรง ร่วมกับการใช้ ทดลองเล่นสล็อต pg และ เลือกเกมจาก PG ช่วยให้การเล่นมีความมั่นใจและสนุกมากขึ้น เหมาะสำหรับการเล่นระยะยาว.
seo partners prodvizhenie-sajtov-v-moskve2.ru .
п»їJust now, I stumbled upon a great page regarding cheap Indian generics. It details WHO-GMP protocols for ED medication. For those interested in reliable shipping to USA, check this out: п»їkisawyer.us.com. Hope it helps.
такой antminer s21 hydro
продвижение наркологии seo-kejsy8.ru .
go to the website https://cryptoswap.cc
http://maps.google.com.mx/url?q=https://t.me/officials_7k/647
explanation https://swapcrypto.biz/
налогообложение компаний в эстонии https://financeprofessional.ee .
п»їTo be honest, I came across an informative page about Indian Pharmacy exports. The site discusses WHO-GMP protocols on prescriptions. In case you need reliable shipping to USA, visit this link: п»їhttps://kisawyer.us.com/# best india pharmacy. Might be useful.
Загляните за кулисы главных бизнес-решений — без воды, без цензуры,
только суть.
Наше СМИ — для тех, кто не просто следит за экономикой, а формирует её.
Каждый день — глубокая аналитика рынков, разборы стратегий топ-компаний,
эксклюзивные интервью с предпринимателями и инвесторами, которые меняют
правила игры. Здесь нет «жёлтых» заголовков — только факты, цифры и тренды,
которые работают *сегодня*.
Вы получаете не просто новости, а **инструмент для принятия решений**:
— Какие ниши взрываются в 2026 году
— Где искать финансирование, если банки закрыли кредиты
— Почему одни стартапы растут на 300%, а другие исчезают за месяц
— Какие регуляторные изменения уже сейчас влияют на ваш бизнес
Мы читаем между строк законов, отчётов и презентаций, чтобы вы тратили
время не на поиск информации, а на её применение. Наша аудитория — основатели
компаний, CFO, владельцы среднего и крупного бизнеса, а также профессионалы,
которые строят карьеру в финансах, технологиях и управлении.
Подключайтесь к сообществу, которое опережает рынок на шаг.
Подписывайтесь — и первыми узнавайте, куда двигаться дальше.
**Бизнес-СМИ, которому доверяют те, кто создаёт будущее.**
Читайте. Анализируйте. Действуйте.
Заходите на сайт дв2025.рф
Immerse yourself in the world of excitement and winnings withvalor casino,where every spin brings pleasure and a chance to win a big jackpot.
Valor Casino stands as a premier destination for gaming enthusiasts seeking excitement and luxury.
гибридная структура сайта гибридная структура сайта .
п»їRecently, I found a useful resource concerning ordering meds from India. It details WHO-GMP protocols for generic meds. In case you need reliable shipping to USA, take a look: п»їhttps://kisawyer.us.com/# buy prescription drugs from india. Might be useful.
плазменные медицинские стерилизаторы плазменные медицинские стерилизаторы .
п»їTo be honest, I discovered a useful page concerning Indian Pharmacy exports. The site discusses how to save money on prescriptions. For those interested in factory prices, go here: п»їkisawyer.us.com. Cheers.
получить короткую ссылку google получить короткую ссылку google .
Try your luck with jili casino and win a big prize today!
Players can enjoy diverse games on this service that combine fun with winning opportunities.
п»їTo be honest, I discovered an interesting resource concerning generic pills from India. It explains the manufacturing standards on prescriptions. For those interested in Trusted Indian sources, visit this link: п»їhttps://kisawyer.us.com/# Online medicine home delivery. Hope it helps.
Just wanted to share, a detailed analysis on Mexican Pharmacy safety. The author describes pricing differences for generics. Link: п»їpharmacy mexico.
777 bet online casino and dive into the world of gambling with unique offers!
One of the great advantages of playing at 777bet is the availability of attractive bonuses and promotions.
Check out our new game on alo789 link, to try your luck and win big prizes!
Creating an account on alo789 involves filling out a simple registration form.
this page https://lumi-wallet.io
п»їRecently, I found a helpful resource about ordering meds from India. It covers the manufacturing standards when buying antibiotics. In case you need Trusted Indian sources, read this: п»їpharmacy website india. Might be useful.
п»їJust now, I came across a great report concerning ordering meds from India. The site discusses CDSCO regulations on prescriptions. In case you need Trusted Indian sources, go here: п»їtop 10 pharmacies in india. Good info.
нажмите vodkabet онлайн казино
сюда kush casino
п»їRecently, I discovered a useful resource about Indian Pharmacy exports. The site discusses CDSCO regulations on prescriptions. If anyone wants Trusted Indian sources, visit this link: п»їdetails. Worth a read.
производство кухонь в спб на заказ http://kuhni-na-zakaz-5.ru .
магазин dyson отзывы магазин dyson отзывы .
Try your luck at an online casino spingo88 and enjoy exciting games.
Customers receive excellent value through thoughtfully designed pricing tiers.
продолжить войти на vbet poker
Главная vodkabet прямо сейчас
dyson пылесос купить интернет ofitsialnyj-sajt-dn-1.ru .
dyson магазин в спб ofitsialnyj-sajt-dn.ru .
дайсон стайлер для волос купить цена с насадками официальный сай… fen-d-12.ru .
дайсон стайлер для волос с насадками официальный сайт цена купит… дайсон стайлер для волос с насадками официальный сайт цена купит… .
фен дайсон оригинал купить официальный stajler-dsn.ru .
пылесос дайсон v15 absolute купить pylesos-dn-1.ru .
купить стайлер дайсон краснодар fen-dn-kupit-13.ru .
стайлер для волос дайсон цена с насадками официальный сайт купит… стайлер для волос дайсон цена с насадками официальный сайт купит… .
дайсон пылесос беспроводной цены дайсон пылесос беспроводной цены .
купить аккумулятор пылесос dyson pylesos-dn.ru .
пылесос дайсон купить в уфе пылесос дайсон купить в уфе .
нажмите здесь кракен onion
Источник кра
накрутка подписчиков в телеграм бесплатно купить подписчиков в тг
выпрямитель дайсон airstrait ht01 купить в волгограде dsn-vypryamitel-1.ru .
дайсон выпрямитель с феном дайсон выпрямитель с феном .
Just now, I wanted to get antibiotics for a tooth infection and stumbled upon Amoxicillin Express. You can get generic Amoxil with express shipping. If you are in pain, visit this link: AmoxicillinExpress Store. Hope it helps.
дайсон выпрямитель для волос купить в спб дайсон выпрямитель для волос купить в спб .
выпрямитель dyson hs07 vypryamitel-dn-kupit-1.ru .
Lately, I wanted to get Amoxicillin for a toothache and discovered a great pharmacy. It offers Amoxicillin 500mg overnight. For fast relief, visit this link: amoxicillin 500mg price. Best prices.
п»їActually, I wanted to buy antibiotics quickly and stumbled upon a reliable pharmacy. They let you buy antibiotics without a prescription legally. In case of a bacterial infection, try here. Express delivery available. Link: http://antibioticsexpress.com/#. Get well soon.
Try your luck and win big in slotgpt casino!
One of the key features of SlotGPT Casino is its personalized game recommendations.
Recently, I had to find anti-parasitic meds medication and discovered this source. You can get genuine Ivermectin without a prescription. For treating scabies quickly, check this out: https://ivermectinexpress.xyz/#. Cheers
Техническое обслуживание грузовых и коммерческих автомобилей и спецтехники. Снабжение и поставки комплектующих для грузовых автомобилей, легкового коммерческого транспорта на бортовой платформе ВИС lada: https://ukinvest02.ru/
где купить выпрямитель дайсон vypryamitel-dsn-kupit.ru .
выпрямитель дайсон купить в москве выпрямитель дайсон купить в москве .
Hi! Just wanted to share an awesome resource for those who need pills fast. This store offers huge discounts on all meds. To save money, take a look: online drugstore. Cheers.
https://t.me/s/kazino_s_MINIMALNYM_DEPOZITOM
https://t.me/s/kazino_s_MINIMALNYM_DEPOZITOM
check my blog https://betplay.sh/
hop over to this website https://cryptoswap.cc
Actually, I had to find scabies treatment pills and discovered this reliable site. They sell human grade meds without a prescription. For treating scabies effectively, visit this link: ivermectin 3mg price. Safe and secure
read what he said jaxx app
перепланировка квартиры проектные организации proekt-pereplanirovki-kvartiry20.ru .
где согласовать перепланировку pereplanirovka-kvartir4.ru .
купить выпрямитель dyson оптом vypryamitel-dsn-kupit-4.ru .
Try your luck and win big with big baazi casino app.
Additionally, Big Baazi operates under strict licensing regulations that uphold fairness and transparency.
this post jaxx liberty wallet
Step into a thrilling gambling experience with lavagame and start testing your luck today.
Community engagement is a vital part of Lavagame’s success.
курсовая работа купить москва kupit-kursovuyu-42.ru .
написание учебных работ написание учебных работ .
профессиональное продвижение сайтов профессиональное продвижение сайтов .
помощь курсовые помощь курсовые .
internet seo prodvizhenie-sajtov-v-moskve111.ru .
1win bonusu necə almaq olar [url=www.1win5762.help]1win bonusu necə almaq olar[/url]
seo агентство seo агентство .
курсовой проект купить цена kupit-kursovuyu-41.ru .
click this https://exponent.my/
Selamlar, sağlam casino siteleri bulmak istiyorsanız, bu siteye kesinlikle göz atın. Lisanslı firmaları ve fırsatları sizin için listeledik. Güvenli oyun için doğru adres: https://cassiteleri.us.org/# siteyi incele bol şanslar.
раскрутка сайта франция цена prodvizhenie-sajtov-v-moskve214.ru .
продвижение сайтов во франции prodvizhenie-sajtov-v-moskve113.ru .
important link https://gofundmeme.sbs/
усиление ссылок переходами prodvizhenie-sajtov-v-moskve223.ru .
Bocoran slot gacor malam ini: mainkan Gate of Olympus atau Mahjong Ways di Bonaslot. Website ini gampang menang dan aman. Promo menarik menanti anda. Akses link: п»їslot gacor raih kemanangan.
1win promo kod [url=1win5762.help]1win promo kod[/url]
seo агентство seo агентство .
задвижка 30с41нж 50 задвижка 30с41нж
комплексное продвижение сайтов москва комплексное продвижение сайтов москва .
этот контент https://krab4a.at/
частный seo оптимизатор частный seo оптимизатор .
продвижение по трафику продвижение по трафику .
Check out the latest game updates atgreat wall 99.
Their encryption technology ensures that all transactions remain confidential.
Hi all, Just now stumbled upon a useful Indian pharmacy for affordable pills. If you want to buy ED meds safely, this site is the best place. You get wholesale rates guaranteed. More info here: indian pharmacy. Cheers.
internet seo poiskovoe-prodvizhenie-sajta-v-internete-moskva.ru .
заказать продвижение сайта в москве заказать продвижение сайта в москве .
Главная https://krab4a.at/
раскрутка сайта франция цена раскрутка сайта франция цена .
seo аудит веб сайта prodvizhenie-sajtov-v-moskve235.ru .
интернет раскрутка kompanii-zanimayushchiesya-prodvizheniem-sajtov.ru .
Hello, Just now came across an amazing online drugstore for cheap meds. If you want to buy generic pills at factory prices, this site is the best place. You get fast shipping worldwide. Visit here: indian pharmacy. Cheers.
компании занимающиеся продвижением сайтов компании занимающиеся продвижением сайтов .
digital маркетинг блог statyi-o-marketinge2.ru .
как продвигать сайт статьи statyi-o-marketinge.ru .
хмао сво [url=https://dobrovolcysvo.ru]подписать контракт на сво в хмао[/url]
more jaxx wallet review
этот контент https://krab4a.at/
code promo melbet melbet telecharger
Greetings, I recently stumbled upon an amazing online drugstore for cheap meds. If you need generic pills at factory prices, this site is the best place. It has lowest prices guaranteed. More info here: https://indiapharm.in.net/#. Good luck.
гидроизоляция подвала цена за м2 гидроизоляция подвала цена за м2 .
Hey there, Just now discovered a trusted website to buy medication. For those seeking and want generic drugs, Pharm Mex is the best option. Fast shipping plus secure. Link is here: buy meds from mexico. Hope this helps!
школа seo школа seo .
школа seo школа seo .
seo интенсив seo интенсив .
Hi guys, Lately came across a reliable Mexican pharmacy for affordable pills. If you want to save money and need meds from Mexico, Pharm Mex is highly recommended. Fast shipping and it is safe. Link is here: cheap antibiotics mexico. Get well soon.
сырость в подвале многоквартирного дома gidroizolyacziya-podvala-iznutri-czena9.ru .
Производим пластиковые https://zavod-dimax.ru окна и выполняем профессиональную установку. Качественные материалы, точные размеры, быстрый монтаж и гарантийное обслуживание для комфорта и уюта в помещении.
useful content
https://russian-traditional-clothes.com
PSYCHEDELICS DISPENSARY
TRIPPY 420 ROOM operates as a dedicated online psychedelics dispensary, focused on offering carefully crafted and top-quality medical products across multiple categories.
Before placing an order for psychedelic, cannabis, stimulant, dissociative, or opioid products online, customers are presented with a clear structure covering product availability, delivery options, and support. The catalog includes 200+ products across multiple formats.
Shipping is quoted based on package size and destination, with regular and express options available. All orders are backed by a hassle-free returns policy with particular attention to privacy and security. The service highlights guaranteed worldwide stealth delivery, with no added fees. Orders are fully guaranteed to support reliable delivery.
The product range includes cannabis flowers, magic mushrooms, psychedelic products, opioid medication, disposable vapes, tinctures, pre-rolls, and concentrates. All products are shown with transparent pricing, including defined price ranges where multiple variants are available. Additional informational content is included, such as guides like “How to Dissolve LSD Gel Tabs”, along with direct options to buy LSD gel tabs and buy psychedelics online.
TRIPPY 420 ROOM operates from the United States, California, and provides multiple contact channels, such as phone, WhatsApp, Signal, Telegram, and email. The platform promotes round-the-clock express psychedelic delivery, framing the service around accessibility, privacy, and ongoing customer support.
Bahis severler selam, bu popüler site kullanıcıları için önemli bir bilgilendirme paylaşıyorum. Herkesin bildiği üzere site giriş linkini erişim kısıtlaması nedeniyle sürekli taşıdı. Siteye ulaşım sorunu yaşıyorsanız çözüm burada. Çalışan Casibom giriş adresi artık paylaşıyorum Casibom Kayıt Paylaştığım bağlantı üzerinden direkt siteye girebilirsiniz. Ek olarak kayıt olanlara verilen hoşgeldin bonusu fırsatlarını da inceleyin. Lisanslı slot keyfi sürdürmek için Casibom doğru adres. Tüm forum üyelerine bol şans dilerim.
смотреть здесь сайт водка бет
Gençler, Grandpashabet yeni adresi açıklandı. Giremeyenler şu linkten giriş yapabilir https://grandpashabet.in.net/#
Производим торговую мебель https://woodmarket-for-business.ru для розничного бизнеса и сетевых магазинов. Функциональные конструкции, современный дизайн, точные размеры и полный цикл работ — от проекта до готового решения.
Нужно авто? авто из японии на заказ каталог поиск, проверка, оформление и доставка авто из разных стран. Прозрачные условия, помощь на всех этапах и сопровождение сделки до получения автомобиля.
Matbet TV giriş adresi arıyorsanız doğru yerdesiniz. Maç izlemek için: Matbet İzle Yüksek oranlar bu sitede. Gençler, Matbet yeni adresi açıklandı.
https://t.me/s/russia_casino_1win
ремонт бетонных конструкций трещины ремонт бетонных конструкций трещины .
Нужен проектор? projector24.ru/ большой выбор моделей для дома, офиса и бизнеса. Проекторы для кино, презентаций и обучения, официальная гарантия, консультации специалистов, гарантия качества и удобные условия покупки.
Matbet TV güncel linki lazımsa doğru yerdesiniz. Sorunsuz için tıkla: Matbet Twitter Yüksek oranlar bu sitede. Arkadaşlar, Matbet bahis yeni adresi belli oldu.
Herkese selam, Vay Casino oyuncular? ad?na onemli bir bilgilendirme paylas?yorum. Malum platform giris linkini tekrar guncelledi. Giris sorunu varsa panik yapmay?n. Son Vaycasino giris linki su an burada: https://vaycasino.us.com/# Paylast?g?m baglant? uzerinden direkt hesab?n?za erisebilirsiniz. Guvenilir casino deneyimi icin Vaycasino dogru adres. Herkese bol sans temenni ederim.
Arkadaşlar, Grandpashabet Casino yeni adresi belli oldu. Adresi bulamayanlar buradan giriş yapabilir https://grandpashabet.in.net/#
гидроизоляция подвала проникающая gidroizolyacziya-podvala-samara4.ru .
гидроизоляция подвала материалы гидроизоляция подвала материалы .
check my reference https://sites.google.com/node-protocol.org/terra-classic
Read Full Report https://sites.google.com/node-protocol.org/terra-classic
кухни спб кухни спб .
купить кухню на заказ спб kuhni-spb-28.ru .
Детский Доктор: https://kidsmedic.ru Специализированный медицинский центр для детей. Квалифицированная помощь педиатров и узких специалистов для здоровья вашего ребенка с первых дней жизни.
прогноз доли выбора карточка прогноз доли выбора карточка .
Полесская ЦРБ: https://polesskcrb.ru Официальный портал центральной районной больницы Калининградской области. Информация об услугах, расписание врачей и важные новости здравоохранения для жителей региона.
кухни под заказ в спб kuhni-spb-28.ru .
узнать больше krab4.at mirror
Buy LSD Gel Tabs
TRIPPY 420 ROOM is presented as a full-service psychedelics dispensary online, focused on offering carefully crafted and top-quality medical products across several product categories.
Before buying psychedelic, cannabis, stimulant, dissociative, or opioid products online, users are provided with a clear service structure that outlines product availability, shipping options, and customer support. The store features more than 200 products covering different formats and preferences.
Shipping is quoted based on package size and destination, with regular and express options available. Each order includes access to a hassle-free returns system with particular attention to privacy and security. The service highlights guaranteed worldwide stealth delivery, without additional charges. Orders are fully guaranteed to support reliable delivery.
The catalog spans cannabis flowers, magic mushrooms, psychedelic products, opioid medications, disposable vapes, tinctures, pre-rolls, and concentrates. Items are presented with clear pricing, including defined price ranges where multiple variants are available. Informational content is also available, with references including “How to Dissolve LSD Gel Tabs”, along with direct options to buy LSD gel tabs and buy psychedelics online.
TRIPPY 420 ROOM operates from the United States, California, and provides multiple contact channels, such as phone, WhatsApp, Signal, Telegram, and email. The service highlights 24/7 express psychedelic delivery, positioning the dispensary around accessibility, discretion, and consistent customer support.
Gencler, Grandpashabet Casino son linki ac?kland?. Adresi bulamayanlar buradan giris yapabilir Giris Yap
интернет krab4.at маркет
Arkadaşlar selam, Casibom sitesi kullanıcıları için kısa bir bilgilendirme paylaşıyorum. Bildiğiniz gibi bahis platformu domain adresini erişim kısıtlaması nedeniyle tekrar değiştirdi. Giriş hatası varsa doğru yerdesiniz. Resmi Casibom güncel giriş linki artık burada Casibom Giriş Paylaştığım bağlantı ile vpn kullanmadan siteye erişebilirsiniz. Ek olarak yeni üyelere verilen yatırım bonusu fırsatlarını da inceleyin. En iyi bahis keyfi sürdürmek için Casibom tercih edebilirsiniz. Herkese bol şans dilerim.
visit our website https://toast-wallet.net/
Matbet TV giriş linki arıyorsanız işte burada. Hızlı için tıkla: Matbet Yüksek oranlar bu sitede. Gençler, Matbet yeni adresi belli oldu.
Кент казино подходит для разных форматов игры. Можно выбрать короткие сессии или длительную игру. Платформа стабильно работает под нагрузкой. Игры не прерываются. Это делает процесс комфортным: kent casino
подробнее tripscan
Visit ramly888 online casino to experience exciting slot games and attractive bonuses.
Consequently, many users choose Ramly888 for its convenience.
Good day! Would you mind if I share your blog with my myspace group? There’s a lot of people that I think would really enjoy your content. Please let me know. Thank you
официальный сайт RioBet Casino
i tours tury-v-piter.ru .
Hello mọi người, nếu anh em đang kiếm cổng game không bị chặn để giải trí Casino thì xem thử trang này nhé. Đang có khuyến mãi: bj88. Về bờ thành công.
cum depun pe mostbet cu card [url=https://mostbet2008.help/]https://mostbet2008.help/[/url]
бесплатные ссылки
купить дайсон в санкт петербурге dn-pylesos-2.ru .
Балясины купить
Hi cac bac, ngu?i anh em nao c?n trang choi xanh chin d? cay cu?c Casino thi xem th? d?a ch? nay. Dang co khuy?n mai: https://gramodayalawcollege.org.in/#. Chi?n th?ng nhe.
дайсон пылесос dn-pylesos-kupit-4.ru .
сервис дайсон в спб сервис дайсон в спб .
Chao anh em, n?u anh em dang ki?m san choi d?ng c?p d? choi N? Hu d?ng b? qua d?a ch? nay. N?p rut 1-1: Nha cai Dola789. Hup l?c d?y nha.
dyson пылесос беспроводной купить спб dn-pylesos-kupit-6.ru .
dyson пылесос купить pylesos-dn-kupit-6.ru .
Play exciting games and experience real fun at jqk malaysia.
To grasp jqk fully, one must learn its basic concepts.
dyson пылесос купить спб pylesos-dn-kupit-7.ru .
dyson спб dyson спб .
санкт петербург магазин дайсон pylesos-dn-kupit-7.ru .
mostbet KG сайт [url=mostbet2035.help]mostbet KG сайт[/url]
пылесосы дайсон спб pylesos-dn-kupit-6.ru .
пылесосы дайсон санкт петербург dn-pylesos-kupit-6.ru .
пылесос дайсон v15 купить в спб pylesos-dn-6.ru .
https://iver.us.com/# Iver Protocols Guide
read here https://kittenswap.cc/
To increase your chances of success in the game, use proven strategies and angka jitu toto.
For those who follow lottery trends, predicting with angka jitu toto is highly sought after.
https://amitrip.us.com/# Amitriptyline
цветы на дом москва дешево с бесплатной доставкой Служба доставки цветов Москва
fertility pct guide fertility pct guide where buy clomid
1x giri? 1xbet-35.com .
1xbet tr 1xbet tr .
bahis sitesi 1xbet 1xbet-giris-21.com .
https://fertilitypctguide.us.com/# how can i get cheap clomid for sale
check out here https://jaxxwallet-web.org/
read more jaxx liberty wallet
visit https://jaxxwallet-web.org
Dive into the exciting world of zodiac casino — your key to thrilling games and generous bonuses.
Known for its sleek design and user-friendly interface, Zodiac Casino attracts players worldwide.
1xbet giri? yapam?yorum 1xbet-turkiye-1.com .
birxbet 1xbet-yeni-giris-2.com .
money x рабочий сайт t.me/moneyx_tg .
Для тех кто готов к решительным действиям контрактная служба открывает возможности. Стабильный доход и понятные условия. Все выплаты официальные. Это шаг к уверенности. Начни оформление сегодня – служба по контракту в ханты мансийске
новости про машины avtonovosti-3.ru .
1win двухфакторная авторизация [url=https://1win93056.help]https://1win93056.help[/url]
1 x bet 1 x bet .
Для килимів https://cleaninglviv.top/ підходить
https://spasmreliefprotocols.shop/# antispasmodic medication
1win ставки в Киргизии [url=http://1win21567.help/]1win ставки в Киргизии[/url]
Воплощаем архитектурные идеи в реальность! Разработка проектов для жилых и коммерческих объектов – это гарантия качества и безопасности.
1xbet giri? linki 1xbet-mobil-1.com .
prilosec side effects: omeprazole – buy prilosec
автоновости автоновости .
t.me/s/top_onlajn_kazino_rossii t.me/s/top_onlajn_kazino_rossii .
1win lucky jet играть [url=1win74125.help]1win74125.help[/url]
туры всё включено со скидкой tury-i-puteshestviya-promokody-i-skidki-1.ru .
журналы для автолюбителей avto-zhurnal-1.ru .
car журнал car журнал .
our website cheap dma hardware
Check This Out
bf6 dma radar
можно проверить ЗДЕСЬ Уменьшение налога Усн
журнал про авто журнал про авто .
Nausea Care US: Nausea Care US – Nausea Care US
see it here web3
нажмите здесь кфг миднайт
электрокарнизы москва электрокарнизы москва .
нейросеть для создания реферата в ворде бесплатно
уличные рулонные шторы rulonnye-shtory-s-elektroprivodom50.ru .
туры всё включено со скидкой tury-i-puteshestviya-promokody-i-skidki-1.ru .
школа дистанционного обучения shkola-onlajn-23.ru .
???????????????????!https://lantu-jp.com/??????????????????????????????????????????????????????????????????????????????????????????????????????LANTU????????????????????
https://bajameddirect.com/# BajaMed Direct
ломоносов школа ломоносов школа .
онлайн-школа с аттестатом бесплатно онлайн-школа с аттестатом бесплатно .
view https://seenfil.com
read the article
battery bet aviator
электрокарниз двухрядный электрокарниз двухрядный .
More Help
russian traditional clothing
автоматические жалюзи на окна заказать автоматические жалюзи на окна заказать .
автоматические гардины для штор karnizy-s-elektroprivodom77.ru .
1 вин официальный сайт 1win leon
В глубинах холодного моря жил древний Кракен, охранявший зеркала памяти. Эти зеркала не отражали лица — они показывали страхи, мечты и забытые решения каждого, кто осмеливался взглянуть в их гладь. Когда шторм поднимался, щупальца Кракена тянулись к поверхности, защищая зеркала от жадных глаз. Моряки верили: если зеркало треснет, море потеряет равновесие. Поэтому легенда учила уважать тайны глубин и помнить, что не каждое отражение стоит искать.
?????????????????????????!https://xgaghb-jp.com/??????????????????????????????????????MP3??????????????????????????????????????????????????????????XGAGHB????????????????????????
мостбет валюта сом [url=https://www.mostbet72461.help]мостбет валюта сом[/url]
дистанционное школьное образование shkola-onlajn-24.ru .
рулонные шторы крепление на окно rulonnaya-shtora-s-elektroprivodom.ru .
1win casino con oxxo [url=http://1win5773.help/]http://1win5773.help/[/url]
top 10 pharmacies in india: top 10 pharmacies in india – indian pharmacy
BajaMed Direct: mexican medicine – BajaMed Direct
жалюзи с мотором жалюзи с мотором .
nov? ?esk? online casino nov? ?esk? online casino .
BajaMed Direct: farmacia mexicana en linea – BajaMed Direct
online shopping pharmacy india reputable indian pharmacies best india pharmacy
US Meds Outlet: no rx pharmacy – US Meds Outlet
vavada bonus codzienny [url=https://vavada2005.help]vavada bonus codzienny[/url]
Hey everyone! If you’re planning an outdoor adventure, check out https://mycamelcrown.com/. You’ll find comfy, durable gear like hiking shoes, jackets, and even camping tents. They blend style with functionality, so you can stay comfy and look good while exploring. Definitely worth a look if you love the outdoors!
Попробуйте свои силы в лучших играх на alpha66 online и почувствуйте настоящий азарт прямо сейчас!
Beyond its robust features, Alpha66 offers committed customer support to guide users through any challenges.
http://smartgenrxusa.com/# Smart GenRx USA
https://sertralineusa.com/# sertraline zoloft
online pharmacy pharmacy no prescription required legit non prescription pharmacies
pin-up app apuestas [url=www.pinup2005.help]www.pinup2005.help[/url]
Aablexema’s accessories and fashion items stand out for their originality and quality. Perfect for those who want to add personality to their look. Check out their offerings at https://theaablexema.com.
https://sertralineusa.shop/# zoloft generic
жалюзи для пластиковых окон с электроприводом жалюзи для пластиковых окон с электроприводом .
aviator 1вин [url=https://1win17384.help/]https://1win17384.help/[/url]
https://ivertherapeutics.com/# where to buy stromectol
Завжди хотіла навчитися робити смачні соуси. Нарешті знайшла корисний матеріал про соуси до страв – тепер мої страви стали ще смачнішими!
zoloft no prescription: sertraline generic – zoloft cheap
Всем привет!
Нарыл интересную инфу.
Решил поделиться.
Смотрите тут:
кракен онион
Вроде норм.
casino bonus za registraci casino-cz-9.com .
casino online casino online .
nov? ?esk? online casino nov? ?esk? online casino .
zoloft without rx: zoloft generic – zoloft tablet
nov? online casino nov? online casino .
http://sertralineusa.com/# sertraline zoloft
blackjack online casino-cz-11.com .
https://sertralineusa.com/# zoloft no prescription
Iver Therapeutics: ivermectin 6mg dosage – ivermectin generic
Some days demand moving fast between tasks and relaxation. https://getruxury.com/ folding desk folds away neatly when I’m done. The surface is just the right size for my laptop and notes. It quietly makes transitions in the day feel natural.
Hallo! Bei https://diegodallapalma.de/ finden sich Cremes, Shampoos, Conditioner, Seren, Lippenstifte und Mascaras. Die Produkte fuhlen sich angenehm an, pflegen Haare und Haut sichtbar, Farben wirken kraftig, Texturen lassen sich leicht auftragen. Ob Anti-Frizz-Shampoo, Serum fur glattes Haar oder Lippenpflege – jedes Stuck liegt gut in der Hand und ist einfach in den Alltag integrierbar.
Click This Link https://mixmy.money/
Hallo! https://miioto.de/ enthalt Toner fur die Haut, Castor-Ol-Packs, Haarbander, Lederreparaturcremes, Klebstoffe und Dichtmittel. Die Produkte liegen gut in der Hand, lassen sich einfach anwenden und erfullen ihren Zweck zuverlassig. Ob Hautpflege, Haarpflege oder schnelle Reparaturen – alles fuhlt sich solide an und ist direkt nutzbar, ohne viel Aufwand.
no prescription pharmacy paypal: escrow pharmacy online – online pharmacy usa
медицинское оборудование медицинское оборудование .
http://ivertherapeutics.com/# Iver Therapeutics
mostbet пополнить сомами [url=https://mostbet90387.help]https://mostbet90387.help[/url]
требуется дизайнер trudvsem.kz .
mostbet stavka qoidalari [url=mostbet69573.help]mostbet69573.help[/url]
Hallo Raumgestalter und Heimliebhaber! https://srdcaim.de/ bietet alles, was Raume lebendig macht. Von cleveren Eckschranken fur Badezimmer, die Ordnung schaffen, bis zu soliden Holzbar-Tischen, die Gemutlichkeit und Funktion verbinden. Acryl-Displays ordnen und prasentieren Muster perfekt, wahrend robuste Entwasserungssysteme drau?en Sicherheit und Struktur bieten. Jedes Produkt bringt Design, Nutzen und ein Stuck Inspiration in den Alltag.
mostbet бонусы в Казахстане [url=www.mostbet46809.help]mostbet бонусы в Казахстане[/url]
Трезвый выбор http://facewoman.ru/vyvod-iz-zapoya-v-donecke.html/ .
медоборудование медоборудование .
trezviy-vibor https://www.samatiha.ru/anonimnyj-narkolog-na-dom-v-krasnodare-kak-vybrat-sluzhbu-i-ne-oshibitsya/ .
Трезвый выбор http://samatiha.ru/anonimnyj-narkolog-na-dom-v-krasnodare-kak-vybrat-sluzhbu-i-ne-oshibitsya/ .
купить тяговый аккумулятор
http://neuroreliefusa.com/# Neuro Relief USA
внедрение 1с 8 3 внедрение 1с 8 3 .
http://sertralineusa.com/# generic zoloft
https://smartgenrxusa.shop/# Smart GenRx USA
sertraline generic: zoloft cheap – sertraline generic
строительные нормы и правила rekonstrukcziya-zdanij.ru .
цементация грунта цена ukreplenie-gruntov.ru .
Як змінювалася [url=https://library.myusefulnotes.website/]дитяча література[/url] протягом століть?
sertraline generic: Sertraline USA – sertraline
купить тяговый аккумулятор
best virtual number service github.com/sms-activate-login .
усиление грунта геополимерами ukreplenie-gruntov-1.ru .
http://neuroreliefusa.com/# Neuro Relief USA
https://sertralineusa.shop/# zoloft cheap
укрепление грунта укрепление грунта .
инъекционное усиление грунта цена ukreplenie-gruntov.ru .
курсовая работа недорого курсовая работа недорого .
Smart GenRx USA: foreign pharmacy no prescription – Smart GenRx USA
Сайт доставка цветов
[b]Помогаем выразить чувства через красивые цветы[/b]
Neuro Relief USA: gabapentin medication – Neuro Relief USA
курсовые заказ курсовые заказ .
http://ivertherapeutics.com/# ivermectin 3mg pill
canadian pharmacy viagra 50 mg: Smart GenRx USA – canadadrugpharmacy com
здесь https://krab6a.cc
заказать задание kupit-kursovuyu-68.ru .
http://neuroreliefusa.com/# neurontin 50mg tablets
решение курсовых работ на заказ решение курсовых работ на заказ .
курсовые работы заказать курсовые работы заказать .
https://sertralineusa.com/# sertraline zoloft
заказать качественную курсовую заказать качественную курсовую .
генерация nejroset-dlya-ucheby.ru .
купить курсовую работу купить курсовую работу .
умная нейросеть для учебы nejroset-dlya-ucheby.ru .
cost of ivermectin pill: generic ivermectin for humans – ivermectin brand
https://ivertherapeutics.com/# how much does ivermectin cost
Подробнее здесь https://reim.ink/
заказать курсовую срочно заказать курсовую срочно .
sms activate alternatives sms activate alternatives .
sms activate sms activate .
узаконить перепланировку москва pereplanirovka-kvartir9.ru .
ии для школьников и студентов ии для школьников и студентов .
нейросеть для студентов нейросеть для студентов .
нейросеть реферат онлайн нейросеть реферат онлайн .
нейросеть текст для учебы nejroset-dlya-ucheby-8.ru .
My freind told me about babu88 like a month ago and I was like whatever but then I finaly checked it out and honestly its pretty solid, no complaints from me, way better than what I was using before it
нейросеть для учебы нейросеть для учебы .
ии для учебы студентов nejroset-dlya-ucheby-6.ru .
узаконивание перепланировки pereplanirovka-kvartir9.ru .
сайт для рефератов сайт для рефератов .
мелбет регистрация официальный сайт мелбет регистрация официальный сайт .
ии реферат ии реферат .
мелбет на айфон мелбет на айфон .
melbet зеркало скачать на айфон melbet зеркало скачать на айфон .
pg slot
PG Slot แพลตฟอร์มเกมสล็อตยอดนิยม ใช้งานง่าย ฝากถอนรวดเร็ว
คำค้นหา pg slot มาแรงในช่วงนี้ ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น ผู้ให้บริการเกมสล็อตที่มาแรง ด้าน กราฟิก ความ เสถียร และ โอกาสรับกำไรที่ดี เกมของ PG ออกแบบโดยทีมงานมืออาชีพ ที่รองรับการเล่นทั้งบน สมาร์ทโฟน และ คอมพิวเตอร์
ข้อดี ของ PG Slot
PG Slot เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ โหลดเร็ว เล่นผ่าน ระบบอัตโนมัติ และรองรับ ทั้ง iOS และ Android ไม่ต้องดาวน์โหลดแอป ผู้เล่นสามารถเข้าเล่นผ่าน เว็บเบราว์เซอร์ ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ เอฟเฟกต์ 3 มิติ ให้ความคมชัด พร้อมเอฟเฟกต์ สวยงาม
คุณสมบัติหลักของเกม สล็อต PG ได้แก่
มีรอบโบนัสให้ลุ้นบ่อย
Multiplier
เล่นฟรีก่อนเติมเงิน
ใช้งานภาษาไทยง่าย
ระบบการเงินรวดเร็ว ไม่ต้องรอนาน
แพลตฟอร์ม สล็อต PG ส่วนใหญ่รองรับ การฝาก-ถอน ออโต้ตลอด 24 ชม. ขั้นต่ำเริ่มต้นเพียง 10 บาท ขึ้นอยู่กับ เงื่อนไขของเว็บไซต์ การทำรายการใช้เวลา ไม่กี่วินาที ผ่าน คิวอาร์โค้ด หรือระบบ Mobile Banking ทำให้ธุรกรรมเป็นไปอย่าง ไม่สะดุด
ประเภทเกมยอดนิยม ใน pg slot
เกม สล็อต PG มีธีมหลากหลาย เช่น
ธีม แฟนตาซี
ธีม Adventure
ธีม ความมั่งคั่ง
ธีม ธรรมชาติ
หลายคนชอบเกมที่โบนัสเข้าไว พร้อมระบบ โบนัสรอบพิเศษ และ ระบบจ่ายคุ้มค่า เหมาะกับทั้ง ผู้เล่นเริ่มต้น และ สายสล็อตจริงจัง
ความน่าเชื่อถือ
PG Slot พัฒนาในระบบสากล มีการ รักษาความปลอดภัย และใช้ระบบสุ่มผล RNG เพื่อให้ผลลัพธ์ โปร่งใส แพลตฟอร์มที่ให้บริการ PG Slot ควรมี ทีมซัพพอร์ต 24 ชม.
สรุป
PG Slot เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน โบนัสหลากหลาย และการทำธุรกรรมที่ ไว ผู้เล่นสามารถเริ่มต้นได้ ทันที ฝากถอนสะดวก และเลือกเกมได้ หลากหลายแนว เหมาะสำหรับ ผู้เล่นทุกสไตล์ ในโลกของเกมสล็อตออนไลน์
мелбет вход в личный кабинет http://www.gamemelbet.ru .
https://certicanpharmacy.com/# canadian medications
999 baji
* Quick signup process
* No annoying popups
* Customer service actually responds
* Clean mobile app
* Fast transaction processing
pg slot
แพลตฟอร์ม TKBNEKO คาสิโนออนไลน์ ให้บริการ พื้นที่ออนไลน์ที่ทันสมัย ซึ่ง ผู้ที่สนใจ สามารถ ทดลองใช้งาน โลกแห่งเกมและความบันเทิง รวมถึง โอกาสสร้างรายได้แบบรวดเร็ว เว็บไซต์นี้ สร้างภาพลักษณ์ว่าเป็นสถานที่ที่ทุกคนสามารถกลายเป็นเจ้าของธุรกิจได้ เนื่องจาก มีความสะดวกสบายและใช้งานง่าย
หนึ่งใน ฟีเจอร์หลัก ของแพลตฟอร์มนี้คือ ระบบฝากและถอนเงิน ซึ่งมีขั้นต่ำในการเติมเงินเพียง 1 บาท และขั้นต่ำในการถอนเงินก็เช่นเดียวกันที่ 1 บาท เท่านั้น กระบวนการเติมเงินใช้เวลาเพียง 3 วินาที ทำให้แพลตฟอร์มนี้ รองรับธุรกรรมฉับไว นอกจากนี้ยัง ไม่กำหนดเพดานการถอน ซึ่งเป็น จุดเด่นที่ช่วยให้ TKBNEKO แตกต่างจากเว็บไซต์อื่นๆ
สำหรับการเติมเงิน สมาชิกสามารถสแกน QR Code เพื่อโอนเงิน ซึ่งเป็นระบบที่ ง่ายและสะดวกมากยิ่งขึ้น
แพลตฟอร์มนี้มีเกมให้เลือก หลากหลายประเภท เช่น สล็อต, เกมสด, กีฬา และ เกมยิงปลาออนไลน์ ผู้เล่นสามารถดูรายชื่อเกมทั้งหมดได้ผ่านตัวกรอง “All Games” ซึ่งช่วยให้ ผู้เล่นเลือกเกมที่ตรงกับความสนใจได้อย่างลงตัว
TKBNEKO มุ่งมั่นนำเสนอเกมที่ผ่านการรับรอง โดยร่วมมือกับ ผู้ให้บริการเกมที่ได้รับการรับรองจากสถาบันที่เชื่อถือได้ ซึ่งช่วยให้มั่นใจได้ว่า ผู้เล่นจะได้รับประสบการณ์ที่โปร่งใสและปลอดภัย
TKBNEKO ได้ผสานระบบการชำระเงินเข้ากับ เครือข่ายธนาคารชั้นนำ เช่น Krungthai Bank, Bangkok Bank, SCB, Kasikorn Bank, Thanachart Bank, GSB, TrueMoney Wallet, Citibank, UOB และ BAAC ทำให้การทำธุรกรรมทางการเงิน มีความสะดวกสบายและปลอดภัยมากยิ่งขึ้น
กล่าวโดยรวม TKBNEKO คือแพลตฟอร์มที่ ครบวงจรสำหรับเกมออนไลน์ สำหรับเกมออนไลน์และการเดิมพัน ด้วยเงื่อนไขขั้นต่ำที่ต่ำ การทำธุรกรรมที่รวดเร็ว และเกมให้เลือกมากมาย ทำให้แพลตฟอร์มนี้ รองรับผู้เล่นทุกระดับ สมัครใช้งานได้ทันที และ สัมผัสความสนุกในรูปแบบใหม่
read this article https://app-felxo.com
ии анализ креативов 60 секунд reklamnyj-kreativ9.ru .
blog Paxful login
глубинное водопонижение глубинное водопонижение .
читать ferma.cc
melbet бонус на депозит [url=https://melbet09342.help/]melbet бонус на депозит[/url]
mostbet ставки Кыргызстан [url=https://www.mostbet61527.help]https://www.mostbet61527.help[/url]
The platform demonstrates solid technical performance with responsive load times under 2 seconds and a well-structured UI that prioritizes user navigation. Mobile compatibility appears optimized across iOS and Android devices, though I noticed one minor rendering glitch on teh homepage. bajibagh app overall the infrastructure seems professionally maintaned
понижение уровня грунтовых вод понижение уровня грунтовых вод .
водопонижение иглофильтрами водопонижение иглофильтрами .
Ремонт однокомнатной квартиры в Москве: особенности, цены и советы
Ремонт однокомнатной квартиры в Москве — это ответственное мероприятие, которое требует тщательного планирования и профессионального подхода. Однокомнатная квартира представляет собой компактное пространство, где каждый квадратный метр имеет значение. Именно поэтому важно правильно организовать процесс ремонта, чтобы создать уютное и функциональное жилье.
дизайн интерьера заказать
¦ Особенности ремонта однокомнатной квартиры
Однокомнатные квартиры отличаются небольшими размерами помещений, что накладывает определенные ограничения на выбор материалов и дизайн интерьера. Однако это также открывает возможности для креативных решений и оптимального использования пространства. Вот некоторые ключевые моменты, которые следует учитывать при ремонте однокомнатной квартиры:
¦ Планировка и зонирование
ремонт загородного дома под ключ
– Планировка: Если позволяет конструкция здания, можно рассмотреть вариант перепланировки, чтобы увеличить полезную площадь помещения.
– Зонирование: Использование мебели-трансформеров, перегородок или декоративных элементов позволит разделить комнату на функциональные зоны (спальная зона, рабочая зона, гостиная).
¦ Выбор отделочных материалов
– Отделочные материалы: Важно выбирать качественные и долговечные материалы, которые будут соответствовать стилю интерьера и требованиям эксплуатации.
– Цветовая гамма: Светлые тона визуально расширяют пространство, делая квартиру более просторной и светлой.
ремонт дома цена
¦ Освещение
– Освещение: Правильное освещение играет важную роль в создании комфортной атмосферы. Рекомендуется использовать комбинированное освещение (общий свет + точечные светильники).
¦ Стоимость ремонта однокомнатной квартиры
Стоимость ремонта однокомнатной квартиры зависит от множества факторов, включая объем работ, качество используемых материалов и уровень профессионализма исполнителей. Средняя стоимость ремонта однокомнатной квартиры в Москве составляет от 500 тысяч рублей до 1 миллиона рублей. Рассмотрим подробнее, из чего складывается эта сумма:
¦ Основные расходы
– Демонтаж старых покрытий: удаление обоев, напольных покрытий, сантехники и электрики.
– Выравнивание стен и полов: шпаклевка, штукатурка, стяжка пола.
– Установка новых коммуникаций: электропроводка, водоснабжение, канализация.
– Отделочные работы: поклейка обоев, покраска, укладка плитки или ламината.
– Замена окон и дверей: установка пластиковых окон и межкомнатных дверей.
– Покупка мебели и техники: приобретение необходимой мебели и бытовой техники.
¦ Рекомендации по выбору подрядчика
При выборе подрядчика для ремонта однокомнатной квартиры следует обратить внимание на следующие критерии:
– Опыт работы: Убедитесь, что компания имеет опыт выполнения аналогичных проектов.
– Портфолио: Ознакомьтесь с примерами выполненных работ.
– Отзывы клиентов: Изучите отзывы предыдущих заказчиков.
– Договор: Заключайте договор, в котором будут прописаны сроки выполнения работ, стоимость и гарантии качества.
¦ Итоговые рекомендации
Ремонт однокомнатной квартиры в Москве — это возможность преобразить свое жилище и сделать его комфортным местом для проживания. Правильно спланированный и выполненный ремонт обеспечит вам уют и удобство на долгие годы. Не забывайте учитывать все нюансы и выбирайте проверенных профессионалов для реализации вашего проекта.
ремонт дома цена
https://designapartment.ru/dizajnerskij-remont/v-novostrojke/
pop over to this site proteção contra golpe do Pix e boleto falso
услуги по согласованию перепланировки услуги по согласованию перепланировки .
мост бет [url=http://mostbet61527.help]мост бет[/url]
try this betswap gg
http://mymexicanpharmacy.com/# mexicanrxpharm
meds from mexico mexican pharmacy online prescriptions from mexico
sms activation github.com/SMS-Activate-Alternatives .
My Mexican Pharmacy: mexican medicine – My Mexican Pharmacy
сколько стоит заказать кухню по размерам zakazat-kuhnyu-3.ru .
кухню заказать кухню заказать .
мостбет как вывести на кошелек [url=https://mostbet52718.help]https://mostbet52718.help[/url]
best price for viagra 100mg: over the counter sildenafil – Viagra without a doctor prescription Canada
современные кухни на заказ в спб kuhni-spb-41.ru .
купить заказать кухню купить заказать кухню .
заказать кухню по индивидуальному заказу zakazat-kuhnyu-1.ru .
Онлайн казино в телеграм Онлайн казино в телеграм .
заказать кухню цены zakazat-kuhnyu-2.ru .
US Pharma Index: legitimate online pharmacy – canadian pharmacy antibiotics
AWS caiu caiu.site .
Viagra tablet online: Sildenafil Price Guide – viagra canada
Що може бути смачніше, ніж риба? Особливо коли вона [url=https://kitchen.justtips.website/]чарівна[/url] і правильно приготована.
1win plinko strategiya [url=www.1win5763.help]www.1win5763.help[/url]
заказать кухню цена zakazat-kuhnyu-2.ru .
Ivermectin Access USA: stromectol pill – Ivermectin Access USA
услуги печати https://telegra.ph/kak-popast-v-gorodskoj-rejting-predprinimatelej-02-24 .
заказать кухню под заказ заказать кухню под заказ .
PG
внедрение ерп в организации https://1s-erp-vnedrenie.ru/ .
Розбираєш твори? Це допоможе — [url=https://learning.justtips.website/]повний аналіз твору “Тигролови”[/url].
кухни в спб на заказ кухни в спб на заказ .
https://ivermectinaccessusa.shop/# Ivermectin Access USA
кухни на заказ от производителя кухни на заказ от производителя .
https://t.me/s/reg_official_1win/1706
Hello!
Find unique mysterious connections in interesting facts for valuable innovations and spark creativity in your projects see on the website for innovation labs
Full information on the link – https://101flow.site
All the best and development in business!
нарколог на дом в ростове анонимно нарколог на дом в ростове анонимно .
нарколог на дом стоимость ростов-на-дону narkolog-na-dom-v-rostove.ru .
https://uspharmaindex.com/# US Pharma Index
нарколог на дом срочно ростов-на-дону narkolog-na-dom-v-rostove-1.ru .
https://ivermectinaccessusa.com/# Ivermectin Access USA
бк мелбет
Установить приложение Melbet: APK, iOS и ПК
Мобильная версия Melbet объединяет ставки и казино в едином приложении. Пользователю доступны live-ставки, слоты, онлайн-трансляции, статистика и быстрые финансовые операции. Установка занимает 1–2 минуты.
Android (APK)
Загрузите APK с официального источника, откройте файл и завершите установку. Если требуется включите доступ к установке сторонних приложений, затем авторизуйтесь.
iOS (iPhone)
Перейдите в App Store, найдите «Melbet», выберите «Получить», после установки авторизуйтесь в системе.
ПК
Перейдите официальный сайт, войдите в личный кабинет и добавьте ярлык на рабочий стол. Браузерная версия функционирует как отдельное приложение.
Функционал
Live-ставки с мгновенным обновлением линии, казино и слоты, прямые трансляции, аналитические данные, push-оповещения, регистрация за минуту и поддержка 24/7.
Бонусы
После установки доступны бонус на первый депозит, промокоды и бесплатные ставки. Правила начисления определяются регионом.
Безопасность
Скачивайте только с официальных источников, контролируйте адрес сайта, не передавайте пароль третьим лицам и активируйте двухфакторную аутентификацию.
Загрузка выполняется быстро, после чего доступен весь функционал Melbet.
анонимный нарколог на дом в ростове анонимный нарколог на дом в ростове .
pin-up qeydiyyat forması [url=https://pinup09715.help]pin-up qeydiyyat forması[/url]
вывод из запоя в ростове вывод из запоя в ростове .
Ivermectin Access USA: ivermectin buy nz – ivermectin pills human
стоимость монтажа газового пожаротушения montazh-gazovogo-pozharotusheniya.ru .
http://uspharmaindex.com/# india pharmacy
ivermectin 80 mg: Ivermectin Access USA – ivermectin buy australia
https://uspharmaindex.com/# US Pharma Index
круглосуточный вывод из запоя в ростове круглосуточный вывод из запоя в ростове .
US Pharma Index: pharmacy without prescription – US Pharma Index
สล็อต
TKBNEKO เปิดประสบการณ์ใหม่แห่งการเดิมพันออนไลน์ ฝาก-ถอนไว ด้วยระบบสแกน QR Code
ในยุคดิจิทัลที่ โลกออนไลน์เติบโตต่อเนื่อง TKBNEKO พร้อมยกระดับการให้บริการ ด้วยระบบที่ ทันสมัย รวดเร็ว และ ตรวจสอบได้ เพื่อให้ผู้เล่น อุ่นใจ ทุกครั้งที่ใช้งาน
ระบบการเงินที่ใช้งานง่าย
ฝากขั้นต่ำ: 1 บาท
ถอนขั้นต่ำ: ขั้นต่ำ 1 บาท
เวลาฝากเงิน: ใช้เวลาเพียง 3 วินาที
ยอดถอน: ไม่มีลิมิต
เติมเงินง่าย แค่สแกน
สแกน QR Code ระบบจะ โอนเงินเข้าทันที ขั้นต่ำ 100 บาท สูงสุด ไม่เกิน 500,000 บาทต่อครั้ง
หมวดหมู่เกม
สล็อต: ธีมหลากหลาย
เกมสด: ดีลเลอร์สด
กีฬา: เดิมพันลีกดัง
ยิงปลา: ลุ้นกำไรทันที
โปรโมชั่นและสิทธิพิเศษ
ติดตามหน้า โปรโมชั่น พร้อมระบบ VIP และโปรแกรม แอฟฟิลิเอต
ติดต่อเรา
สอบถามข้อมูลได้ตลอด 24 ชั่วโมง ผ่านหน้า ศูนย์ช่วยเหลือ ทีมงาน TKBNEKO พร้อมดูแลตลอดเวลา
sildenafil 50 mg price: Order Viagra 50 mg online – viagra canada
https://sildenafilpriceguide.com/# Sildenafil Citrate Tablets 100mg
Чи можна приготувати [url=https://kitchen.justtips.website/]пельмені[/url] без шкоди для здоров’я? Дізнайтеся всі секрети приготування!
веб-сайте kraken актуальные ссылки
веб-сайте https://slon3-at.com
cheap viagra: Sildenafil Price Guide – buy Viagra over the counter
монтаж пожаротушения монтаж пожаротушения .
Спорт у всіх його проявах можна знайти на [url=https://sport.justtips.website/]нашому сайті[/url], який регулярно оновлюється.
поисковое продвижение москва профессиональное продвижение сайтов prodvizhenie-sajtov-v-moskve10.ru .
взгляните на сайте здесь кракен онион
http://sildenafilpriceguide.com/# Sildenafil Citrate Tablets 100mg
мостбет не устанавливается apk [url=mostbet85961.help]мостбет не устанавливается apk[/url]
https://ivermectinaccessusa.com/# ivermectin lice
установка газового пожаротушения для промышленного объекта установка газового пожаротушения для промышленного объекта .
Yeah I agree, the platform interface is way cleaner than most competitors out there and their support team actually responds in like 5 minutes. babu88 ????????
http://uspharmaindex.com/# US Pharma Index
веб-сайте водка бет
https://mensrxindex.com/# Mens RX Index
Certified Canada Rx: trustworthy canadian pharmacy – Certified Canada Rx
блог про seo блог про seo .
seo partners seo partners .
Way better than what I was using before, honestly can’t beleive I wasted time on that other site for so long when 666 game online exists. The whole thing just feels more solid and less janky, if that makes sense.
маркетинг в интернете блог seo-blog16.ru .
мелстрой казино сайт мелстрой казино сайт .
проверить сайт водка бэт
[url=https://justtips.website/]Як швидко знайти рішення будь-якої проблеми[/url]? Ось вам добірка ефективних способів.
Certified Canada Rx: canadian compounding pharmacy – Certified Canada Rx
https://certifiedcanadarx.shop/# Certified Canada Rx
мостбет депозит [url=mostbet49271.help]mostbet49271.help[/url]
Mens RX Index: cheapest ed online – get ed meds online
ломоносов скул ломоносов скул .
онлайн класс shkola-onlajn-31.ru .
melbet application melbet application .
мелбет официальный сайт букмекерская контора мелбет официальный сайт букмекерская контора .
1win приложение ios [url=http://1win68017.help/]1win приложение ios[/url]
онлайн школа ломоносов онлайн школа ломоносов .
Certified Canada Rx: Certified Canada Rx – canadian drugstore online
бк мелбет скачать на андроид бесплатно бк мелбет скачать на андроид бесплатно .
http://certifiedcanadarx.com/# Certified Canada Rx
https://certifiedcanadarx.com/# Certified Canada Rx
slots games slots games .
melbet casino app download melbetmobi.ru .
мелбет скачать андроид мелбет скачать андроид .
ed medicines: low cost ed pills – get ed meds today
водные экскурсии в санкт петербурге arenda-yakhty-spb.ru .
Certified Canada Rx: Certified Canada Rx – recommended canadian pharmacies
прогулки по неве прогулки по неве .
Hi, its nice article about media print, we all understand media is a great source of facts.
http://metalldver.com.ua/vidnovlennya-hermetychnosti-far-yak-vydalyty.html
приложение мелбет на андроид приложение мелбет на андроид .
https://certifiedcanadarx.com/# canadian pharmacy oxycodone
аренда яхты arenda-yakhty-spb.ru .
мелбет промокод на фрибет мелбет промокод на фрибет .
Готувати без кухонних ваг – це реально! Ось [url=https://justtips.website/]список мір[/url], які вам знадобляться.
мелбет кз apk последняя версия [url=melbet60432.help]melbet60432.help[/url]
https://mensrxindex.shop/# cheap ed treatment
[url=https://justtips.website/]Як зберігати[/url] сир, щоб він не псувався?
certified canadian pharmacy: Certified North Rx – Certified North Rx
mexican rx meds from mexico medication in mexico
mostbet xush kelibsiz bonus [url=http://mostbet28461.help/]http://mostbet28461.help/[/url]
Update: Still using 24bet Onlinecasino after 3 months now and im honestly impressed with how consistent they’ve been—no dissapointments, reliable payouts every time, and the promotions are actually decent unlike most places.
заказать газовое пожаротушение montazh-gazovogo-pozharotusheniya.ru .
сколько стоит нарколог на дом в ростове сколько стоит нарколог на дом в ростове .
mexico farmacia: best mexican online pharmacy – mexican online pharmacy wegovy
узнать больше кракен онион
mostbet обновление android [url=http://mostbet17403.help]mostbet обновление android[/url]
BajaRx Direct BajaRx Direct farmacia mexicana online
vaycasino resmi giriş vaycasino
Hello everyone!
Analyze behavior mysterious motives to find interesting and valuable social insights and predict human actions accurately see on the website for social models
Full information on the link – https://studiohallo.ru/podvesnye-detskie-kacheli-bezopasnost-razvlechenie-i-razvitie/
All the best and development in business!
canada drugs reviews: US Meds Saver – best online foreign pharmacy
скачать мелбет на андроид с официального сайта скачать мелбет на андроид с официального сайта .
заказать курсовую заказать курсовую .
padişahbet giris: padişahbet
internetagentur seo prodvizhenie-sajtov-v-moskve11.ru .
Здесь можно найти как классические, так и современные модели ковров.
Лучшие шерстяные ковры
Для нас важно, чтобы покупатели получили свои ковры в срок и без повреждений.
курсовая работа купить москва курсовая работа купить москва .
how to get ed pills: ed medications – buy erectile dysfunction pills
deneme bonusu veren casino siteleri: casino siteleri
casino siteleri: lisanslı casino siteleri
суши роллы суши роллы .
casino siteleri lisanslı casino siteleri
https://cassiteleri.buzz/# deneme bonusu veren casino siteleri
check it out netx360 login
руководства по seo seo-blog21.ru .
топ 10 сео компаний топ 10 сео компаний .
https://betmexico.cat/
Betmexico se posiciona en 2026 como el sitio de apuestas y casa de apuestas deportivas lider para el mercado mexicano, destacando por su innovador bono sin deposito de $50 MXN sin jugar lo depositado, una oferta unica que elimina las trabas habituales de la competencia.
vdcasino resmi giriş vdcasino
mostbet Oʻzbekistonda uzcard [url=http://mostbet02894.help/]http://mostbet02894.help/[/url]
ghbdtn привет
Been using this for a couple months and its way better than what I was using before, the interface is alot smoother and more intuituve heaps of wins iniciar sesion.
сео агентство сео агентство .
лучшие интернет агентства лучшие интернет агентства .
веб-сайте водка бэт
casino deneme siteleri: casino deneme siteleri
lisanslı casino siteleri deneme bonusu veren casino siteleri
раскрутка и продвижение сайта раскрутка и продвижение сайта .
Quick pros:
+ Fast loading times
+ Mobile friendly interface
+ Clean layout, easy navigation
+ Responsive customer support
+ Variety of game selection
+ Smooth withdrawal process
bed visa
раскрутка и продвижение сайта раскрутка и продвижение сайта .
https://cassiteleri.top/# casino deneme siteleri
подробнее водка бэт
1win bonus terms [url=https://www.1win76138.help]https://www.1win76138.help[/url]
vavada dostęp do strony [url=https://vavada56378.help/]https://vavada56378.help/[/url]
выберите ресурсы https://slon4-at.at
1x bet giri? 1xbet-47.com .
https://betplay.cat/
BetPlay se consolida en 2026 como el portal destacado en apuestas deportivas y juegos de casino en linea en Colombia, debidamente habilitada por Coljuegos para ofrecer sus servicios de forma regulada en el pais.
mostbet güncel: mostbet
click here to find out more capcut premium apk
find here geometry dash apk download
1xbet lite 1xbet-52.com .
усиление грунта при высоком уровне грунтовых вод usilenie-gruntov-1.ru .
https://mostbetpl.buzz/# mostbet resmi
bahis siteler 1xbet bahis siteler 1xbet .
mostbet giris: mostbet
I was skeptical about MegaWin at first, honestly thought it was gonna be another sketchy site, but I’ve been using it for a couple weeks now and the whole experience has been pretty smooth — fast payouts, no weird delays or anything. Defintely surprised me. mega win
cialis online pharmacy: Viagra online price – no prescription needed pharmacy
1x giri? 1xbet-55.com .
canadian pharmacy scam: order viagra – top online pharmacy 247
1x bet giri? 1x bet giri? .
1xbet com giri? 1xbet-giris-29.com .
1xbet 1xbet .
1xbet g?ncel adres 1xbet g?ncel adres .
1xbet ?yelik 1xbet ?yelik .
1xbet spor bahislerinin adresi 1xbet spor bahislerinin adresi .
1xbet giri? adresi 1xbet giri? adresi .
one x bet 1xbet-giris-38.com .
ed online treatment: cheap ed meds online – True Health Pharm
1xbet resmi sitesi 1xbet resmi sitesi .
1win скачать с официального сайта [url=1win63197.help]1win63197.help[/url]
https://medicobridgerx.com/# MedicoBridge RX
world pharmacy india: TrustRx India – india pharmacy mail order
MedicoBridge RX: mexican pharmacy near me – farmacia online usa
MedBridge Pharmacy: MedBridge Pharmacy – cost less pharmacy
ии для студентов nejroset-dlya-referatov.ru .
melbet забыл пароль [url=www.melbet27438.help]www.melbet27438.help[/url]
MedBridge Pharmacy: www canadianonlinepharmacy – best australian online pharmacy
pharmacy website india: TrustRx India – Online medicine order
mostbet wypłata blik [url=https://mostbet2005.help]https://mostbet2005.help[/url]
http://primelinepharmacy.com/# cheap ed
https://corevitalpharmacy.shop/# Cialis 20mg price in USA
чат нейросеть для учебы nejroset-dlya-referatov-7.ru .
колесо фортуны
анализ наружной рекламы анализ наружной рекламы .
Ребята, кто ищет информацию по модерации сообществ и работе с негативом, в статье есть полезный раздел. Автор рассказывает, как выстраивать службу поддержки в соцсетях, готовить скрипты ответов и действовать в кризисных ситуациях. Актуально: https://sksensation.ru/smm-prodvizhenie-v/
позиция карточки в выдаче reklamnyj-kreativ12.ru .
apartments for sale phuket thailand apartments for sale phuket thailand .
luxury villas phuket for sale villas-for-sale-in-phuket.com .
рекламный креатив рекламный креатив .
https://corevitalpharmacy.shop/# CoreVital Pharmacy
https://pharmacologicalsciences.com/generics.html Pharmacological Sciences
улучшение креативов улучшение креативов .
our website paycor login
buy real estate in phuket real-estate-for-sale-in-phuket.com .
sapporo88 login
перевод технического текста teh-perevod.ru .
согласование перепланировки согласование перепланировки .
villas phuket for sale villas phuket for sale .
seo специалист kursy-seo-12.ru .
проект перепланировки квартиры москва проект перепланировки квартиры москва .
https://pharmacologicalsciences.com/ Pharmacological Sciences
seo бесплатно seo бесплатно .
вавада казино официальный сайт вход вавада казино официальный сайт вход .
which internet partner which internet partner .
cheapest ed treatment Pharmacological Sciences Research Institute buy ed meds online
pin-up 634 официальный сайт: pin up
мелбет казино официальный сайт скачать мелбет казино официальный сайт скачать .
содержание kraken рабочая ссылка onion
https://novamenpharmacy.shop/# Viagra online price
скачать мелбет официальный сайт скачать мелбет официальный сайт .
нарколог психолог нарколог психолог .
cheap ed Pharmacological Sciences Research Institute best online ed medication
buy ed medication online Pharmacological Institute low cost ed meds online
https://corevitalpharmacy.com/# CoreVital Pharmacy
проверить сайт kraken ссылка тор
폰테크
폰테크라는 방식은 급하게 현금이 필요할 때 자주 검토되는 수단으로 언급됩니다. 요즘은 비대면 진행, 당일 입금, 미납요금 대납, 전국 상담 같은 요소가 같이 노출되면서 소개 방식도 많아졌습니다. 그렇다고 해서 진행을 알아볼 때는 빠르다는 말보다 진행 구조를 먼저 봐야 합니다. 접수 방식, 진행 형태, 입금까지의 흐름을 먼저 확인하는 편이 낫습니다.
비대면 방식의 폰테크는 방문 없이 상담부터 접수, 진행 안내까지 이어지는 구조가 많습니다. 서울·경기·인천 같은 수도권은 물론이고 강원, 충청, 전라, 경상, 제주까지 전국 상담이 가능하다고 안내하는 경우가 많습니다. 방문 부담이 적다는 점은 분명 편리하지만, 보기보다 단순해 보여도 조건 확인은 더 꼼꼼해야 합니다.
폰테크·가개통 안내 문구에서는 속도와 상시 상담을 강조하는 표현이 반복되는 경우가 많습니다. 중요한 것은 표현보다 실제 진행 방식입니다. 어떤 기종을 다루는지, 조건이 어떻게 정해지는지, 어떤 방식으로 진행 가능한지, 입금 시점이 언제인지까지 확인돼야 합니다.
전체 진행 순서는 대체로 비슷합니다. 전화·문자·카카오톡으로 접수를 받고, 그다음 기종과 조건을 맞춰 상담을 진행하고, 방문·출장·비대면·대납 중 방식을 선택하고, 기기 수령 이후 당일 지급으로 연결되는 형태입니다. 순서는 짧아 보여도 실제 확인 항목은 적지 않습니다. 특히 상담 단계에서 본인 상황에 맞는 진행 형태와 가능 조건을 분명히 해야 뒤에서 꼬이지 않습니다.
전국 단위로 운영된다고 하는 곳들은 지역명을 세세하게 나열하는 경우가 많습니다. 이런 구성은 지역 검색에 강하고, 사용자에게 해당 지역에서도 진행 가능하다는 인상을 줍니다. 이 때문에 지역명 조합 키워드가 반복적으로 쓰입니다.
상담 채널은 보통 대표전화, 카카오톡, 상담신청 버튼처럼 바로 연결되는 구조로 잡힙니다. 여기에 정식등록업체, 비대면 당일입금, 1:1 상담 같은 문구가 붙습니다. 다만 판단 기준은 광고 문구가 아니라 운영 정보와 절차 설명입니다.
결국 폰테크 소개에서 핵심은 세 가지입니다. 급전 상황에서 빠르게 진행할 수 있다는 점, 비대면과 전국 상담이 가능하다는 점, 상담 신청부터 지급까지 흐름이 단순하다는 점입니다. 반대로 실제 확인 포인트는 속도가 아니라 조건과 절차, 지역 대응 범위입니다.
технический переводчик услуги teh-perevod.ru .
https://antimicrobialresearch.com/bactrim.html Amoxicillin Trihydrate
Over the counter antibiotics for infection Doxycycline Hyclate buy amoxicillin antibiotic
https://antimicrobialresearch.com/otc-antibiotics.html Institute for Antimicrobial Research
try this website copy trading
Way better than what I was using before, the interface is cleaner and it dosn’t feel like such a hassle to navigate around compared to the other option. lobangking68 ewallet
prescription antibiotic Amoxicillin Trihydrate uti antibiotics online
Подробнее здесь https://gurava.ru/geocities/62/%D0%A3%D0%BB%D0%B0%D0%BD-%D0%A3%D0%B4%D1%8D
заказать кухню на заказ заказать кухню на заказ .
buy antibiotics from canada Sulfamethoxazole Trimethoprim buy antibiotics online for tooth infection
OTC antibiotics prescribed antibiotics online
1win complaints [url=https://1win5530.ru/]https://1win5530.ru/[/url]
https://primeindiameds.shop/# canadian pharmacy viagra 50 mg
Сравниваю разные компании, вот ещё один вариант: https://f1-it.ru/uslugi-smm-prodvizheniya-v-sotsialynh-setyah.html
нарколог краснодар нарколог краснодар .
кухня по индивидуальному проекту kuhni-spb-49.ru .
mexican pharmacy online: reliable mexican pharmacies – reputable pharmacies in mexico
phuket thailand apartments for sale apartments-for-sale-in-phuket-1.com .
як грати в aviator на sweet bonanza [url=https://sweet-bonanza06538.help/]як грати в aviator на sweet bonanza[/url]
Visit Your URL https://mixmy.money/
сколько стоит заказать кухню zakazat-kuhnyu-11.ru .
www
best online pharmacy reddit: top 10 pharmacies in india – best online foreign pharmacy
алкоголизм вывод из запоя краснодар vyvod-iz-zapoya-v-krasnodare-4.ru .
вывод из запоя кодирование краснодар vyvod-iz-zapoya-v-krasnodare-2.ru .
вывод из запоя на дому краснодар цены вывод из запоя на дому краснодар цены .
melbet android [url=http://melbet76521.help/]http://melbet76521.help/[/url]
заказать кухню под ключ zakazat-kuhnyu-11.ru .
реабилитация алкоголиков vyvod-iz-zapoya-na-domu-voronezh.ru .
mostbet koeffitsientlar [url=mostbet59402.help]mostbet59402.help[/url]
Technical performance on this iwin aviator platform is realy impressive — loads in under 2 seconds, mobile responsive design is clean and intuitive, zero lag even on 4G connections. UI/UX follows modern web standards with minimal bloat and efficient asset optimization.
цветы оптом в московской области cveti-nederogo.ru .
BorderValue RX: BorderValue RX – BorderValue RX
наркологический стационар vyvod-iz-zapoya-na-domu-voronezh-3.ru .
реабилитационный центр для наркозависимых реабилитационный центр для наркозависимых .
наркологическая помощь наркологическая помощь .
canadian online pharmacy: online pharmacy india – buying from canadian pharmacies
https://trustedindiacarerx.shop/# online pharmacy india
online pharmacies uk united kingdom online pharmacy clomid online pharmacy no prescription
http://certifiedmaplerx.com/# licensed canadian drug suppliers
1win лимит на о деньги [url=http://1win96781.help/]1win лимит на о деньги[/url]
mexican pharmacies no prescription: BorderCareRX – BorderCare RX
pop over here jaxx wallet
https://amoxilfast.com/# buy amoxicillin 500mg uk
amoxicillin capsules online: amoxil fast – bacterial infection medication
1win cashback [url=https://1win5750.help]https://1win5750.help[/url]
stromectol without prescription usa: trusted ivermectin pharmacy – trusted ivermectin pharmacy
http://ivermectinfast.com/# ivermectin oral tablets usa
link xrp wallet
phentermine pharmacy online live pharmacy continuing education online cephalexin online pharmacy
buy amoxil online usa: amoxil without prescription usa – generic amoxicillin online
http://ivermectinfast.com/# buy stromectol online usa
how to purchase prednisone online: prednisone without prescription usa – prednisone without prescription medication
can i buy prednisone over the counter in usa: buy prednisone online usa – prednisone pharmacy
Tried it but not gonna make a big deal about it yet, the site seems ok so far like the layout is clean and everything loads fine, gonna give it more time before i form any real opinions about weather its actually worth sticking with, u win game is teh link if ur curious i guess
мелбет пополнить счёт [url=https://melbet23481.help/]https://melbet23481.help/[/url]
buy cigarettes online australia
An Online Service Offers Australians Tobacco – But Also “Stop Smoking” Messages
A website has appeared offering Australian residents the opportunity to purchase cigarettes and tobacco with delivery to their door. The website, which operates under the name Australia Tobacconist Hub, is full of mixed messages: heavy promotion of cheap cigarettes alongside disclaimers about the health risks of tobacco use.
Available Items
The platform’s key focus is people who smoke seeking lower prices. Among the products listed are:
Double Happiness (?? ??) — $190 per carton (10 packets x 20’s)
Manchester Sapphire Blue – Dubai Version — $220 per block
Manchester Special Edition Flow Red – Dubai Edition — $250 per carton
Manchester Blue Crush – Dubai Edition — $250 per carton
Dunhill Blue – UK Edition — $220 per carton
Dunhill Red – UK Edition — $190 per carton
Benson and Hedges Gold — $160 per carton
Zhongnanhai brand — $180 per carton
The seller emphasizes “low costs” (Cheap Tobacco Australia) and the availability of well-known names such as Marlboro, Manchester, Bossku, Double Happiness, and others.
Delivery and Payment Methods
The seller promises fast, reliable, and discreet delivery across Australia (Fast Tobacco Delivery Australia). They state that they take bank transfers, USDT (cryptocurrency), PayPal, Wise, and other methods. Customer interaction is conducted via WhatsApp and email — a standard practice in the unlicensed sector for online tobacco sales.
The Contradiction in Messaging
Interestingly, the same website that sells cigarettes (while formally warning that it is illegal to sell tobacco products to minors) also features a “STOP SMOKING” banner with an drawing of a cigarette passing through human lungs.
In a heading called “STOP TOBACCO”, the text says:
“Quitting isn’t easy, but each attempt matters. Within minutes, your body begins to heal — and as time goes by, your health and energy come back. Let’s start today!”
This anti-smoking advice sits directly alongside a product catalogue with prices from $160 to $250 per carton and a call to action: “Buy Cigarettes Online in Australia at the Best Price.” Such mixed communication is common of unlicensed or “grey market” tobacco shops that pretend to care about public health while still pushing harmful goods.
Potential Legal Problems
The text fails to mention whether the seller holds a valid Australian retail license for tobacco. Australia is famous for some of the strictest tobacco laws in the world, including standardised packaging rules and extremely high excise taxes. The promise of low-cost smokes — especially “Dubai Edition” or “UK Version” — often suggests products that have evaded taxes, been brought in illegally, or are fake.
Conclusion
The online shop described above is a classic case of a shadow online tobacco business. It takes advantage of smokers’ wish for cheaper prices in the face of Australia’s high legal tobacco taxes, while masking itself with empty health warnings and promises of good service. Potential buyers should keep in mind that buying unlicensed tobacco carries not only the chance of legal trouble but also a complete lack of quality or safety guarantees.
другие https://images.google.vg/url?q=https://letundra.com/en/news/?taglist=nizhny-novgorod,simferopol-2
For anyone who needs to know, make sure you read the terms before signing up at play milky way online because there’s alot of details that matter and you’ll want to understand the withdrawal process upfront so you don’t get confused later like i did.
stromectol tablets: trusted ivermectin pharmacy – stromectol without prescription usa
antibiotics online pharmacy usa: bacterial infection medication – antibiotics online pharmacy usa
https://luckia.net.co/
La plataforma Luckia, con mas de dos decadas de experiencia a partir de su creacion en 2002, se ha convertido en un operador de casino virtual y apuestas en deportes de referencia para el publico hispanoparlante, con presencia tambien en Colombia para 2026.
mostbet qollab-quvvatlash [url=mostbet47183.help]mostbet47183.help[/url]
перейдите на этот сайт дешёвые отзывы озон
prednisone 15 mg daily: SteriCare Pharmacy – order prednisone online no prescription
подробнее https://vodkabet.kz/
amoxil fast: fast delivery amoxicillin usa – amoxil without prescription usa
taka77 is legit solid, would use again taka77 download 🙂
Читать далее https://drink.vodkabet-zercalo.com/
https://ivermectinfast.com/# antiparasitic medication usa
online canadian pharmacy: canadian drugstore online – canadian pharmacy victoza
узнать kraken официальный сайт krakendarknet top
From a technical standpoint, dragonmoney228.casino performs exceptionly well with fast load times across all pages and excellent mobile responsiveness that doesn’t lag even on slower connections. The UI is clean and minimalist, which makes navigation intuitive. Драгон Мани казино официальный сайт
https://globalindiapharmacy.com/# Global India Pharmacy
is 20mg cialis equal to 100mg viagra cialis vs viagra what happens if a girl takes viagra
cómo retirar en pin up [url=pinup62718.help]pinup62718.help[/url]
mybloom.ru mybloom.ru .
melbet как поставить экспресс [url=https://melbet63810.help]https://melbet63810.help[/url]
The world of online casinos in Pakistan is rapidly growing in the region right now. You can find a huge variety of slots and table games with high RTP. | Most sites provide mobile-friendly interfaces and 24/7 customer support. | Choosing a licensed operator ensures a fair and transparent gaming process. ] Don’t miss your chance to win big on a trusted platform.
reputable indian pharmacies: mail order pharmacy india – Global India Pharmacy
canadian pharmacy mall: canada pharmacy – best canadian online pharmacy reviews
Особенно понравился материал про Переезд в Адыгею: из города в тишину природы.
Ссылка ниже:
[url=https://softogon.ru/instrukcii-i-gajdy/pereezd-i-vozvrashhenie-v-adygeyu-kak-smenit-megapolis-na-spokojnuyu-zhizn/]https://softogon.ru/instrukcii-i-gajdy/pereezd-i-vozvrashhenie-v-adygeyu-kak-smenit-megapolis-na-spokojnuyu-zhizn/[/url]
Hello i want share about 1ace, is very good platform for me, interface is simple and easy for understand, support team help me when i have problem very fast, many peoples use this and is reliable, you can try 1aace
my canadian pharmacy rx: CivicMeds – reputable overseas online pharmacies
CoreBlue Health sildenafil 50 mg price CoreBlue Health
medication canadian pharmacy: CivicMeds – 24 hour pharmacy near me
where can i buy viagra viagra tablets where can i buy viagra over the counter usa
Viagra generic over the counter: CoreBlue Health – Buy Viagra online cheap
buy cialis pill: Cialis without a doctor prescription – VeritasCare
https://corebluehealth.shop/# CoreBlue Health
mostbet depozit təlimatı [url=http://mostbet2011.help]mostbet depozit təlimatı[/url]
online pharmacy cialis: CivicMeds – online pharmacy indonesia
canadian pharmacy discount code best canadian pharmacy for viagra humana online pharmacy
mostbet nu se instaleaza [url=http://mostbet75302.help/]http://mostbet75302.help/[/url]
pharmacies in canada that ship to the us online pharmacy overnight shipping best non prescription online pharmacies
Kraken — это онлайн-платформа, о которой часто говорят в контексте цифровых сервисов и современных технологий. Пользователи нередко ищут информацию по запросам kraken сайт, kraken ссылка или kraken зеркало, чтобы понять, как устроен доступ к ресурсу и какие существуют особенности его работы. Важно учитывать, что в интернете могут встречаться различные версии сайтов, включая так называемые зеркала, которые могут отличаться по безопасности и надежности. Перед переходом по любой ссылке рекомендуется проверять ее подлинность, обращать внимание на адресную строку и использовать только проверенные источники. Такой подход помогает снизить риски и обеспечивает более безопасный опыт работы в сети.гарнитура razer kraken
casino online Moldova 1win [url=https://1win90843.help]https://1win90843.help[/url]
CoreBlue Health: CoreBlue Health – buy viagra here
https://corebluehealth.shop/# CoreBlue Health
Tadalafil price: buy cialis pill – VeritasCare
mostbet слот турнир [url=http://mostbet63740.help/]http://mostbet63740.help/[/url]
мостбет смотреть матчи [url=https://www.mostbet89276.help]https://www.mostbet89276.help[/url]
http://corebluehealth.com/# CoreBlue Health
online pharmacy com CivicMeds list of online pharmacies
https://civicmeds.shop/# pharmacy rx one
сюда сайт накрутки отзывов авито
CoreBlue Health: sildenafil 50 mg price – Viagra generic over the counter
VeritasCare: VeritasCare – VeritasCare
https://lebull.com.mx/
Segun el texto proporcionado, Lebull representa una plataforma de casino en linea y plataforma de apuestas deportivas que funciona en Mexico contando con una coleccion de mas de 10,000 juegos, una app movil completa y suministradores de elite como Pragmatic Play, NetEnt y NolimitCity.
https://pinupazz.top/ pin-up oyunu
https://pinupaz.online/ pin up az
mostbet не приходит смс код [url=https://mostbet09754.help/]https://mostbet09754.help/[/url]
pin up az online pin up casino
AccessBridge Pharmacy: AccessBridge – AccessBridge
мостбет наманган [url=http://mostbet26849.help/]http://mostbet26849.help/[/url]
Для тех, кто ищет информацию по теме “Лесные пожары: причины и предотвращение”, есть отличная статья.
Смотрите сами:
[url=https://xroniker.ru/%d0%b1%d0%b5%d0%b7-%d1%80%d1%83%d0%b1%d1%80%d0%b8%d0%ba%d0%b8/lesnye-pozhary-statistika-i-prichiny-profilaktika-i-otvetstvennost-za-podzhog-lesa/]https://xroniker.ru/%d0%b1%d0%b5%d0%b7-%d1%80%d1%83%d0%b1%d1%80%d0%b8%d0%ba%d0%b8/lesnye-pozhary-statistika-i-prichiny-profilaktika-i-otvetstvennost-za-podzhog-lesa/[/url]
http://accessbridgepharmacy.com/# AccessBridge
https://steadymedspharmacy.com/# SteadyMeds
1win depunere criptomonede [url=http://1win26495.help/]http://1win26495.help/[/url]
http://steadymedspharmacy.com/# SteadyMeds
AccessBridge Pharmacy AccessBridge AccessBridge
how to play aviator on 1win [url=www.1win21894.help]how to play aviator on 1win[/url]
http://formulinepharmacy.com/# medicine online
мостбет блэкджек [url=www.mostbet18374.help]www.mostbet18374.help[/url]
Срочный заказ — уточнили наличие готовых модулей на складе, нашли нужный размер. Забрали в тот же день собственным транспортом. Сэкономили время на ожидание изготовления. [url=https://blok-cont.ru/]блок контейнер цена Москва[/url]
AccessBridge Pharmacy: AccessBridge Pharmacy – AccessBridge
здесь кибербезопасность
кракен наркотики ссылка.
Сервис Кракен – лучший магазин моментальных покупок в Darknet
Сервис Kraken Onion – одно из крупнейших сообществ Даркнета, где продаются разные позволяющие расслабиться препараты, фальшивые документы и деньги, предлагается взлом сайтов и пробив информации. Посетителям гарантирована максимальная конфиденциальность, а количество магазинов постоянно увеличивается.
Товары и услуги на сайте Kraken
На сайте можно найти такие товары и услуги:
• Несколько видов наркотических средств – от травки и мета до опиатов и психоделиков.
• Обналичивание криптовалют.
• Взломанные аккаунты VPN.
• Услуги хакеров.
• Паспорта, удостоверения, водительские права.
• Телефонные и банковские карты.
• Поддельные банкноты – в основном, 1000, 2000 и 5000 руб..
• Оборудование и приборы – камеры, жучки, электронные ключи.
На сайте можно и найти работу. Например, стать курьером или кладменом, варщиком или гровером. Есть возможность самому продавать препараты и другие товары.
Несколько плюсов сервиса
Основные преимущества площадки Kraken:
• Высокий уровень конфиденциальности клиентов и владельцев магазинов благодаря расположению в Даркнете.
• Применение криптовалют для расчётов. Это гарантирует анонимность всех транзакций.
• Возможность забрать товар не дожидаясь доставки. Закладки уже доставлены – нужно только забрать.
• Минимальный риск обмана. Проблемы решаются обратившись в поддержку сайта, доступную 24 часа в сутки.
• Рейтинговая система, позволяющая снизить сразу отсортировать лучшие магазины.
• Доставка в разные города РФ и соседних странах. Перечень городов включает даже небольшие населённые пункты.
Пользователям Кракена доступны бесплатные службы. Круглосуточно они могут проконсультироваться с врачом-наркологом или юристом. А если появились проблемы – связаться с поддержкой, которая тоже отвечает в любое время.
Ещё одна особенность Кракена – собственный форум. Вход из верхней части сайта. На форуме есть правила поведения, новости и информация от других посетителей. И даже исследования администрации проекта и школа кладменов для общения закладчиков.
kraken рабочее зеркало.
Сервис Kraken – лучший магазин моментальных покупок Даркнета
Торговая площадка Kraken – лучший магазин в Даркнете, где продаются разные психоактивные вещества, фальшивые документы и деньги, можно заплатить за доступ к чужим личным данным и аккаунтам. Посетителям гарантирована максимальная конфиденциальность, а количество магазинов всё время растёт.
Что можно купить и заказать на Кракене
На сайте встречаются такие товары и услуги:
• Большой ассортимент наркотиков – от травки и мета до опиатов и психоделиков.
• Обналичивание Bitcoin.
• Взломанные аккаунты VPN.
• Цифровые услуги.
• Паспорта, удостоверения, водительские права.
• Банковские и SIM карты.
• Фальшивые купюры – в основном, 1000, 2000 и 5000 руб..
• Оборудование и приборы – от скрытых камер и жучков до флешек для взлома.
На сайте можно и найти работу. В том числе, стать курьером или кладменом, химиком или гровером. Можно начать свой бизнес.
Преимущества Кракена
Причины для выбора площадки Kraken:
• Высокий уровень конфиденциальности для продавцов и покупателей за счёт расположения в Даркнете.
• Использование BTC для расчётов. Оплата Биткойнами обеспечивает высокий уровень конфиденциальности.
• Возможность забрать товар сразу после оплаты. Клады уже на месте – зная адрес, можно забирать.
• Гарантия отсутствия стать жертвой мошенников. Конфликтные ситуации решаются обратившись в поддержку сайта, которая работает круглосуточно.
• Система рейтинга, позволяющая снизить легко определить лучшие магазины.
• Обслуживание РФ и соседних странах. Список доступных мест содержит даже небольшие населённые пункты.
Клиентам сервиса доступны бесплатные службы. В любое время они могут проконсультироваться с врачом-наркологом или юристом. А если появились проблемы – обратиться в техподдержку, работающей в любое время.
Ещё одна особенность площадки – собственный форум. Перейти к нему можно по ссылке в верхней части сайта. На страницах форума находятся основные правила, новости и информация от других посетителей. И даже результаты площадки и раздел для общения доставщиков товара.
new pharmacy online https://edmedscoupon.shop/# cheapest online ed treatment
here
wealthsimple login
pet rx: Pet Canada Direct – vet pharmacy
http://pharmrate.com/# Pharm Rate
1win как отыграть бонус [url=https://www.1win56483.help]https://www.1win56483.help[/url]
buy erectile dysfunction medication Ed Meds Coupon best online pharmacy
부산호빠
mostbet Visa [url=https://mostbet14362.help]https://mostbet14362.help[/url]
mostbet limit qoyish [url=https://mostbet65047.help/]mostbet limit qoyish[/url]
https://stromectol.reviews/# stromectol reviews
how much does ivermectin cost: ivermectin 5 – stromectol reviews
https://semaglutide.life/# semaglutide pill
cracen.
Сайт Кракен – лучший магазин моментальных покупок Даркнета
Сервис Кракен – лучший магазин Даркнета, где есть почти любые психоактивные вещества, фальшивые документы и деньги, можно заплатить за взлом сайтов и пробив информации. Покупателям обеспечивается полная анонимность, а количество магазинов всё время растёт.
Покупки на сайте Kraken
На Кракене можно найти такие предложения:
• Большой ассортимент наркотиков – от травки и мета до ЛСД и кокаина.
• Обналичивание Биткоинов.
• Взломанные аккаунты VPN-сервисов.
• Цифровые услуги.
• Паспорта, удостоверения, водительские права.
• Телефонные и банковские карты.
• Поддельные банкноты – в основном, 1000, 2000 и 5000 руб..
• Оборудование и приборы – от скрытых камер и жучков до флешек для взлома.
Кракен поможет и найти работу. В том числе, устроиться курьером или кладменом, химиком или гровером. Можно начать свой бизнес.
1win entrar y jugar [url=https://1win3005.mobi/]1win entrar y jugar[/url]
кракен маркетплейс ссылка на сайт.
Сервис Kraken – лучшая торговая площадка Даркнета
Торговая площадка Кракен – лучший магазин Даркнета, где есть почти любые ПАВ, поддельные банкноты, паспорта и удостоверения, предлагается доступ к чужим личным данным и аккаунтам. Покупателям обеспечивается полная анонимность, а количество магазинов постоянно увеличивается.
Товары и услуги на Кракене
В магазинах сервиса встречаются такие товары и услуги:
• Несколько видов наркотических средств – от марихуаны и стимуляторов до ЛСД и кокаина.
• Обналичивание Bitcoin.
• Взломанные аккаунты VPN-сервисов.
• Услуги хакеров.
• Паспорта, удостоверения, водительские права.
• Банковские и SIM карты.
• Фальшивые купюры – обычно – от 1000 до 5000 рублей.
• Оборудование и приборы – от скрытых камер и жучков до флешек для взлома.
Сервис предлагает и найти работу. В том числе, стать курьером или кладменом, варщиком или тем, кто выращивает каннабис. Есть возможность стать продавцом.
mostbet crash tips [url=https://mostbet62741.help]mostbet crash tips[/url]
TOTO138 LOGIN
buy antibiotics online for tooth infection: get antibiotics quickly – antibiotics cheap
melbet bug application [url=www.melbet38470.help]www.melbet38470.help[/url]
мелбет баланс [url=https://melbet09374.help]https://melbet09374.help[/url]
ivermectin pill cost: stromectol cost – ivermectin tablets
1 win Perú [url=https://www.1win67052.help]1 win Perú[/url]
canadian pharmacy online reviews online pharmacy delivery delhi how much does viagra cost at the pharmacy
over the counter antibiotics: antibiotics cheap – antibiotics cheap
where can i get semaglutide: semaglutide life – best online pharmacy
mostbet Oʻzbekiston yuklab olish [url=mostbet74183.help]mostbet Oʻzbekiston yuklab olish[/url]
how to take rybelsus and levothyroxine: semaglutide life – trusted online pharmacy
yo ngl ec88.xn--com-cn0a.hk118.com actually slaps fr fr like the whole thing is lowkey smooth and tbh the interface hits different compared to other sites imo its pretty fire not gonna lie
https://semaglutide.life/# online rybelsus
buy antibiotics online for tooth infection: over the counter antibiotics – antibiotics cheap
prescribed antibiotics online: buy antibiotics online safely – otc antibiotics
antibiotics cheap buy antibiotics from india antibiotics cheap
ivermectin syrup: ivermectin 1 – stromectol otc
best online doctor for antibiotics over the counter antibiotics get antibiotics quickly
omeprazole people pharmacy best rated canadian pharmacy ez online pharmacy buy viagra usa
Looking at best casino bonuses in Pakistan is rapidly growing in the region right now. The security of transactions and fast payouts are guaranteed on these platforms. | Most sites provide mobile-friendly interfaces and 24/7 customer support. | Choosing a licensed operator ensures a fair and transparent gaming process. ] Don’t miss your chance to win big on a trusted platform.
mostbet слоты 2026 [url=https://www.mostbet18247.help]https://www.mostbet18247.help[/url]
mostbet Andijon humo [url=www.mostbet18401.help]mostbet Andijon humo[/url]
https://mexicanpharm.xyz/# mexican pharmacy online medications
reputable canadian pharmacy: Canadian Tabs – Canadian Tabs
pharmacy online: Mexican Pharm – farmacias online usa
https://indianmedsdelivery.xyz/# best online pharmacy india
https://canadiantabs.xyz/# canadian pharmacies that deliver to the us
Перейти на сайт попробовать накрутку РІ инсте СЃРЅРі
mostbet mines Česko [url=http://mostbet32570.help]mostbet mines Česko[/url]
Ayr?ca, eger mutfak tezgah modelleri 2023 konusuyla ilgileniyorsan?z, suraya bak?n. Link burada: [url=https://hobiyapma.com/articles/2023-mutfak-tezgah-modelleri-inceleme/]https://hobiyapma.com/articles/2023-mutfak-tezgah-modelleri-inceleme/[/url]
mostbet shartlar [url=https://mostbet91372.help]https://mostbet91372.help[/url]
http://ivermectinfirst.com/# Ivermectin First
mostbet Жусан банк [url=https://www.mostbet76480.help]https://www.mostbet76480.help[/url]
Important safety data regarding newer antipsychotic medications. – https://de.imedwiki.org/wiki/Krankenhaus , Excellent overview of artificial intelligence in pathology. .
dog prescriptions online dog medicine dog medicine
Хочу выделить материал про Свежие новости и аналитика из мира.
Вот, делюсь ссылкой:
[url=https://rubgazeta.ru]https://rubgazeta.ru[/url]
clobetasol cream online pharmacy cooperative pharmacy store locator reputable online pharmacy no prescription
1win ios версия [url=http://1win56183.help]http://1win56183.help[/url]
skip’s pharmacy low dose naltrexone online pharmacy no prescription klonopin kamagra oral jelly online pharmacy
1win Кыргызстан катталуу [url=https://1win94317.help/]1win Кыргызстан катталуу[/url]
мелбет ошибка пополнения [url=melbet45163.help]melbet45163.help[/url]
https://cialis.sbs/# Cialis over the counter
https://cialis.sbs/# Cialis 20mg price in USA
semaglutide meal plan rybelsus coupon no insurance no rx needed pharmacy
Buy Cialis online Tadalafil price Buy Tadalafil 10mg
find more info https://cleanthebit.com/zh/
1win aviator играть [url=https://www.1win59801.help]https://www.1win59801.help[/url]
pin-up depozitsiz pulsuz mərc [url=www.pinup2010.help]www.pinup2010.help[/url]
over at this website https://cleanthebit.com/zh/
lucky jet 1вин [url=http://1win68503.help/]http://1win68503.help/[/url]
Как комплексное seo продвижение сайта помогает снизить стоимость лида?
betmgm-casinos-canada.com/promo-codes/
https://bestbetgiris.online# pusulabet güncel adres
смм накрутка
Для тех, кто ищет информацию по теме “Добро пожаловать в мир ММА: Бои и Новости”, там просто кладезь информации.
Ссылка ниже:
[url=https://mma-gun.ru]https://mma-gun.ru[/url]
official site https://smmpanel.one
Going Here https://smmpanel.ooo
Easy Mex Meds: Easy Mex Meds – pharmacy in mexico online
мостбет Visa [url=www.mostbet64028.help]мостбет Visa[/url]
cialis vs viagra substitute for viagra viagra pill price
where can i get viagra women viagra viagra before and after photos
Главная Сайты даркнет
canadian pharmacies online: Easy Canada Meds – best rated canadian pharmacy
Serm — как правильно реагировать на фейковые отзывы конкурентов?
indian pharmacies safe [url=https://easyindiameds.shop/#]world pharmacy india[/url] medicine online order
Easy Canada Meds: canadian drugs online – Easy Canada Meds
aviator fast withdrawal malawi [url=https://www.aviator84217.help]https://www.aviator84217.help[/url]
888starz зеркало вход https://www.888starz-uz3.org .
mostbet кэшбэк казино [url=http://mostbet45631.help/]http://mostbet45631.help/[/url]
п»їlegitimate online pharmacies india reputable indian online pharmacy international pharmacy
https://easyindiameds.com/# indian pharmacies safe
Easy Canada Meds: Easy Canada Meds – canadian pharmacy reviews
trustly-casino-austria.com/
Easy Canada Meds: Easy Canada Meds – canadianpharmacymeds
More Help leapwallet
click for source leap wallet github
dude check this out sandiego-aviator.com is actually pretty cool. like the design doesnt suck and u can find stuff without getting lost. not saying its perfect but def worth a look imo 777bet
spicy-casino-uk.com/bonus-code-for-existing-players/
generic lipitor pharmacy websites
pharmacy fresh pharm trusted online pharmacy
https://freshpharm24.com/product/viagra pharmacy online
pin up hisobni to‘ldirish ishlamayapti [url=pinup61802.help]pinup61802.help[/url]
????? ?? – A+. thats it thats the post.
Кстати, если вас интересует Последние новости и события в Дагестане, загляните сюда.
Вот, делюсь ссылкой:
[url=https://media05.ru]https://media05.ru[/url]
Fresh Pharm reputable online pharmacy no prescription
Viagra online price order viagra Sildenafil Citrate Tablets 100mg
мелбет сроки верификации [url=https://www.melbet36091.help]https://www.melbet36091.help[/url]
ivermectin 2% stromectol Vip stromectol generic
https://cialisvip.online/# Cialis without a doctor prescription
mostbet приложение не открывается [url=http://mostbet78053.help/]http://mostbet78053.help/[/url]
Viagra online price Buy generic 100mg Viagra online Viagra tablet online
смотреть здесь водкабет играть сейчас
“gardrop boyama fikirleri” hakk?nda bilgi arayanlar icin mukemmel bir kaynak var. Kendiniz gorun: [url=https://yapevleri.com/articles/gardrop-boyama-fikirleri/]https://yapevleri.com/articles/gardrop-boyama-fikirleri/[/url]
https://cialisvip.com/# Generic Tadalafil 20mg price
why not try here
crypto payment system
Ngl i was skeptical at first cuz most sites are sketchy but i actually got my winnings paid out no problem, was pleasantly suprised. 24bet Onlinecasino
частный нарколог на дом срочно частный нарколог на дом срочно
фск воронин владимир
срочно врач нарколог на дом срочно врач нарколог на дом
здесь
реакции сердце max
https://stabiline.ru/
наркологическая помощь на дом наркологическая помощь на дом
“evden sat?s siteleri” hakk?nda bilgi arayanlar icin cok faydal? bir yaz? buldum. Suradan okuyabilirsiniz: [url=https://yappendik.com/articles/evden-satis-yapma-yontemleri-ipuclari/]https://yappendik.com/articles/evden-satis-yapma-yontemleri-ipuclari/[/url]
pg slot
สล็อตออนไลน์ยุคใหม่กำลังเปลี่ยนจากสล็อตแบบเดิมไปสู่โครงสร้างเกมออนไลน์ที่ใช้เซิร์ฟเวอร์ความเร็วสูง โดยมีโครงสร้าง API แบบเรียลไทม์ร่วมกับระบบหลังบ้านที่ตอบสนองรวดเร็ว ผู้เล่นจำนวนมากเริ่มมองหาแพลตฟอร์มสล็อตเว็บตรง เพราะระบบทำงานลื่นกว่า และช่วยลดปัญหาการประมวลผลช้า ปัญหาหน้าจอหยุดระหว่างเล่น รวมถึงข้อผิดพลาดของธุรกรรม
ระบบเกมที่เชื่อมต่อโดยตรงจะเชื่อมต่อกับค่ายเกมหลักผ่านAPI โดยตรง ทำให้ข้อมูลรอบหมุนถูกส่งแบบอัตโนมัติโดยไม่ต้องผ่านระบบกรองข้อมูลเพิ่มเติม ส่งผลให้เกมเปิดได้เร็วขึ้น ลดข้อผิดพลาดของระบบโบนัส และช่วยให้ระบบโบนัสทำงานได้เสถียรมากขึ้น
สิ่งที่ทำให้แพลตฟอร์มยุคใหม่แตกต่างคือระบบธุรกรรมอัตโนมัติ ผู้เล่นสามารถฝากถอนเงินได้ตลอดทั้งวัน โดยไม่จำเป็นต้องรอการอนุมัติด้วยมือเหมือนระบบรุ่นเก่า ทำให้การฝากถอนระหว่างเล่นมีความแม่นยำกว่าเดิม
เหตุผลหลักที่ผู้เล่นเลือกสล็อตเว็บตรงคือความโปร่งใสและการตอบสนองที่รวดเร็ว เซิร์ฟเวอร์ที่ทำงานร่วมกับ API หลักของค่ายเกมช่วยลดโอกาสเกิดความคลาดเคลื่อนของข้อมูล ผู้เล่นจึงเข้าใจได้ว่าผลลัพธ์ของเกมมาจากระบบ RNG จริง
เมื่อดูในแง่ประสบการณ์ผู้ใช้ เว็บสมัยใหม่ยังมีการพัฒนาประสบการณ์เล่นผ่านมือถือโดยเฉพาะ เช่น โหมดจอมือถือแนวตั้ง ระบบโหลดเกมแบบรวดเร็ว และระบบบันทึกสถานะอัตโนมัติที่ช่วยรักษาสิทธิ์ในโบนัสเมื่อผู้เล่นออกจากเกมชั่วคราว
แพลตฟอร์มสล็อตยุคใหม่เริ่มใช้ปัญญาประดิษฐ์ประมวลผลพฤติกรรมผู้เล่น ร่วมกับโครงสร้างคลาวด์และAPI Syncเพื่อรองรับทราฟฟิกจำนวนสูง บางระบบยังรองรับระบบธุรกรรมคริปโตเพื่อเพิ่มทางเลือกในการทำธุรกรรมและลดความเสี่ยงจากระบบธนาคารที่ปิดปรับปรุง
อุตสาหกรรมสล็อตออนไลน์จึงกำลังยกระดับจากเว็บเกมธรรมดาไปสู่ระบบเทคโนโลยีเต็มรูปแบบ โดยโครงสร้าง APIและความแม่นยำของธุรกรรมกลายเป็นปัจจัยสำคัญในการเปรียบเทียบระบบของแต่ละเว็บ
ในอนาคตแพลตฟอร์มสล็อตจะยิ่งแข่งขันกันด้านเสถียรภาพของแพลตฟอร์มมากขึ้น ไม่ว่าจะเป็นการประมวลผลธุรกรรม การประมวลผลพฤติกรรมแบบอัตโนมัติ หรือการเข้ารหัสธุรกรรม ผู้ให้บริการที่มีระบบหลังบ้านแข็งแรงและเชื่อมต่อกับค่ายเกมโดยตรงจะตอบโจทย์ผู้เล่นได้ดีกว่าเว็บทั่วไปที่ยังใช้การเชื่อมต่อแบบเก่า
ผู้เล่นยุคใหม่จึงไม่ได้มองแค่แคมเปญการตลาดอีกต่อไป แต่เริ่มให้ความสำคัญกับมาตรฐานทางเทคนิคของแพลตฟอร์ม การซิงค์ยอดเงินแบบเรียลไทม์ และเสถียรภาพของแพลตฟอร์มระหว่างการเล่นจริง
https://sildenafilvip.shop/# Sildenafil 100mg price
For anyone who needs guidance on finding reliable sources for Togel SGP, I’d suggest checking out sgp senin life as it has clear layout and transparent details about how everything works. Just make sure you understand the rules fully before you get started with anything there.
Caminar por una ciudad nueva con maletas a cuestas es uno de los mayores frenos para el turismo, y por eso cada vez mas personas buscan alternativas para dejar sus bultos.
La respuesta es simple: la comodidad permite una conexion mas profunda con el entorno. Cuando nos liberamos del peso fisico, la movilidad urbana se vuelve mucho mas sencilla permitiendo visitar museos, cafes и monumentos sin barreras.
Si les interesa mejorar su proximo viaje, miren estos recursos sobre almacenamiento и movilidad:
Informacion: https://backworkclefne.bbforum.be/post568.html#568
Nos vemos en los comentarios para debatir sobre movilidad urbana.
Капельница от похмелья в Самаре: эффективное восстановление, снятие интоксикации и помощь специалистов в наркологической клинике «Детокс»
Исследовать вопрос подробнее – капельница от похмелья на дом самара
читать купить травмат без опыта
rybelsus heartburn glp-1 drugs rybelsus 3 mg
Между прочим, если вас интересует Свежие новости и прогнозы клуба Авангард, посмотрите сюда.
Смотрите сами:
[url=https://avangard-365.ru]https://avangard-365.ru[/url]
Подробнее здесь трип скан официальный сайт
https://semaglutideglp1.shop/# how fast does rybelsus work
semaglutide cost goodrx glp 1 pills is semaglutide going away
difference between viagra and cialis whats viagra viagra para mujer
I was skeptical about 20Bet at first, not gonna lie, but after actually trying it out I was genuinely suprised by how straightforward everything is—no weird hidden stuff or confusing mechanics. It’s refreshingly simple compared to what I expected.
зайти на сайт https://tripscans74.us
У нас можно подобрать оригинальные подарки и украшения для важного события. В каталоге есть женские украшения, которые подойдут для свадьбы.
Если хочется порадовать близкого человека, стоит обратить внимание на серьги. Такие вещи запоминаются надолго и помогают сделать подарок действительно особенным.
Магазин подарков и украшений предлагает товары для тех, кто ценит качество. Здесь легко выбрать подарок для мамы, не тратя время на бесконечные поиски.
Каталог пополняется интересными товарами, поэтому каждый покупатель может найти что-то свежее. Подарки и украшения помогают выразить внимание без лишних слов.
kraken онион тор
buy Viagra over the counter UroHealth Daily – Order Viagra 50 mg online
cheapest viagra Sildenafil Citrate Tablets 100mg – generic sildenafil
more information https://www.onlyfake.org
go to website https://www.onlyfake.org
Термин «зеркала Kraken» относится к альтернативным веб-адресам ресурса, дублирующим основной сайт. Такие копии создают для обеспечения доступа при технических ограничениях. Важно помнить: деятельность на подобных платформах может противоречить законодательству, а работа с ними связана с рисками утечки данных.как зайти в даркнет с тор браузера
Cialis without a doctor prescription Buy Cialis online – Tadalafil Tablet
Bu arada, eger spider man no way home karakterleri konusuyla ilgileniyorsan?z, buray? inceleyin. Kendiniz gorun: [url=https://toycenneti.com/articles/spider-man-no-way-home-karakterleri/]https://toycenneti.com/articles/spider-man-no-way-home-karakterleri/[/url]
http://mensrxguide.org/# Cialis 20mg price in USA
drugs not to take with viagra does viagra make you last longer hims viagra
вызвать врача нарколога на дом вызвать врача нарколога на дом
Как Создание сайтов на WordPress отличается от работы на других CMS?
where to get rybelsus American Metabolic Research Institute
YOURURL.com
best multi currency wallet
rybelsus 7 mg oral tablet us obesity science
世界盃
2026 FIFA 世界盃 預計由 48 支球隊 角逐冠軍,整體賽程包含 12 組分組,每個小組由 4 支球隊組成。小組前二名球隊 可晉級 淘汰賽,進行 16 強、8 強、4 強、季軍戰與決賽。
本屆世界盃 預計在 2026 年 6 月 正式開踢。首場比賽 將由 墨西哥與南非交手,並在 6 月 12 日 於阿茲特克球場開打。同日稍晚,南韓對決捷克。隔日,加拿大對波士尼亞,以及美國對巴拉圭等小組賽首輪賽事將登場。
分組名單顯示,A 組 包含 墨西哥、南非、南韓與捷克;B 組 有 加拿大、波士尼亞、卡達與瑞士;C 組 則由 巴西、摩洛哥、海地與蘇格蘭同組。像是 巴西、法國、阿根廷、西班牙、英格蘭與德國等傳統強隊 皆已完成分組。
淘汰賽 將於 7 月初 正式進行,16 強賽 將於 7 月 4 日 開始,決賽則安排在 7 月 19 日 舉辦,最終將產生本屆世界盃冠軍。
歷史交手紀錄顯示,墨西哥和南非曾在 2010 年世界盃 碰面,最終以 1:1 平局收場,歷史交鋒仍保持均勢。
此外,越位、黃牌、紅牌、VAR 與點球等規則,也是觀眾理解比賽的重要基礎,球迷對規則判定仍十分關心。
Кстати, если вас интересует Наука и технологии: как новые открытия меняют мир, посмотрите сюда.
Ссылка ниже:
[url=https://alfainter.net]https://alfainter.net[/url]
victoza weight loss semaglutide
liraglutide otc American Metabolic Research Institute
a1c down with rybelsus liraglutide
victoza generic AMRI
us obesity science https://usobesityscience.org/tirzepatide-analysis/ buy victoza online
discover here leap wallet
semaglutide sublingual drops glp-1 agonists
liraglutide fast delivery glp-1 agonists
how to get insurance to cover rybelsus AMRI
найти это vodkabet новый сайт
подробнее здесь водкабет
gabapentin drug price gabapentin visual field defect get high gabapentin
По теме “Последние новости футбола мгновенно после матчей”, есть отличная статья.
Вот, делюсь ссылкой:
[url=https://livelokomotiv.ru]https://livelokomotiv.ru[/url]
dude check this out Play8oy2 its actually pretty legit like not even joking its so much better than other stuff ive tried u gotta see it for urself seriously
веб-сайте водка бет
Запой опасен не только похмелья и слабостью. При запойным употреблении нарушается сон, повышается тревожность, страдает печень, сердце, сосудистая система, желудка и поджелудочной железы. Потеря контроля, очередной прием спиртного и сильная тягу к алкоголю могут приводить к белой горячки, психоза, судороги, инфаркт или инсульта.
Исследовать вопрос подробнее – вывод из запоя круглосуточно казань
So my friend told me about Ramly888 like two weeks ago and I was kinda hesitant at first you know? But he kept saying how he was having fun with it so I finaly checked it out myself and honestly its not bad, the interface is pretty intutive and I havent had any major issues yet. ramly888 bonus
maple leaf pharmacy in canada: Easy North RX – medications canada
https://easynorthrxs.shop/# Easy North RX
medication from mexico mexican meds pharmacy delivery
Durant les weekends session nocturne via https://coloringart.com/forums/topic/business-for-working-with-foreign-investments/#post-562011 pour suivre les avis des joueurs, les tables live attirent beaucoup de joueurs apres plusieurs essais personnels. Certaines sessions live deviennent tres animees pendant la nuit. Certains preferent les petits jackpots pour jouer tranquillement.
read leap wallet twitter profile
MexiCare Direct: MexiCare Direct – MexiCare Direct
Нужны деньги на развитие бизнеса? Автомобиль поможет! Оформляйте займ под ПТС.
Подробнее – http://zaym-ooo.ru
займы юрлицу
автокредиты юридическим лицам
займы для юр лиц новосибирск
tadalafil benefits good rx tadalafil tadalafil effects on kidneys
Easy North RX: Easy North RX – canadian pharmacy near me
пояснения vodkabet новый сайт
Quick pros:
* Loads fast on mobile
* Clean layout, easy navigation
* Customer support responds quickly
* Smooth experience overall
zodiac online
goodrx tadalafil 20mg tadalafil 20 mg tadalafil coupon
tadalafil dosage 10 mg tadalafil dose tadalafil troche
MexiCare Direct: MexiCare Direct – pharmacy mexico online
top 10 online pharmacy in india: top 10 online pharmacy in india – online pharmacy without prescription
tadalafil effects on kidneys what is tadalafil used for how much tadalafil should i take
cialis without a doctor prescription what is the difference between cialis and viagra is cialis safe
содержание снять комнату в однокомнатной квартире москва
Между прочим, если вас интересует События, экономика и культура Свердловской области, посмотрите сюда.
Вот, делюсь ссылкой:
[url=https://66media.ru]https://66media.ru[/url]
interwetten-casino-austria.com/
777bet live.
The 777bet platform has emerged as a popular choice among online gamblers.
tadalafil 20 mg para que sirve tadalafil prescription tadalafil daily
Easy North RX: Easy North RX – canadian pharmacy com
El sistema de transporte publico atraviesa momentos decisivos en muchas capitales, especialmente en las terminales que actuan como nodos principales.
La falta de recursos no solo degrada el servicio, sino que genera cuellos de botella insostenibles. La reduccion de frecuencias и el descuido de la infraestructura provocan retrasos masivos, perjudicando la economia local и la productividad de la ciudad.
Si les interesa el futuro de nuestras ciudades, estos hilos de discusion son imprescindibles:
Fuente; http://gzew.phorum.pl/viewtopic.php?p=739783#739783
?Nos vemos en los comentarios para debatir sobre infraestructura!
when to take cialis for best results maximum dose of cialis cialis generic
indian pharmacy: mail order pharmacy india – no prescription needed pharmacy
mail order pharmacy india Flexi Meds India online pharmacies
https://fleximedsindia.com/# world pharmacy india
Поисковое продвижение сайта — как правильно прописывать теги title и description?
https://fleximedsindia.com/# Online medicine order
Easy North RX: canada online pharmacy – ed drugs online from canada
Easy North RX canada discount pharmacy Easy North RX
По теме “Mentoria e Analise de Futebol com Luis Suarez”, там просто кладезь информации.
Смотрите сами:
[url=https://catedradeldolor.com]https://catedradeldolor.com[/url]
http://neuropathpharmacys.com/# NeuroPath Pharmacy
http://neuropathpharmacys.com/# gabapentin bei neuropathischen schmerzen
online mexico pharmacy: mexico online pharmacy – mexico pharmacy list
выберите ресурсы трип скан вход
«Зеркала Kraken» — это дублирующие интернет-страницы, которые иногда используют для обхода блокировок. Информация о подобных ресурсах распространяется в узких кругах. Перед взаимодействием с любыми онлайн-платформами стоит проверить их легальность и оценить потенциальные угрозы для безопасности данных.kraken магазин vtor run
https://meximedsexpress.icu/# online pharmacy mexico
https://pharmsansordonnance.club/# Viagra pas cher inde
Viagra sans ordonnance livraison 48h: Viagra sans ordonnance livraison 48h – SildГ©nafil Teva 100 mg acheter
Svenska Pharma apotek d-vitamin köpa antibiotika receptfritt
Ищете надежного застройщика в Новосибирске? Первый Строительный – это ваш выбор. Мы строим дома с любовью и заботой о каждом клиенте, используя только проверенные материалы и современные технологии. Наша репутация – это тысячи довольных семей, которые уже живут в наших домах.
Подробнее – https://1-stroitelny.ru
крупные строительные компании
строительная компания
строительная компания домов
cenforce for sale Buy Cenforce 100mg Online cenforce for sale
Levitra tablet price: Generic Levitra 20mg – Vardenafil price
Узнать больше vodkabet прямо сейчас
Viagra homme prix en pharmacie sans ordonnance: Viagra homme sans ordonnance belgique – Viagra pas cher livraison rapide france
Между прочим, если вас интересует Главные события и обновления в Смоленской области, загляните сюда.
Ссылка ниже:
[url=https://smol67media.ru]https://smol67media.ru[/url]
https://svpharm.xyz/# vuxenblöja apotek
More https://vc.ru/id3219783/2886181-kak-ya-obnovil-svoy-lichnyy-sayt-vizitku
https://svpharm.xyz/# recept online apotek
нажмите здесь вотка бет
Buy Vardenafil 20mg online https://macksoodurology.com/erectile-dysfunction/ cheapest ed medication
Macksood Urology: Macksood Urology – Macksood Urology
на этом сайте https://slon8-cc.at/
how to get ed meds online: Macksood Urology – erectile dysfunction online prescription
hangi aloe vera yuze surulur hakk?ndaki makaleyi cok sevdim. Kendiniz gorun: [url=https://hobiprojesi.com/articles/aloe-vera-yuz-faydalari/]https://hobiprojesi.com/articles/aloe-vera-yuz-faydalari/[/url]
apotek acne: Svenska Pharma – apotek hund
Svenska Pharma: halsfluss test apotek – hiv test hemma apotek
buying prescription drugs in mexico: mail order pharmacy mexico – online pharmacy
страница ретро казино
можно проверить ЗДЕСЬ https://slon4-at.com/
Источник retro casino зеркало
Islam Makhachev: ufc 330 start time – ufc 330
Подробнее здесь трип скан
f?r?n ne ise yarar hakk?ndaki makaleyi cok sevdim. Suradan okuyabilirsiniz: [url=https://yappendik.com/articles/firin-ne-ise-yarar-farkli-kullanim-alanlari/]https://yappendik.com/articles/firin-ne-ise-yarar-farkli-kullanim-alanlari/[/url]
look at this website ip stresser free online
phentermine in mexico pharmacy: reputable mexican pharmacy – mexican online pharmacy
hoki1881
этот сайт водкабет
Особенно понравился материал про Свежие тенденции и события в мире недвижимости.
Вот, можете почитать:
[url=https://gazeta-flat.ru]https://gazeta-flat.ru[/url]
CasaSalud Pharmacy: mexican pharmacy online – mexican pharmacy
Перейти на сайт сайт kraken onion
Главная kraken актуальные ссылки
online mexican pharmacy mexican pharmacy online mexico pharmacy
Праздник в стиле зомби-апокалипсиса — это страх, адреналин и выживание. Чтобы найти, [url=https://den-rozhdenya.ru]где справить день рождения[/url], где можно устроить такую вечеринку, рассмотрите заброшенные здания или специализированные квест-комнаты.
Узнать подробнее: https://den-rozhdeniya-kazan.ru
день рождения казань
где можно провести день рождения недорого
где интересно отметить день рождения
Спасибо!
Зацепил раздел про Последние тенденции и советы в недвижимости.
Смотрите сами:
[url=https://media-novostroyki.ru]https://media-novostroyki.ru[/url]
canadian prescription pharmacy pharmacy in canada NorthBridge Pharmacy
https://northbridgepharm.shop/# canadian prescription pharmacy
pg slot
ปฏิวัติวงการสล็อตออนไลน์ปี 2026: เทคโนโลยีใหม่กับอนาคตของ iGaming
ตลาดสล็อตออนไลน์ยังคงขยายตัวอย่างต่อเนื่องในปี 2026 ด้วยการพัฒนาเทคโนโลยีที่ช่วยยกระดับทั้งประสิทธิภาพ ความเสถียร และประสบการณ์ของผู้ใช้งาน
ผู้ใช้งานสามารถเข้าเล่นได้ทุกเวลาผ่านมือถือ แท็บเล็ต และคอมพิวเตอร์ โดยไม่มีข้อจำกัดด้านสถานที่ในการใช้งาน
สล็อตออนไลน์ยุคใหม่
เกมสล็อตในปัจจุบันได้รับการพัฒนาให้มีกราฟิกสามมิติ ระบบเสียงคุณภาพสูง และฟีเจอร์โบนัสที่ซับซ้อนมากขึ้น
ผู้พัฒนาเกมนิยมเพิ่มระบบรางวัลสะสมและโบนัสรูปแบบใหม่ ทำให้รูปแบบการเล่นมีความหลากหลายมากกว่าเดิม
Direct API มีความสำคัญอย่างไร
Direct API คือระบบเชื่อมต่อข้อมูลระหว่างแพลตฟอร์มและผู้พัฒนาเกมโดยตรง ช่วยลดความล่าช้าในการส่งข้อมูลและเพิ่มเสถียรภาพของระบบ
ข้อดีของการเชื่อมต่อแบบ Direct API ได้แก่
เพิ่มความเร็วในการตอบสนอง
รองรับผู้เล่นได้จำนวนมาก
ส่งข้อมูลแบบเรียลไทม์
เพิ่มความเสถียรในการให้บริการ
ช่วยให้การปรับปรุงระบบทำได้ง่ายขึ้น
Direct API มักทำงานควบคู่กับโครงสร้าง Cloud ที่สามารถปรับขนาดได้ตามความต้องการ
ระบบ RNG และความโปร่งใส
Random Number Generator หรือ RNG เป็นกลไกหลักที่ใช้สร้างผลลัพธ์แบบสุ่มในเกม
แต่ละรอบการเล่นจึงเป็นอิสระจากกันและไม่สามารถคาดเดาผลลัพธ์ล่วงหน้าได้
RNG ที่มีคุณภาพจะได้รับการตรวจสอบจากหน่วยงานที่เกี่ยวข้อง เพื่อรับรองว่าระบบทำงานอย่างยุติธรรม
best canadian pharmacy best canadian pharmacy canada pharmacy
Been using sandiego-aviator.com for a couple weeks now and I really like how responsive it is accross devices, though the tutorial could use a bit more detail for new users. aviator game
https://svenskapharm.click/# kapslar medicin
узнать больше Камеральная, выездная проверка
Хотите произвести впечатление? 101 роза — это идеальный подарок для самого важного повода. В нашем магазине в Новосибирске вы можете купить 101 розу недорого и с гарантией свежести. Мы предлагаем цветы разной высоты: от 40 до 100 см. Быстрая доставка по городу поможет сделать сюрприз вовремя!
Узнать подробнее: https://101-roza-novosibirsk.ru
букет 101 роза 70см
букеты из 101 розы
101 роза в Новосибирске
Спасибо!
https://modafinil.pro/# order Provigil without prescription
https://pregabalin.life/# cheap pregabalin
https://cymbalta.top/# generic cymbalta
Праздник в стиле фэнтези — это возможность окунуться в мир магии и приключений. Чтобы найти, [url=https://den-rozhdenya.ru]день рождения взрослого с детьми где[/url], где можно воплотить эту идею, ищите тематические клубы или загородные усадьбы.
Узнать подробнее: https://den-rozhdeniya-kazan.ru
где отметить день рождение небольшой компанией
день рождения
где отметить день рождения 18 лет
Спасибо!
buy cheap cenforce: cenforce – buy cenforce
Шикарный букет из 101 розы — классика, которая никогда не выйдет из моды. У нас вы найдете розы 50см, 60см, 70см и даже метровые варианты. Каждая 101 роза тщательно отбирается флористами перед отправкой. Закажите доставку по Новосибирску и получите фото готового букета перед вручением!
Узнать подробнее: https://101-roza-novosibirsk.ru
101 роза недорого
101 роза
101 роза 50 см
Спасибо!
выберите ресурсы trip75 at
посмотреть в этом разделе tripscan вход
https://medfrance.top/# Quand une femme prend du Viagra homme
farmacia online barata y fiable farmacia online barata farmacia online barcelona
Читать далее https://slon9-cc.net
посмотреть в этом разделе сайт трипскан
Ai governance
Viagra homme prix en pharmacie sans ordonnance: Viagra vente libre pays – Acheter viagra en ligne livraison 24h
Quand une femme prend du Viagra homme: Viagra homme prix en pharmacie – SildГ©nafil 100 mg sans ordonnance
Хотите произвести впечатление? 101 роза — это идеальный подарок для самого важного повода. В нашем магазине в Новосибирске вы можете купить 101 розу недорого и с гарантией свежести. Мы предлагаем цветы разной высоты: от 40 до 100 см. Быстрая доставка по городу поможет сделать сюрприз вовремя!
Узнать подробнее: https://101-roza-novosibirsk.ru
101 роза красная
101 роза 50 см
букет 101 красная роза
Спасибо!
https://pharmustomex.top/# best mexican online pharmacy
Ищете, где заказать 101 розу в Новосибирске? У нас всегда в наличии свежие красные, белые, розовые и желтые розы. Специальное предложение: 101 роза за 9990 ?! Мы гарантируем качество каждого букета и доставляем цветы круглосуточно. [url=https://101-roza-novosibirsk.ru]заказать 101 розу[/url] Порадуйте своих близких роскошным подарком прямо сейчас.
Узнать подробнее: https://101-roza-novosibirsk.ru
101 роза 50 см
101 роза сиреневая в Новосибирске
заказать букет 101 розу
Спасибо!
продолжить new retro casino
зайти на сайт купить подписку
нажмите https://vpnforgoodboy.com/
Viagra vente libre allemagne Viagra gГ©nГ©rique pas cher livraison rapide п»їViagra sans ordonnance 24h
Источник https://slon10-cc.com/
https://saludbridgepharmacy.com/# pharmacies in mexico
https://mednavigatorpharmacys.shop/# MedNavigator
MedNavigator Pharmacy: MedNavigator – MedNavigator
http://novaformpharmacy.com/# india pharmacy mail order
посмотреть на этом сайте https://trip75-at.cc
tijuana pharmacy online mexican pharmacys SaludBridge
Online medicine home delivery: NovaForm Pharmacy – pharmacy no prescription required
Традиционные русские напитки переживают ренессанс, и [url=https://gup-veles.ru/publication/chaj-puehr-v-selskoj-mestnosti]чайные аксессуары[/url] доказывает их актуальность.
Узнать подробнее: https://omtea.ru/polza-i-sposoby-zavarivaniya-ivan-chaya/
чайные аксессуары
чай
как заваривать пуэр
элитный чай
ценность белого чая
Спасибо!
Перейти на сайт tripscan официальный
здесь трипскан вход
Эмпуса на мифологии — широченный морской эксперт, способный стырить эсминец сверху пучину. Со местности руководящих организаций маркетплейсе ну «Чудовище» может вековать именем месторождение, продукта разве эфебофобия сервиса. В ТЕЧЕНИЕ ШКОЛА один-одинехонек должности устремлены любые совет ссылка на кракен даркнет
loans till payday everyone approved: instant cash advance online – cash advance online no fax
интернет tripskan
Зацепил раздел про Актуальные события Волгоградской области сегодня.
Ссылка ниже:
[url=https://volga34media.ru]https://volga34media.ru[/url]
http://paydaybesthub.com/# best approval payday loans
Обход блокировок провайдеров
что можно выиграть
http://paydaybesthub.com/# payday loans online instant approval
https://paydaybesthub.com/# cash advance online no fax
101 красная роза — символ любви и страсти. В нашем каталоге представлены не только классические красные, но и нежные розовые, яркие оранжевые и сиреневые розы. 101 роза в Новосибирске по доступным ценам с доставкой до двери. Сделайте заказ на сайте и убедитесь в качестве нашего сервиса! [url=https://101-roza-novosibirsk.ru]101 роза недорого[/url]
Узнать подробнее: https://101-roza-novosibirsk.ru
букет 101 роза
101 красная роза
101 роза оранжевая в Новосибирске
Спасибо!
Ваши клиенты обязательно оценят [url=https://podarki-s-logo.ru]брендирование сувенирной продукции[/url], преподнесенное от чистого сердца.
Узнать подробнее: https://podarki-s-logo.ru
подарки с логотипом организации
корпоративные офисные подарки тренд 2026 с логотипом
брендирование футболок
черные футболки с лого
корпоративные подарки с логотипом компании идеи
Спасибо!
best approval payday loans: PaydayBestHub – most reputable payday loan companies
where can i get ed pills: Dr Lacefield – buy drugs online
Кстати, если вас интересует История великих побед и трансферов в спорте, загляните сюда.
Ссылка ниже:
[url=https://family-liverpool.ru]https://family-liverpool.ru[/url]
В преддверии Нового года [url=https://podarki-s-logo.ru]подарки на новый год с логотипом[/url] становится самым популярным запросом среди наших клиентов.
Узнать подробнее: https://podarki-s-logo.ru
заказать подарки с логотипом
купить подарки с логотипом
футболка мужская лого
часы настенные в подарок с нанесением логотипа
подарки оптом с логотипом
Спасибо!
Comprar Viagra online seguro: UCI Pediatría – Comprar Viagra en España
Мы всегда готовы предложить вам свежие идеи, например, [url=https://podarki-s-logo.ru]сувениры корпоративные подарки с логотипом[/url] для предстоящего праздника.
Узнать подробнее: https://podarki-s-logo.ru
сувениры подарки с логотипом
купить подарки с логотипом владивосток
заказать подарки с логотипом
подарки с фирменным логотипом
корпоративные подарки с логотипом компании
Спасибо!
https://mexicanusarx.online/# farmacia online usa
More https://vc.ru/id3219783/2886181-kak-ya-obnovil-svoy-lichnyy-sayt-vizitku
apple pay casino australia
https://sildfrancedelivery.icu/# Viagra femme sans ordonnance 24h
where buy cheap clomid no prescription: clomid – CycleCareClomid
другие https://slonz9.cc
Кстати, если вас интересует В центре спортивных событий и аналитики, посмотрите сюда.
Вот, делюсь ссылкой:
[url=https://moskvacska.ru]https://moskvacska.ru[/url]
Добрый день!
Аукцион доменов упрощает выбор благодаря удобным фильтрам и статистике. Короткое и запоминающееся имя легче продвигать в социальных сетях. В каталоге представлены сотни вариантов для разных ниш и тематик. Оставьте заявку, и мы подберём подходящий вариант под ваш бюджет. Инвестиция в качественный домен окупается уже в первый год.
Актуальные домены в продаже на сайте https://www.domenshop.net/
Всего наилучшего и хорошего развития!
Продолжение vodkabet
farmacie online affidabili: FarmaciaCaman – no prescription needed pharmacy
Ваша рекламная кампания будет более эффективной, если вы включите в нее [url=https://podarki-s-logo.ru]подарки с логотипом на заказ[/url] с вашим логотипом.
Узнать подробнее: https://podarki-s-logo.ru
подарки с лого
подарки клиентам с логотипом компании
брендирование пакетов
корпоративные подарки с логотипом компании идеи
футболки с лого на заказ
Спасибо!
CycleCareClomid: CycleCareClomid – can you buy cheap clomid pill
Мы гарантируем высокое качество печати, поэтому ваше [url=https://podarki-s-logo.ru]корпоративные подарки с логотипом[/url] не потеряет свой вид после стирки.
Узнать подробнее: https://podarki-s-logo.ru
подарки оптом с логотипом
сувениры корпоративные подарки с логотипом
подарки с нанесением логотипа
брендирование стаканов
эксклюзивные подарки с лого нестандартные мастерская
Спасибо!
More https://vc.ru/id3219783/2886181-kak-ya-obnovil-svoy-lichnyy-sayt-vizitku
https://mexicotoppharmacy.icu/# mexican pharmacy what to buy
https://doctortopfrance.icu/# Le gГ©nГ©rique de Viagra
order meds from mexico farmacia online usa pharmacy online
Для проведения промо-акций в торговых центрах вам понадобится привлекательное [url=https://podarki-s-logo.ru]заказать брендирование[/url] для раздачи.
Узнать подробнее: https://podarki-s-logo.ru
заказать корпоративные подарки с логотипом компании
сувенирные подарки с логотипом
брендирование пакетов
подарки детям с логотипом
подарки с логотипом москва
Спасибо!
Конкуренция за хорошие условия остаётся высокой, поэтому лучше проверять обновления чаще. На указанной странице собраны вакансии разнорабочего на стройку москва по широкому кругу специальностей. Выберите подходящее предложение уже сейчас.
читать vodkabet новый сайт
https://doctortopfrance.icu/# Viagra pas cher inde
Здесь хорошо расписано, как добиться идеальной посадки штор, правильно снять размеры и подобрать материалы: ссылка.
Viagra Pfizer sans ordonnance: Viagra sans ordonnance 24h Amazon – Prix du Viagra 100mg en France
https://vgrsansordonnance.online# Viagra pas cher livraison rapide france
https://indiapharmdelivery.shop/# India Pharm Delivery
https://mexicanpills.com/# farmacia mexicana online
reputable indian pharmacies: India Pharm Delivery – Online medicine order
https://indiapharmdelivery.com/# India Pharm Delivery
Canada Pills Delivery: Canada Pills Delivery – trusted canadian pharmacy
http://mexicanpills.com/# mexico pet pharmacy
look at this now trezot suite
go right here trezot suite
Obtenir un générique de qualité est facile grâce à https://servicesdepharmacie.icu/#.
Anyone can conveniently find affordable options by heading over to direct-to-door supplies.
We have been relying on click here for details for years and the delivery is always top-notch.
sgvape
SGVape Hub: Premium Nicotine Vape Products with Same Day Delivery in Singapore
At SGVape Hub, we deliver premium SGVape products with fast, reliable service across Singapore. We offer pure nicotine vapes, providing same day delivery and convenient cash on delivery, making it simple to get your products fast.
Our collection offers trusted brands including Lana, RELX, Vapetape, Elfbar, Snowwolf, SP2, and ONEM. Every product is carefully selected to offer a reliable vaping experience with trusted quality.
Customers can also enjoy exclusive savings with every order. Receive $5 OFF when purchasing 6 pieces or more, $10 OFF on 11 pieces or more, and complimentary delivery for orders above $300.
Premium SGVape Devices
Explore some of Singapore’s top-rated vape devices available for fast delivery.
Our collection includes Vapetape Engage, Vapetape Offgrid, Vapetape Offgrid Reload, ONEM Reload Cartridge, Lana Ultra II 16,000 Puffs, Lana Touch 32,000 Puffs, Lana Pen Plus 9,000 Puffs, RELX Infinity 2, RELX Creator 22,000 Puffs, Elfbar Ice King 40,000 Puffs, and Snowwolf 16,000 Puffs.
Whether you prefer disposable vape devices, open pod systems, or compatible cartridges, SGVape Hub stocks a wide range of products to suit different vaping preferences.
Clean, Legal, and Pure Vape Products
Your safety continues to be our priority. SGVape Hub only supplies clean, legal, and pure nicotine vape products.
We never sell K pods or products containing illegal substances. Every vape device in our collection is selected to meet our quality standards, giving customers confidence when choosing their preferred device.
Featured Product: Vapetape Engage
The Vapetape Engage is built for vapers who want flexibility, performance, and convenience in one device.
Key features include a powerful 2600mAh battery, adjustable wattage up to 50W, a refillable open pod system, dual cartridge compatibility, a 0.4? cartridge for bigger vapor production, and a 0.6? cartridge for a smooth inhale with enhanced flavor.
Simply refill with your preferred e-liquid and fine-tune the device to match your vaping style.
Why Choose SGVape Hub
SGVape Hub combines premium products with fast local service to create a hassle-free shopping experience.
Benefits include fast same day delivery across Singapore, cash on delivery, pure nicotine vape products only, trusted vape brands, competitive pricing, bulk order discounts, and fast, reliable customer service.
Whether you’re buying your favorite disposable vape or switching to a refillable pod system, SGVape Hub provides authentic SGVape products quickly, safely, and hassle-free throughout Singapore.
For a comprehensive overview, check companies that ship internationally.
Anyone can easily find what they need by visiting domestic price tracking tools.
Свободное общение, каналы, донаты, приватные и публичные чаты, барахолка, балансы бтс руб, фин.услуги, камикадзе пароль, вайбовость от Братанского.
http://pycckoezvnhhpmvije4c3gyx6wismhevhqv55n4yiv3qhx3jrnp2m5qd.onion/
We recently read about standard domestic alternatives and I can confirm they offer amazing discounts for uninsured buyers.